-
获取 T-n 工作日 日期解决方案
2018-11-26 10:51 -
【SAP】四种方式筛选特别总帐标志既含 A 又含空的科目
2018-11-26 10:46重视效率,这就是精益求精的代表, 👍
-
三种判断 nan 类型的方法
2018-11-23 13:11👍 👍 👍
-
三种判断 nan 类型的方法
2018-11-23 10:09pandas 直接有方法,不用转换到 list 或者 numpy 吧
df[df['fields'].isnull()]来获取是 nan 的
或者df[df['fields'].notnull()]来获取不是 nan 的,
这样比较简化,也节省了 df 转到 list 的时间 -
2018-11-22 10:58 破解极验滑动验证码
破解极验滑动验证码
的确厉害,想用,想做伸手党,哈哈
后面做个工程教程板块,放些大家完整作品,等到 9.0 加入 studio 浏览并下载运行就用户体验极佳了 -
选择框的变更触发
2018-11-21 12:45其实这个问题,各位专家都遇到不少,都解决了,下次记得下一下就好
-
🎉🎉 艺赛旗 iS-RPA 社区“知识专家组”成立,期待你的加入!
2018-11-21 12:35👏
等这一天等了太久了,这个论坛需要你们!加油! -
选择框的变更触发
2018-11-21 10:53这个挺麻烦的,没这个页面的账号和这种类型的页面,你测试不出效果,但是这个做法,因为模拟人工,是遇到类似问题的通用做法
-
如何安装 rarfile 库
2018-11-21 10:38Python 的包当中,分成原生和 wrapper(包装)
原生的 pip 即可,wrapper 需要按照原始的软件包,有时候 wrapper 也是带外部原始软件包的
比如 rarfile,我查了一下,他说明如下:
Features:- Supports both RAR3 and RAR5 format archives.
- Supports multi volume archives.
- Supports Unicode filenames.
- Supports password-protected archives.
- Supports archive and file comments.
- Archive parsing and non-compressed files are handled in pure Python code.
- Compressed files are extracted by executing external tool: either
unrarfrom RARLAB orbsdtarfrom libarchive.
就是说他内置了 unrar 和 bsdtar 的,只是不知道他安装到 site package 目录的哪里了,复制 lib 的时候,没复制这个 unrar 应该是之前不成功的主要原因
-
EXCEL 处理 ---pandas DataFrame 专题
2018-11-19 10:33DataFrame 的内置方法 >apply> 遍历
如果你要处理 10 万 + ~ 100 万 + 的数据,效率差异巨大, 如果你要处理数百条数据,那么哪种都行
大家好好学,经常能用到 -
鼠标减速拖动
2018-11-19 10:31不明觉厉啊
-
提升 pip 工具的下载速度
2018-11-13 16:50我曾经珍藏过一个奇快的网站,就在这分享给大家吧,不知道全不全
pip3 install xlwings -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com -
pandas 数据生成 excel 表格时,数据会转换成文本数字的解决办法
2018-11-12 10:28我还知道一种方法
df[0]=df[0].apply(str, axis=1) # axis=1 表示按列 -
Pandas 数据表格删除符合条件的行的方法
2018-11-09 15:09df = df[df['产品代码'].str.contains("wj")]另外 DataFrame 千万不要遍历
你可以这样:def line_has_wj(row): if 'wj' in row['产品代码']: return 1 else: return 2 df['if_wj']=df.apply(line_has_wj`, axis=1`) df = df[df['if_wj']==1]当然方式 1 最佳
方法二我未验证,可以自己验证下
Dataframe 中, 系统自带方法 >apply> 遍历 -
关于 7.0 设计器流程描述消失的问题
2018-11-09 14:10我测试了一下,都可以保存
注意一下,这里一保存,会跳转到项目的属性那边
每个流程都有自己的属性,很容易搞混 -
窗口检测错误
2018-11-08 22:408.0 版本会首先尝试将元素带到可见区域,滚动条问题 8.0 解决,大约 12 月发布
-
窗口检测错误
2018-11-06 10:31看看个人电脑的安全软件关闭一下,或者试试管理员身份运行
-
求离线版 7.0 设计器参考手册
2018-10-30 15:10现在没有离线版手册,请使用手机看一下
-
工程通用移植性问题解决设想
2018-10-29 11:19内置浏览器主要弱点是浏览器适配能力的问题
另外移植性不强从来不是浏览器问题,是图片点击问题,这个问题,内置浏览器无法解决 -
如何获取和编制 EXCEL 表格的样式
2018-10-26 15:07推荐使用一个模版,格式都排好了,然后用 xlwings 填充数据即可
xlwings 可以设置或者读取颜色,但是更加详细的设置例如边框等似乎是不行的。
如果你一定要做细节设置,建议采用 excel 本身的按钮和快捷键,现在那些按钮应该可以拾取了。
还有一种方式是采用 vb 设置宏来实现。
我觉得机器人没必要做细节排版,那种精细活要人来做的。 -
RPA7.0- 设计器使用优化建议 -20181023
2018-10-24 15:161,主题属于锦上添花的东西,工作量极大,这个建议是不错的,但是要放在比较后面实现了
2-3、线条不易选择在 8.0 可以按住 ctrl 拖拽范围选择,不过单独选择也争取优化一下
4、看看 8.0 是否来得及优化,来不及就放 9.0
5、8.0 先做对齐,这个后续有时间再做
6、记录暂不修改
7、8.0 提供锁定、并提供单独按钮、快捷键、收藏等,其他后续继续优化
8、此问题修改难度较大,后续修改
9、争取 8.0 修改,对多种字段,根据内容多少进行优化
10、搜索争取支持全局函数,后续增加
11、8.0 增加快捷方式中断运行 -
控件的注释
2018-10-23 21:33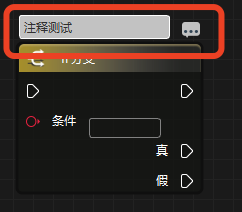
这个不是吗?
-
运行日志信息输出到文本
2018-10-22 13:44可以的,你看编译出来的代码,很多地方都有个:
self.__logger.debug(' "StepNodeTag:18152309380",Note:')
你也可以调用self.__logger.debug或者 info、warning、error 来输出日志,把单引号中间内容替换为你自己需要的打印的字符串,注意,需要字符串
日志会输出到c:\logs和安装目录\logs
注意大量的打印信息会导致 logs 文件过大,可以参考这里当然你可以自定义一个 logger,用你自己的文件来记录自己的日志,可以百度一下
-
对 7.0 设计器的建议
2018-10-22 10:521-2、word 和 pdf 组件由于需要理解 word 和 pdf 结构(大部分人不理解),因此加了也不能直接用的,不过这个可以先记录,后续某个版本添加
3、组件优化 8.0 已做,支持锁定菜单、收藏组件和常用组件
4、自动连线可以用拖出出口线到空白处 - 指定组件来完成
5-6-7、我们记录一下,合适的版本,优化一下
8、自动布局难度较大,你看 ppt 和 visio 给你自动布局吗,不过这个是我们想做的,估计一时半会做不出
9、这个我们无法判断是字符串还是变量的,我们后续会主动提示错误,比如‘变量不存在’这样来避免用户这种错误,错误提示这个后续版本安排
10、我们会在 8.0 增加区域选择,我们考虑下 ctrl-a
11、我们考虑 8.0 增加专门的中断按键,8.0 工作量较满,不知能否安排的下其实并非我不允许你提意见,而是提意见要充分考虑可行性、收益问题,不能用户提了就转过来,要思考、搜索、分析,经过提炼的意见才是精华,如果未加过滤,那么大部分意见和建议都是价值不高的,这几次意见都提的不错,意见提的好不好,并不因为是用户提的还是你提的,而是因为你思考过了,对别人有很大价值。
-
如何获取各类日期的属性比如工作日节假日。
2018-10-21 21:30如果你说的是周六、日这种,只要使用
datetime.datetime.today().weekday()这类的函数来判断是否周六周日。如果是其他国家法定节假日,我国都是不固定会调整的,肯定自动算不出啦,网上有一些 api 可以提供查询,没测试过准不准。 -
流程配置中的 python 小知识点
2018-10-21 14:15真心实用,值得收藏
-
RPA 软件与按键精灵功能和设计原理上有什么区别?
2018-10-21 10:40基本原理一致,模拟人嘛,我们前期设计产品也了解过按键精灵嘛,但差异也很大
- 按键精灵毕竟为游戏服务的,很多多查找颜色啊,定位小地图这类工作,我们比较多针对浏览器啊、控件这类东西
- 按键精灵设计理念太老化了,便捷性和实用性也不足
- 按键精灵基本也是以 vb 为主(我们大部分竞争对手也是 vb 为主),其实按键精灵和 aa 产品很像的,扩展性和数据处理能力不足
- 如果有兴趣,可以按照售前厂商比较表格,一项项填写下哪些按键精灵支持,哪些不支持
你现在可以随便找一个自己实现的流程,用按键精灵实现一下,看看难度、支持程度和要多久实现
-
suse 版本安装 csm
2018-10-12 11:57最好编辑到帖子里面,不然不便于搜索
-
鼠标点击的优化建议
2018-10-11 11:508.0 考虑
linping
- 6 标签
- 66 帖子
- 386 回帖

上传 demo 工程是个好习惯,大家学习一下,测试一下
双休可以用 weekday 计算,但是如果这样计算,调休需要额外考虑