


三种判断 nan 类型的方法
我们在使用 pandas 读取表格中的空单元格时,获取到的是 nan 类型。
对于这种类型,可以用 numpy 中的 isnan() 方法来判断,另外,也可以将其转换为字符串再判断其是否是字符串 "nan"。
我直觉一直认为类型判断会比先转换为字符串再判断要快一点,为了验证这个想法,分别在十秒钟循环执行两种操作,然后观察执行次数,次数越高说明执行速度越快。代码如下:
import pandas as pd
import numpy as np
import time
path = r'C:\Users\lenovo\Documents\SAP\SAP GUI\2620 1.XLSX'
df = pd.read_excel(path)
df_list = np.array(df).tolist()[0][0]
start_time1 = time.time()
n = m = 0
while True:
now_time = time.time()
if np.isnan(df_list):
n += 1
else:
n += 1
if now_time - start_time1 > 10:
break
else:
continue
print('十秒内用numpy类型判断的次数:',n)
start_time2 = time.time()
while True:
now_time = time.time()
if str(df_list) == 'nan':
m += 1
else:
m += 1
if now_time - start_time2 > 10:
break
else:
continue
print('十秒内转化为字符串再判断的次数:',m)
运行结果如图所示: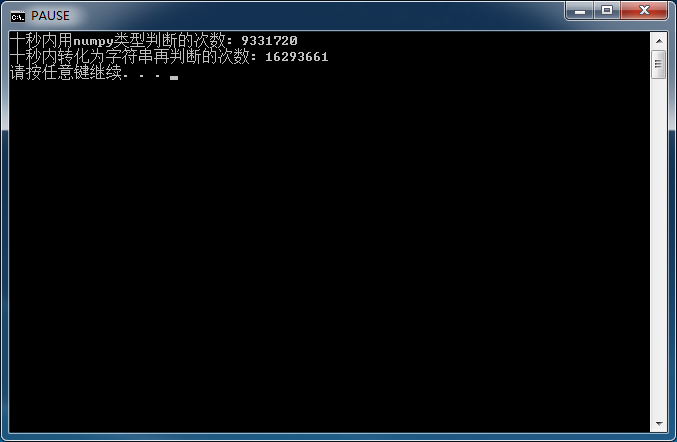
我们分别看一下两者的字节码指令:
步骤反而是后者多一步,因此可以判断出前者比较慢的原因是在加载 numpy 以及调用 isnan 方法的时候花了较多的时间。
在 @lingping 大佬的提示下,发现用 pandas 自带方法来处理其实空间复杂度更低,我们还是比较一下代码运行时间:
import pandas as pd
import numpy as np
import time
path = r'C:\Users\lenovo\Documents\SAP\SAP GUI\2620 1.XLSX'
n = m = 0
start_time1 = time.time()
while True:
df = pd.read_excel(path)
df_list = np.array(df).tolist()[0][0]
now_time = time.time()
if str(df_list) == 'nan':
m += 1
else:
m += 1
if now_time - start_time1 > 10:
break
else:
continue
print('十秒内转化为字符串再判断的次数:',m)
start_time2 = time.time()
while True:
df = pd.read_excel(path)
now_time = time.time()
if df['已清项目/未清项目符号'].isnull()[0]:
n += 1
else:
n += 1
if now_time - start_time2 > 10:
break
else:
continue
print('十秒内pandas自带方法判断的次数:',n)
输出结果如下:
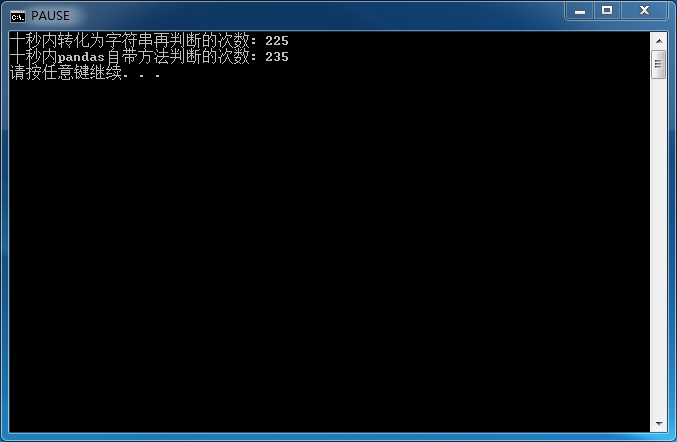
速度基本一样,但还是建议使用 pandas 自带的方法,省去了转化为列表所需要的内存空间。

👍 👍 👍
判断单个单元格还是可以用的吧
pandas 直接有方法,不用转换到 list 或者 numpy 吧
df[df['fields'].isnull()]来获取是 nan 的或者
df[df['fields'].notnull()]来获取不是 nan 的,这样比较简化,也节省了 df 转到 list 的时间