


【SAP】四种方式筛选特别总帐标志既含 A 又含空的科目
在进行月末客户清账的流程设计时,其中一个步骤是导出电子表格或者网页并从中筛选数据。
页面如下: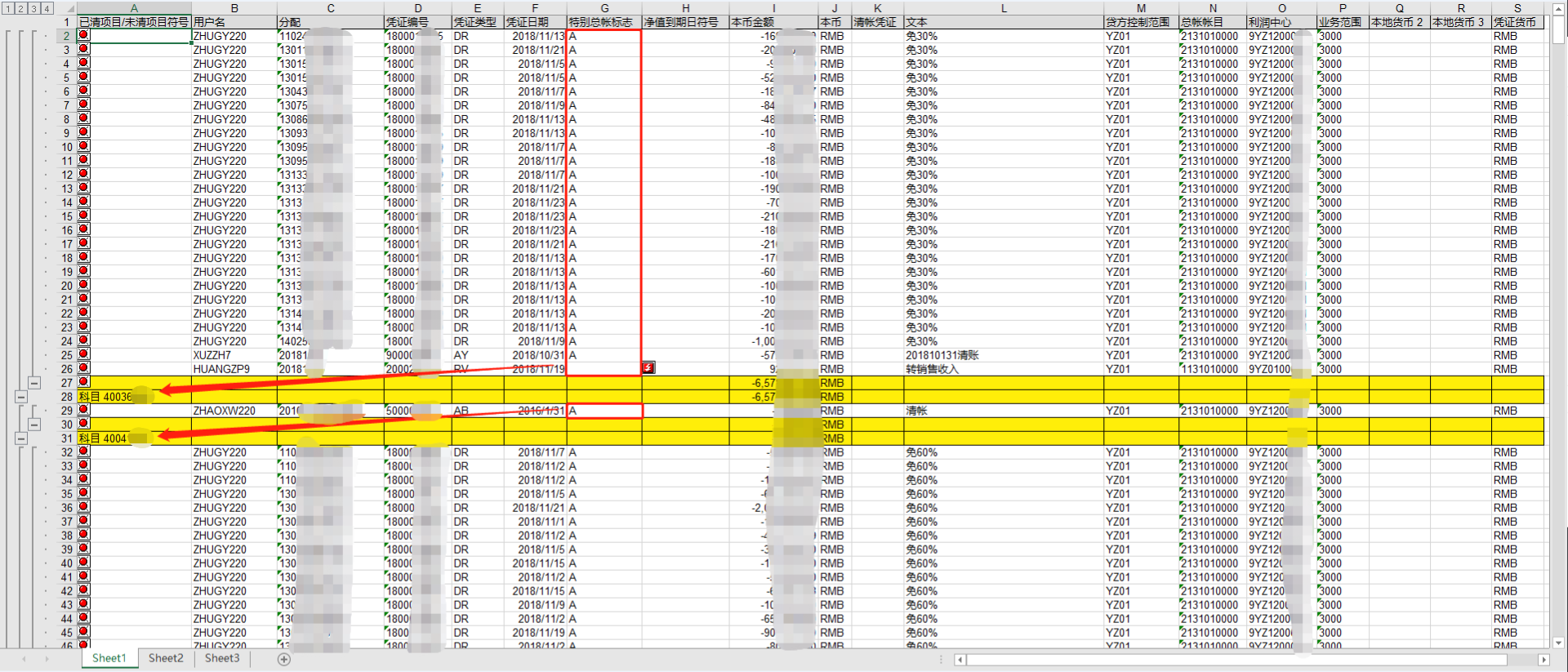
另外,如果是网页格式的文件,用浏览器打开可能是这样的(后缀名为 mhtml):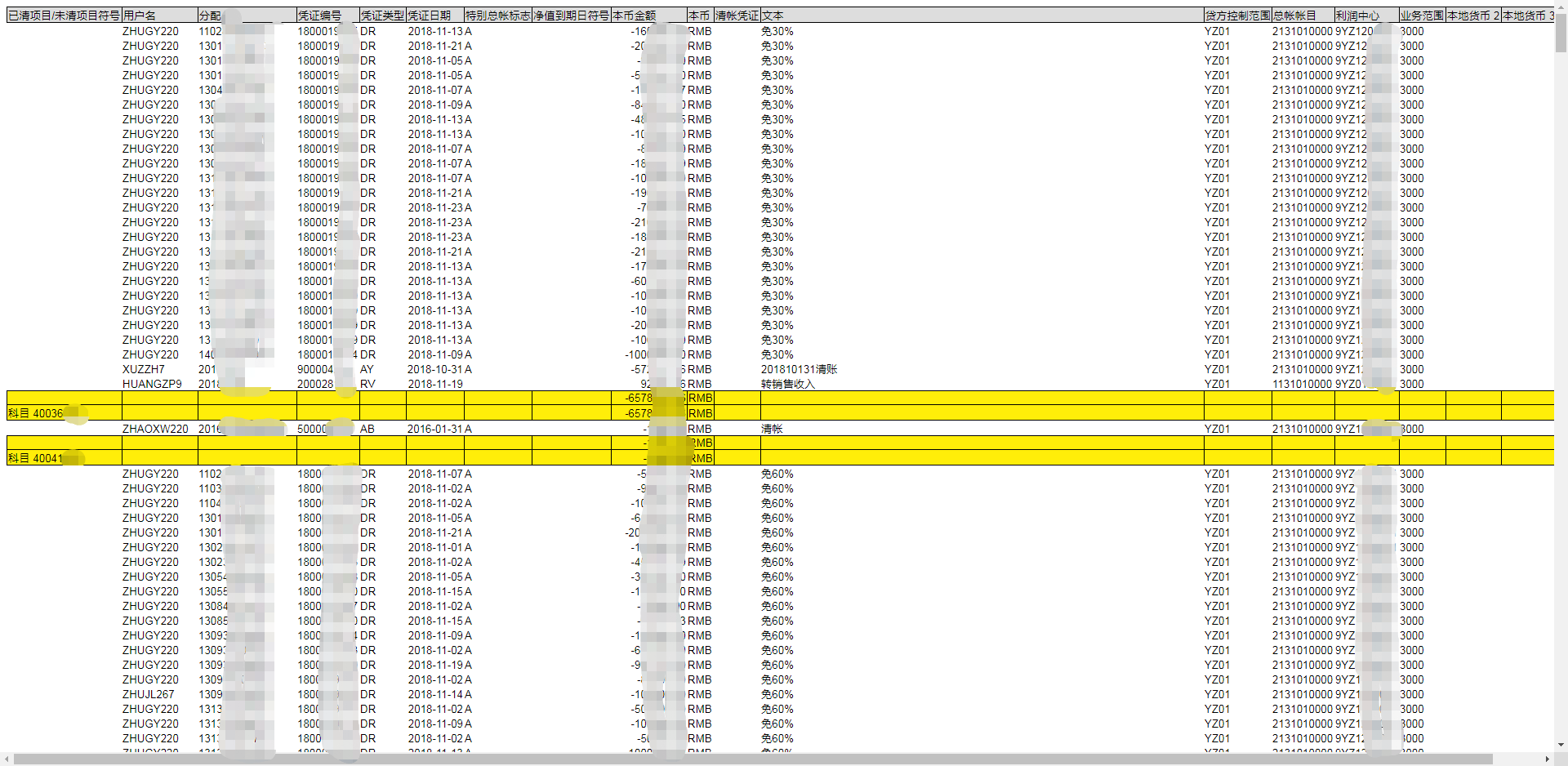
也可能是这样的(后缀名为 htm):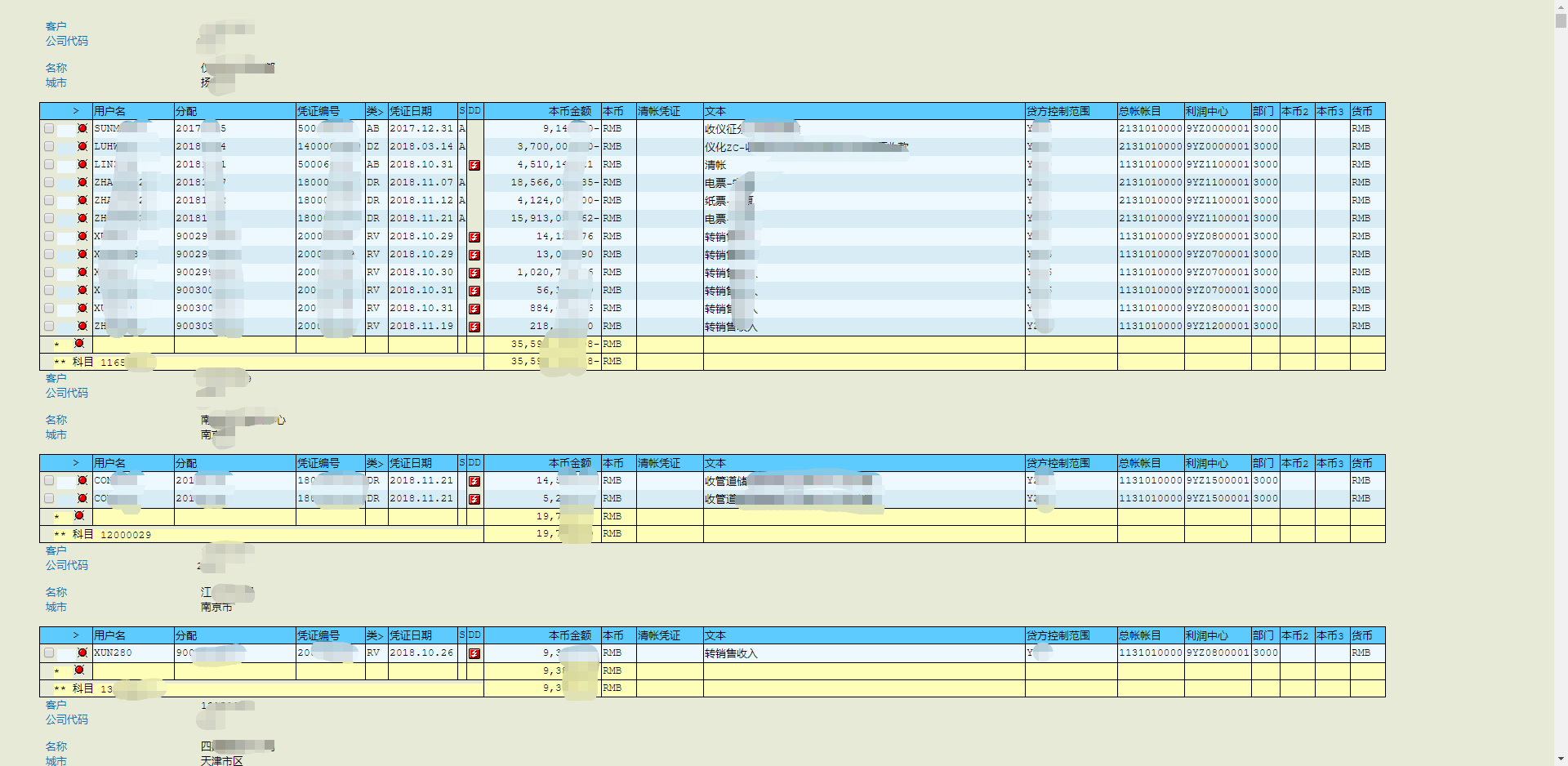
对于红框中的每一个单元格,我们需要判断其中的值,如果红框(上一个黄色行与下一个黄色行中间的那些行)中既有 A 又有空单元格(比如第一个红框中最后一项是空单元格,前面都是 A),那么我们就取箭头指向的科目,如果红框中全是 A 或者全是空则排除那个科目(比如第二个红框中全是 A,就排除箭头所指的科目)
思路
首先读取 "凭证编号" 这一列中的空值,获取所有黄色行所在的索引。然后依次遍历黄色行中间的每一块白色行,将 "特别总帐标志" 中的每一个值放入集合中,对于每一块白色行都判断一下集合的长度,如果为 2 则说明那个科目是我们需要的。
方法一(针对导出的是 xlsx 格式)
import pandas as pd
def parse_excel(path):
df = pd.read_excel(path)
index = df[df[df.columns[3]].isnull()].index[:-1].tolist()
subjects = []
try:
set_index = set()
for x in range(index[0]):
set_index.add(str(df[df.columns[6]].ix[x]))
if len(set_index) == 2:
subjects.append(df[df.columns[0]].ix[index[0] + 1][-8:]) # 这里的-8是因为科目一共为8位数,前面的科目两个字我们不需要
for j in range(1, len(index)//2):
set_index = set()
for x in range(index[j*2-1] + 1, index[j*2]):
set_index.add(str(df[df.columns[6]].ix[x]))
if len(set_index) == 2:
subjects.append(df[df.columns[0]].ix[index[j*2] + 1][-8:])
except:
pass
return subjects
方法二(针对导出的是第一种 mhtml 格式)
import pandas as pd
def parse_html1(path):
df = pd.read_html(path, header=0)[0]
index = df[df['凭证编号'].isnull()].index[:-1].tolist()
subjects = []
try:
set_index = set()
for x in range(index[0]):
set_index.add(str(df['特别总帐标志'].ix[x]))
if len(set_index) == 2:
subjects.append(df['已清项目/未清项目符号'].ix[index[0] + 1][-8:])
for j in range(1, len(index)//2):
set_index = set()
for x in range(index[j*2-1] + 1, index[j*2]):
set_index.add(str(df['特别总帐标志'].ix[x]))
if len(set_index) == 2:
subjects.append(df['已清项目/未清项目符号'].ix[index[j*2] + 1][-8:])
except:
pass
return subjects
方法三(针对导出的是第二种 htm 格式)
前面两种都使用了 pandas 这个第三方库,但是对于第二种有很多个表的网页格式,pandas 就无能为力了,我们只能换一种思路,通过直接获取其 html 源码并将其转换为树结构,这里我们使用 BeautifulSoup 这个库
from bs4 import BeautifulSoup
def parse_html2(path):
with open(path, 'r', encoding = 'utf-8') as html:
soup = BeautifulSoup(html, 'lxml')
tables = soup.find_all('table')
tem_list = []
for table in tables[:-1]:
tbodys = table.find_all('tbody')
tem_set = set([])
for tr in tbodys[1].find_all('tr'):
string = tr.find_all('td')[6].string
tem_set.add(string)
if len(tem_set) == 2:
subject = tbodys[3].find('tr').find_all('td')[0].find_all('font')[2].string[3:11]
tem_list.append(subject)
return tem_list
方法四(针对导出的是第一种 mhtml 格式)
from bs4 import BeautifulSoup
def parse_html3(path):
with open(path, 'r', encoding = 'utf-8') as html:
soup = BeautifulSoup(html, 'lxml')
trs = soup.find_all('tr')[1:-1]
index = []
subjects = []
for i in range(len(trs)):
td = trs[i].find_all('td')[3].string
if td is None:
index.append(i)
# print(index)
set_index = set()
try:
for x in range(index[0]):
set_index.add(trs[x].find_all('td')[6].string)
if len(set_index) == 2:
subjects.append(trs[index[0] + 1].find_all('td')[0].string[-8:])
for j in range(1, len(index)//2):
set_index = set()
for x in range(index[j*2-1] + 1, index[j*2]):
set_index.add(trs[x].find_all('td')[6].string)
if len(set_index) == 2:
subjects.append(trs[index[j*2] + 1].find_all('td')[0].string[-8:])
except:
pass
return subjects
处理网页时 BeautifulSoup 和 pandas 速度对比 (方法二和方法四)
import time
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
path = r'C:\Users\lenovo\Documents\SAP\SAP GUI\4152 70.MHTML' # 总共八千多行数据
def parse_html3(path): # 方法四
time_start = time.time()
with open(path, 'r', encoding = 'utf-8') as html:
soup = BeautifulSoup(html, 'lxml')
trs = soup.find_all('tr')[1:-1]
index = []
subjects = []
for i in range(len(trs)):
td = trs[i].find_all('td')[3].string
if td is None:
index.append(i)
# print(index)
set_index = set()
try:
for x in range(index[0]):
set_index.add(trs[x].find_all('td')[6].string)
if len(set_index) == 2:
subjects.append(trs[index[0] + 1].find_all('td')[0].string[-8:])
for j in range(1, len(index)//2):
set_index = set()
for x in range(index[j*2-1] + 1, index[j*2]):
set_index.add(trs[x].find_all('td')[6].string)
if len(set_index) == 2:
subjects.append(trs[index[j*2] + 1].find_all('td')[0].string[-8:])
except:
pass
time_end = time.time()
print('BeautifulSoup用时{}秒'.format(time_end - time_start))
return subjects
def parse_html1(path): # 方法二
time_start = time.time()
df = pd.read_html(path, header=0)[0]
index = df[df['凭证编号'].isnull()].index[:-1].tolist()
subjects = []
try:
set_index = set()
for x in range(index[0]):
set_index.add(str(df['特别总帐标志'].ix[x]))
if len(set_index) == 2:
subjects.append(df['已清项目/未清项目符号'].ix[index[0] + 1][-8:])
for j in range(1, len(index)//2):
set_index = set()
for x in range(index[j*2-1] + 1, index[j*2]):
set_index.add(str(df['特别总帐标志'].ix[x]))
if len(set_index) == 2:
subjects.append(df['已清项目/未清项目符号'].ix[index[j*2] + 1][-8:])
except:
pass
time_end = time.time()
print('pandas用时{}秒'.format(time_end - time_start))
return subjects
parse_html3(path)
parse_html1(path)
运行结果如下:
经过测试发现 pandas 慢的主要原因是 pd.read_html() 这个函数花了太多时间,因此对于 html 格式的数据尽量还是使用 BeautifulSoup 来处理。

林总过奖了 😂
重视效率,这就是精益求精的代表, 👍
👍🏻👍🏻👍🏻