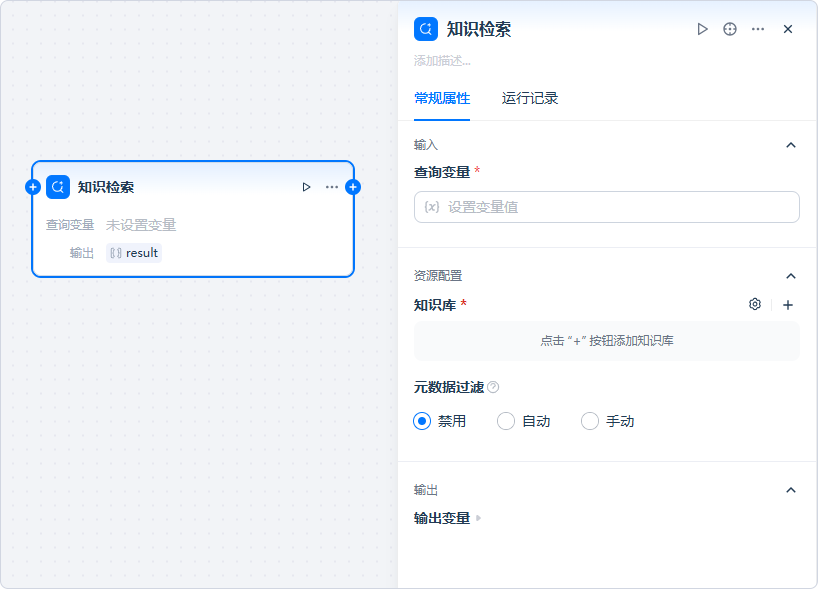
知识检索节点
知识检索节点
【知识检索】节点用于从知识库中检索与用户问题相关的文本分段,并将其作为下游
应用场景
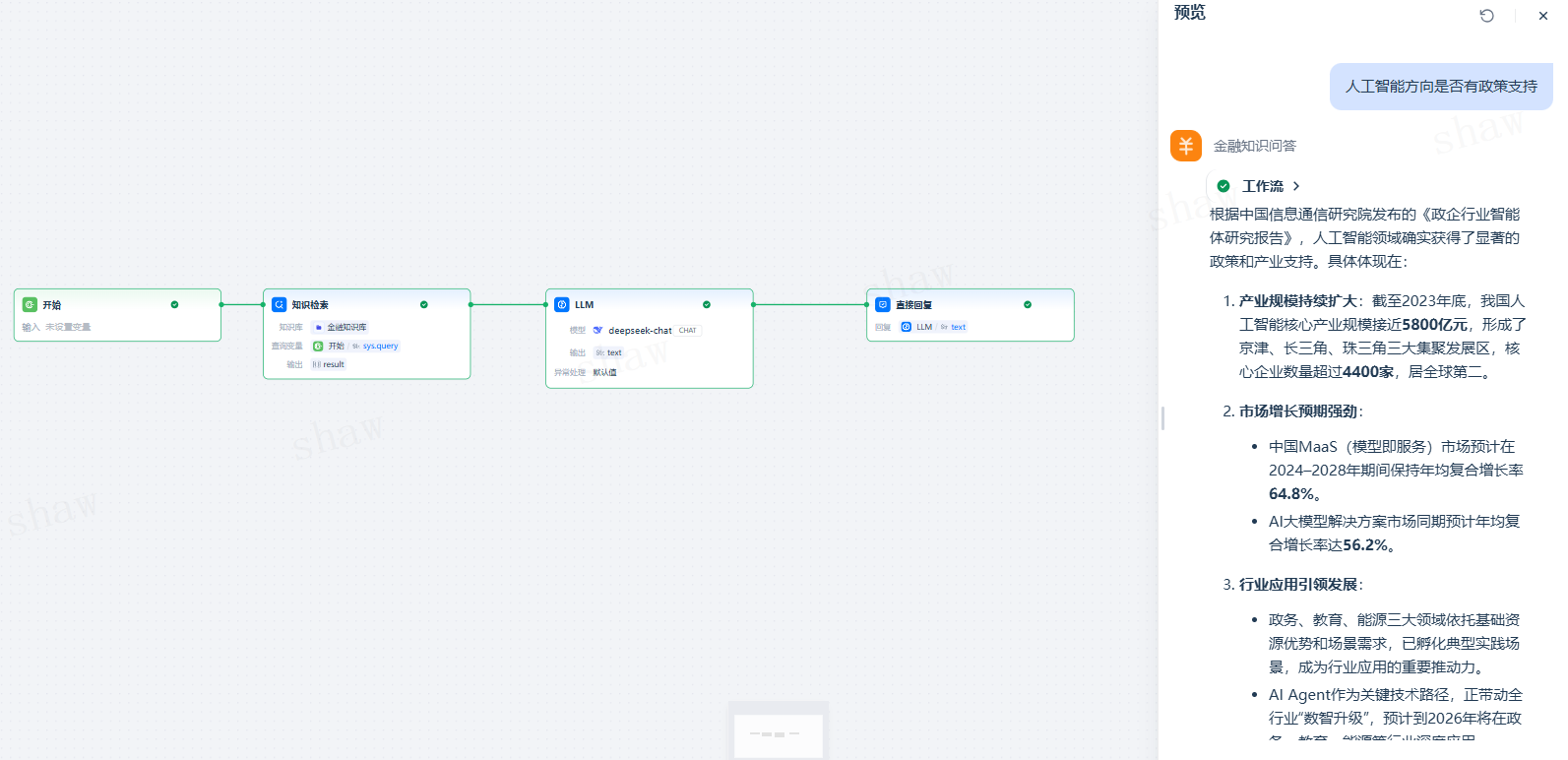
典型用途是构建基于企业文档或外部资料的问答系统(RAG)。常见流程为:
用户问题 → 知识检索(召回相关分段)→ LLM 节点(结合上下文生成回答)。
配置指引
1. 配置流程
选择查询变量
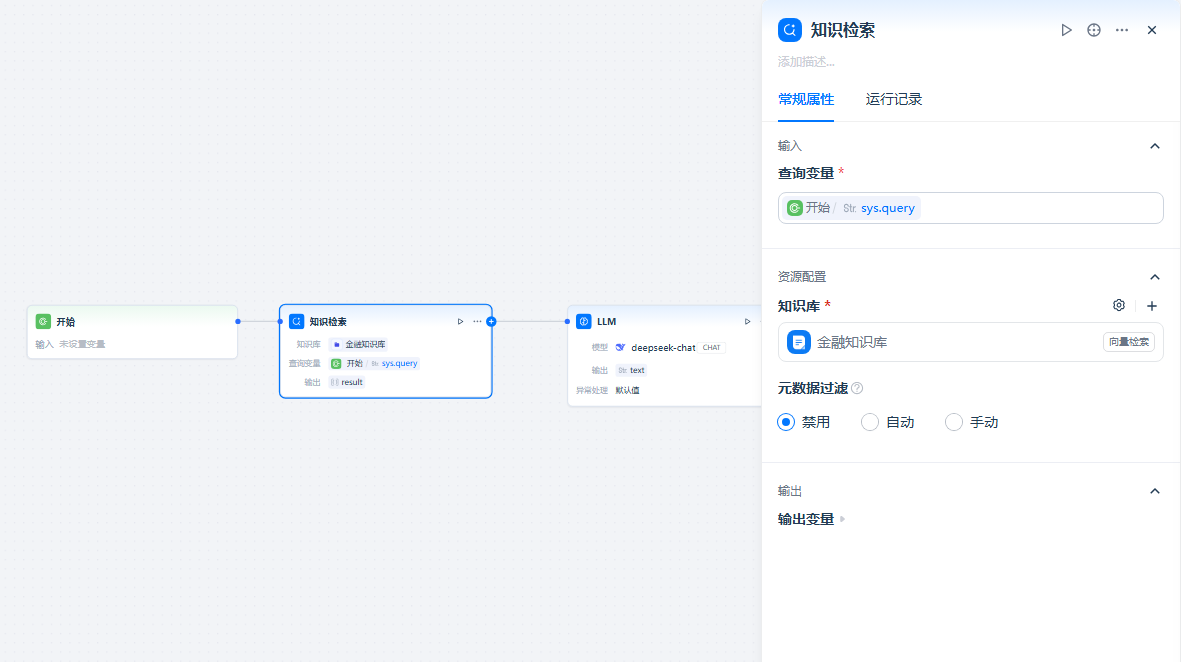
通常选择来自「开始」节点的sys.query作为查询变量(建议长度不超过约 200 字符,以获得更稳健的召回效果)。选择知识库
从已创建并完成向量化的知识库中选择目标库。(确保知识库已在平台内创建并完成文档处理与索引。)配置元数据筛选(可选)
在「元数据筛选」处设置筛选条件(如文档类型、标签、生效日期等),以限定检索范围、提升精度。
元数据的设计与写入需在知识库文档阶段完成;应用侧仅负责筛选。
- 设置召回模式
建议使用 多路召回(如语义检索 + 关键词检索的融合),在多数企业文档场景下较单一路径更稳健。
不再推荐仅使用“N 选 1”式的单一路径召回。
- 连接下游节点
将检索结果传递给 LLM 节点作为上下文变量,完成 RAG 闭环。
2. 输出变量
知识检索节点对外暴露统一的 输出变量:result。其数据结构通常包含:
content:分段文本内容title:来源文档标题url:来源链接或文档标识icon:文档图标metadata:自定义元数据(如标签、生效日期、作者、部门等)
实际字段可能因知识库实现与预处理策略而略有差异,但
content与metadata为最常用字段。
3. 配置下游 LLM 节点
在对话型或流程型应用中,知识检索节点的下游一般为
- 在 LLM 节点的「上下文变量」中选择并绑定知识检索节点的 输出变量
result; - 在提示词中插入该上下文变量,引导模型“仅基于上下文作答/优先基于上下文作答”;
- 结合业务需求设置“不命中处理策略”(如:当
result为空时,回复“未在知识库中找到相关内容”或改走其它分支)。
注意
- 「上下文变量」是 LLM 节点内用于注入外部文本的特殊变量类型。
- 当检索命中时,文本分段会填入上下文变量;未命中时该变量为空,需在提示或分支逻辑中妥善处理。

最佳实践与建议
- 查询规范化:对
sys.query进行必要的清洗或改写(如去除冗余空格、显式化意图),有助于提高召回效果 - 元数据治理:在知识库侧为文档补充充分且一致的元数据(如部门、条线、制度类型、实施日期),为下游筛选提供可控维度。
- 多路召回融合:结合语义检索与关键词检索,并对多路结果做去重与重排,常能显著提升相关性
- 引用与归属:若应用端需要溯源,可在前端或后续节点使用
result中的来源信息进行展示 - 无命中兜底:明确当
result为空时的处理策略(回复模板或改走“人工/搜索/结构化查询”等分支)
与其它节点的配合
LLM 节点 :result→ LLM 的「上下文变量」;提示中明确使用策略与优先级。变量赋值节点 :可将检索出的关键元数据写入会话变量,供后续分支逻辑使用(如基于effective_date做时效过滤)条件分支节点 :根据result是否为空、命中分数、来源库等条件决定走向(如兜底到搜索或人工)