LLM节点
LLM节点
【LLM】 节点用于调用大语言模型的能力,处理来自[开始]节点的输入(自然语言、上传的文件或图片等),并生成可用的输出结果。
它是 对话流智能体 / 工作流 中最核心、最常用的处理节点之一。
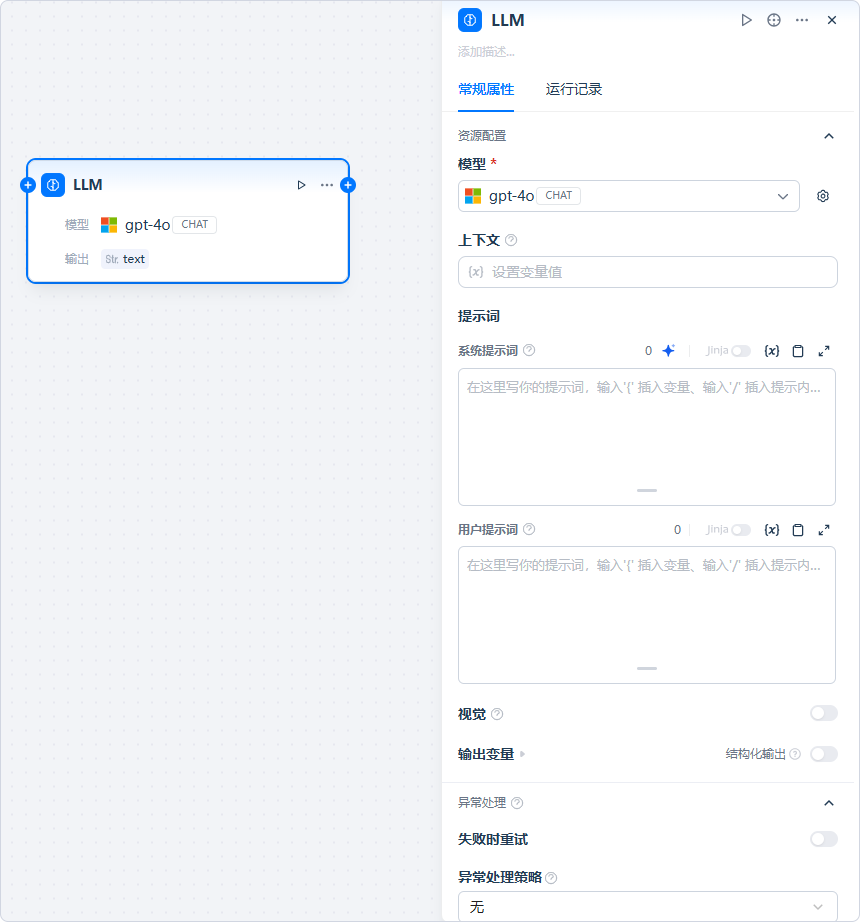
应用场景
- 意图识别:在客服等场景中,对用户问题进行分类,分流至不同分支
- 文本生成:根据主题与关键词生成文章、摘要、标题、报告等
- 内容分类:批量处理邮件或文本,自动归类为咨询 / 投诉 / 垃圾等类型
- 文本转换:翻译、改写、风格迁移、格式转换等
- 代码生成:按需求生成业务代码、单元测试、脚本片段等
- RAG(检索增强生成):结合知识检索结果重组并回答用户问题
- 图片理解:使用具备视觉能力的多模态模型,对图像内容进行解析与问答
只需选择合适的模型并编写提示词,即可在 对话流智能体 / 工作流 中构建可靠的智能处理能力
配置步骤
- 添加节点:在应用编辑页,右键画布或点击上游节点末尾的「+」,选择 LLM。
- 选择模型:AI Center 支持多家主流模型供应商(聊天模型、补全模型与多模态模型等)。选择时可综合考虑推理能力、上下文窗口、响应时延与成本。
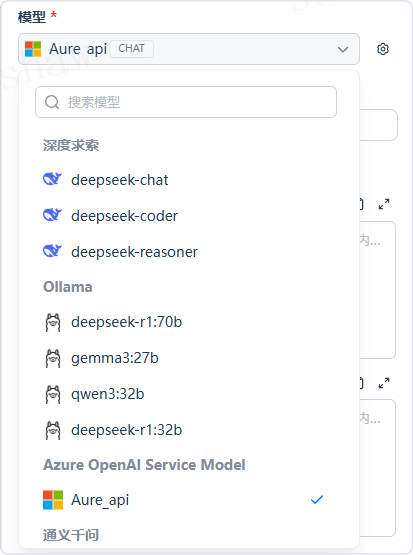
- 配置模型参数:包括温度、Top P、最大标记数、回复格式等。系统通常提供若干参数预设(如「创意 / 平衡 / 精确」)。若需图片理解,请选择具备视觉能力的模型。
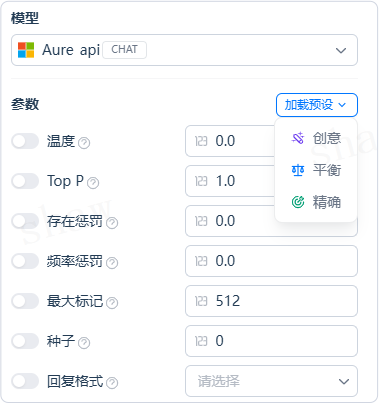
- 填写上下文(可选):为 LLM 提供背景信息,常用于填写上游 知识检索 节点的输出变量(如
result)。 - 编写提示词:
- 选择聊天模型时,支持编排 SYSTEM / USER / ASSISTANT 结构;
- 在提示编辑器中输入 “/” 可插入 变量(系统变量、上游节点输出、会话变量等);
- 可启用 提示生成器,根据业务目标自动生成或迭代提示;
- 可选择 Jinja2 模板 实现轻量逻辑与格式化处理(如循环、条件、拼接等)。
- 高级设置(可选):配置记忆与记忆窗口、开启视觉能力、结构化输出、错误重试与异常处理等。
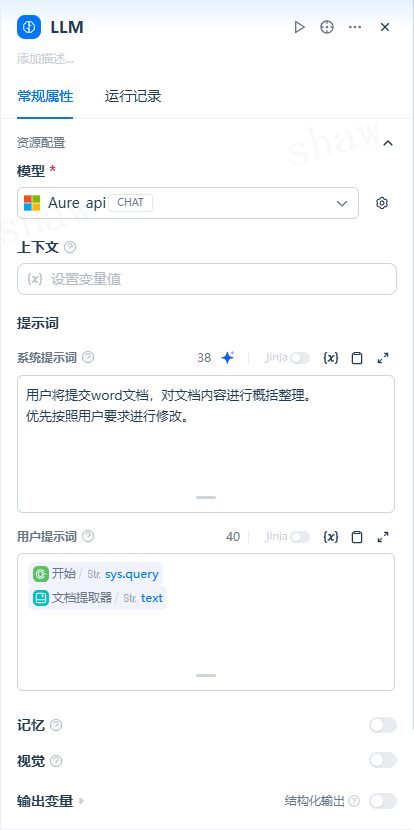
特殊变量说明
上下文变量
用于向 LLM 提供背景信息,RAG 场景下常填写 知识检索节点 的输出(如 result)。
详见:
文件变量
部分多模态模型支持直接读取并分析文件内容(如图片、PDF、Office 文档等)。
在使用文件变量前,请确认所选模型与供应商支持的文件类型与大小限制。
如需在流程中处理文件内容,可结合 文档提取器 或相关工具节点。
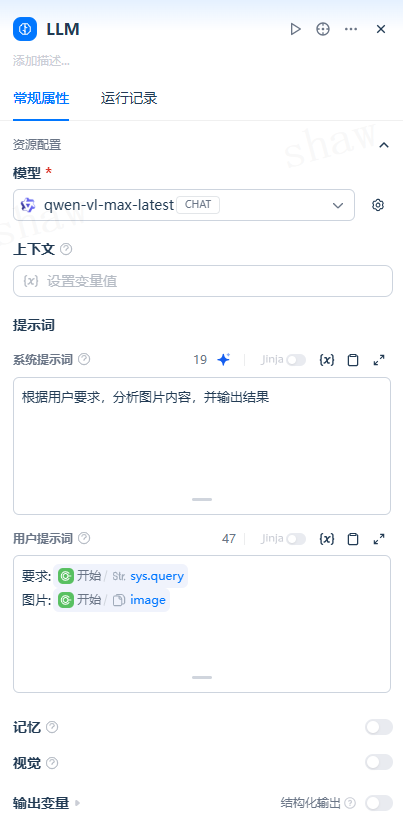
会话历史
当使用补全类模型实现对话能力时,可在提示中插入会话历史变量以维持上下文记忆(仅在对话流智能体中、且选择相应模型形态时可用)。
模型参数(常用)
- 温度(temperature):0–1 控制随机性。越低越稳定可控,越高越有创造性。
- Top P:控制采样多样性,限制候选词累计概率阈值。
- 存在惩罚(presence penalty):降低重复出现过的实体/主题的再次生成概率。
- 频率惩罚(frequency penalty):抑制高频词或短语,提升输出多样性。
如果不熟悉参数,建议先使用系统预设,再逐步微调。
高级功能
记忆与记忆窗口
- 记忆:在多轮对话中携带历史消息,帮助模型理解上下文。
- 记忆窗口:关闭时系统会根据上下文窗口动态裁剪;开启后可精确控制携带的历史轮数。
对话角色名设置
不同模型对角色名(如 Human/Assistant、User/Assistant)敏感度不同。可在此统一角色标识以提升模型遵循度。
Jinja2 模板
在提示中使用 Jinja2 进行轻量数据变换与逻辑控制(循环、条件、过滤、格式化等),提升提示的可维护性与可复用性。
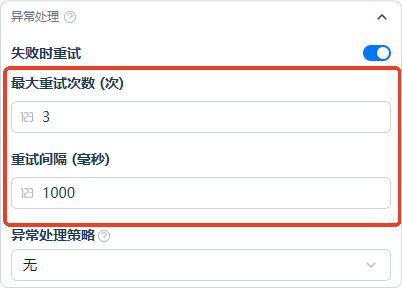
错误重试
当出现临时性错误(如限流、网络抖动)时按策略自动重试:
- 最大重试次数:支持至多 10 次;
- 重试间隔:支持至多 5000 ms。
异常处理
当节点出错时,支持:
- 抛出故障信息但不中断主流程;
- 走备用分支继续执行。
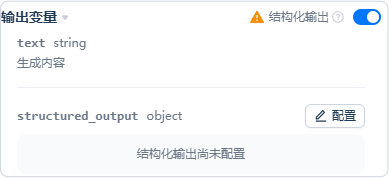
结构化输出
为确保返回数据稳定、可预测、可解析,可在 LLM 节点 > 输出变量 中启用 结构化输出,并配置 JSON Schema:
- 对原生支持结构化输出的模型:直接按 Schema 返回结构化数据;
- 对不原生支持的模型:系统会将 Schema 作为约束注入提示,引导模型尽量按结构返回(不保证 100% 可解析)。
示例:限制枚举值
{
"type": "string",
"enum": ["red", "green", "blue"]
}示例:对象结构
{
"type": "object",
"properties": {
"username": { "type": "string", "description": "用户名称" },
"age": { "type": "number" },
"interests": { "type": "array", "items": { "type": "string" } }
},
"required": ["username", "age", "interests"],
"additionalProperties": false
}使用案例
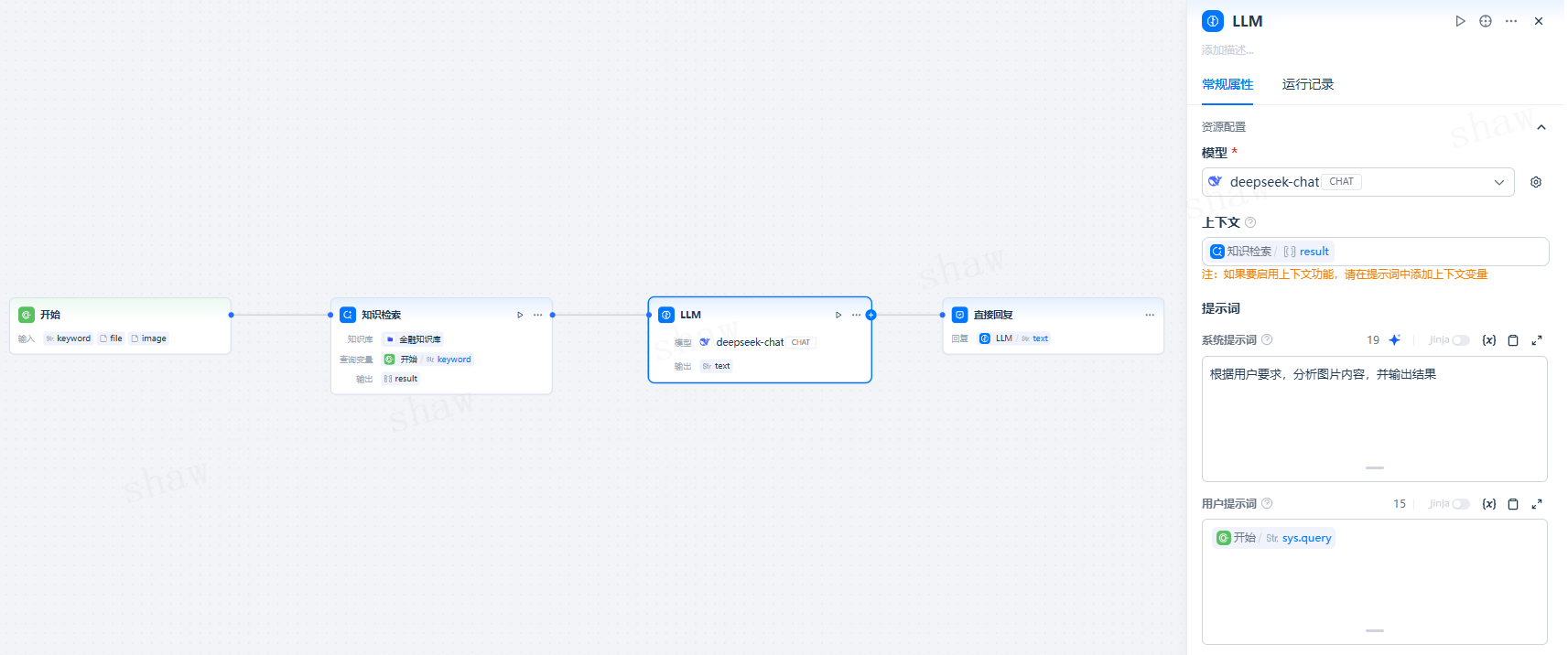
1. 读取知识库内容(RAG)
- 在 LLM 上游添加 知识检索 节点;
- 将检索节点的输出(如
result)填入 LLM 的 上下文变量; - 在提示中引用该上下文,指示模型基于检索内容作答。
提示
检索结果通常带有分段与引用信息,可在下游使用「引用与归属」能力呈现来源。
2. 读取文档文件
- 在「开始」节点添加 文件 输入;
- 在 LLM 上游添加 文档提取器 节点,输入为上述文件变量;
- 将提取器的输出(如
text)注入 LLM 提示或上下文。
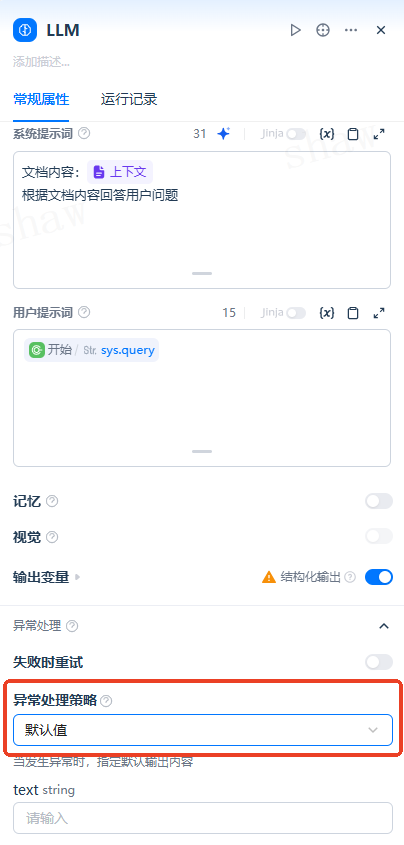
3. 异常处理
- 在 LLM 节点启用「异常处理」;
- 配置错误分支或备用路径,以避免流程整体中断。
提示优化
目标:基于上一次运行结果迭代提示,形成「提示 → 输出 → 反馈 → 再提示」的闭环,提高命中率与稳定性。 原理:LLM 节点在执行后会暴露两类上下文变量:
{current_prompt}:当前节点提示;{last_run}:该节点的上一次输入与输出。
可在提示编辑器中通过 / 或 {} 插入上述变量,用以对比与改写。
步骤:
- 打开「提示生成器」,系统会预填一条修复指令;
- 在「理想输出」区域给出静态示例(不可插入变量);
- 点击「生成」,系统将据此重写提示;
- 立即在右侧运行测试并对比版本。
注意
last_run仅记录 本 LLM 节点 的上一次输入/输出,与代码节点的代码或报错无关。- 提示优化不会破坏既有流程,可安全迭代。
- 为确保可维护性,建议将提示中的关键业务参数与变量统一在上游节点或会话变量中产出,并通过变量插入的方式进行引用。