文档提取器节点
文档提取器节点
【文档提取器】节点用于解析用户上传的文档,将其中的内容提取为纯文本(string),以便下游节点(特别是
由于大语言模型本身无法直接解析文件,因此该节点在文件类应用中扮演着“文件读取与文本转换”的关键角色。
应用场景
- 构建支持文件问答的智能体,例如 ChatPDF、ChatWord;
- 分析并检查用户上传的文件内容(如合同审阅、报告摘要、制度解析等);
- 将文件内容转换为字符串以参与多模态输入或上下文拼接;
- 在对话流智能体中支持用户上传文档并即时获取解读。
节点功能
文档提取器节点可理解为一个文件信息处理中心。
它会识别输入变量中的文件,提取文档文本并输出为字符串类型的变量,供下游节点调用。
支持的输入与输出结构
| 类型 | 输入变量 | 输出变量 | 输出说明 |
|---|---|---|---|
| 单文件 | File | text(string) | 解析单个文档,输出完整文本 |
| 多文件 | Array[File] | text(array[string]) | 解析多个文件,每个文件对应数组中的一项 |
注意
- 仅支持文本文档类型:TXT、Markdown、PDF、HTML、DOCX。
- 图片、音频、视频等非文档文件将无法被处理。
配置步骤
以下以「PDF文档对话智能体」为示例说明文档提取器的典型配置流程:
启用文件上传功能
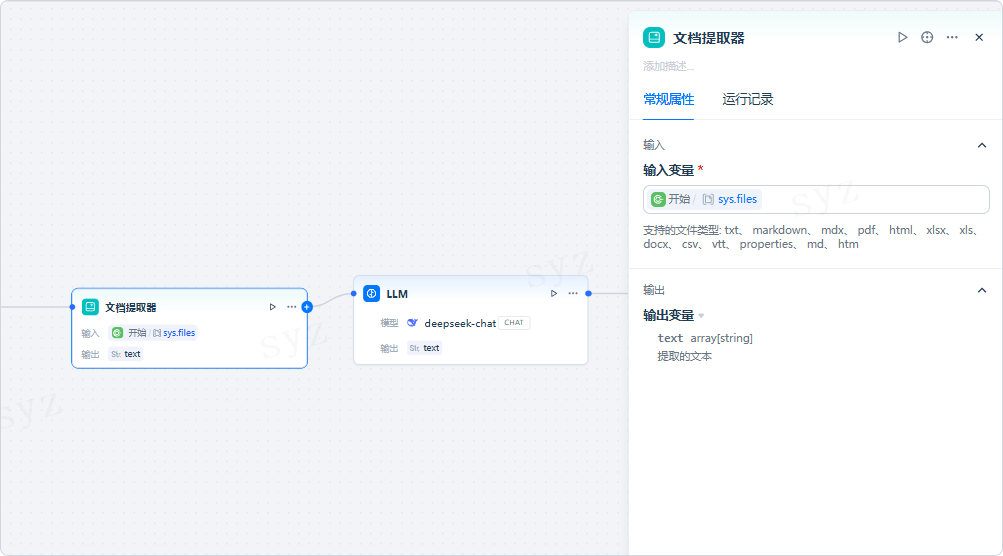
在「开始」节点中添加 单文件变量(类型为 File),命名为pdf。
这样用户可在对话中上传 PDF 文件。添加文档提取器节点
新增节点并命名为「文档提取」。
在输入变量中选择上一步定义的pdf变量。
系统将在运行时读取用户上传的文件并提取文本。连接下游 LLM 节点
在 LLM 节点的提示词配置中,选择文档提取器的输出变量text作为输入上下文。
模型即可基于文件内容生成回答。
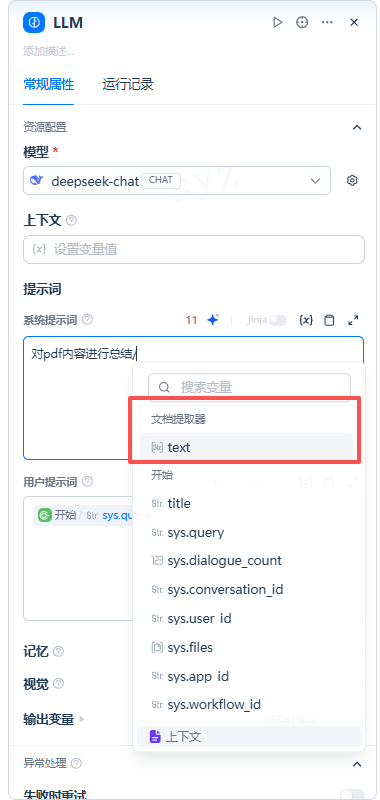
- 添加结束节点
选择 LLM 节点的输出变量作为最终输出结果。
当用户上传文档并提出问题时,智能体即可实现基于文档内容的问答。
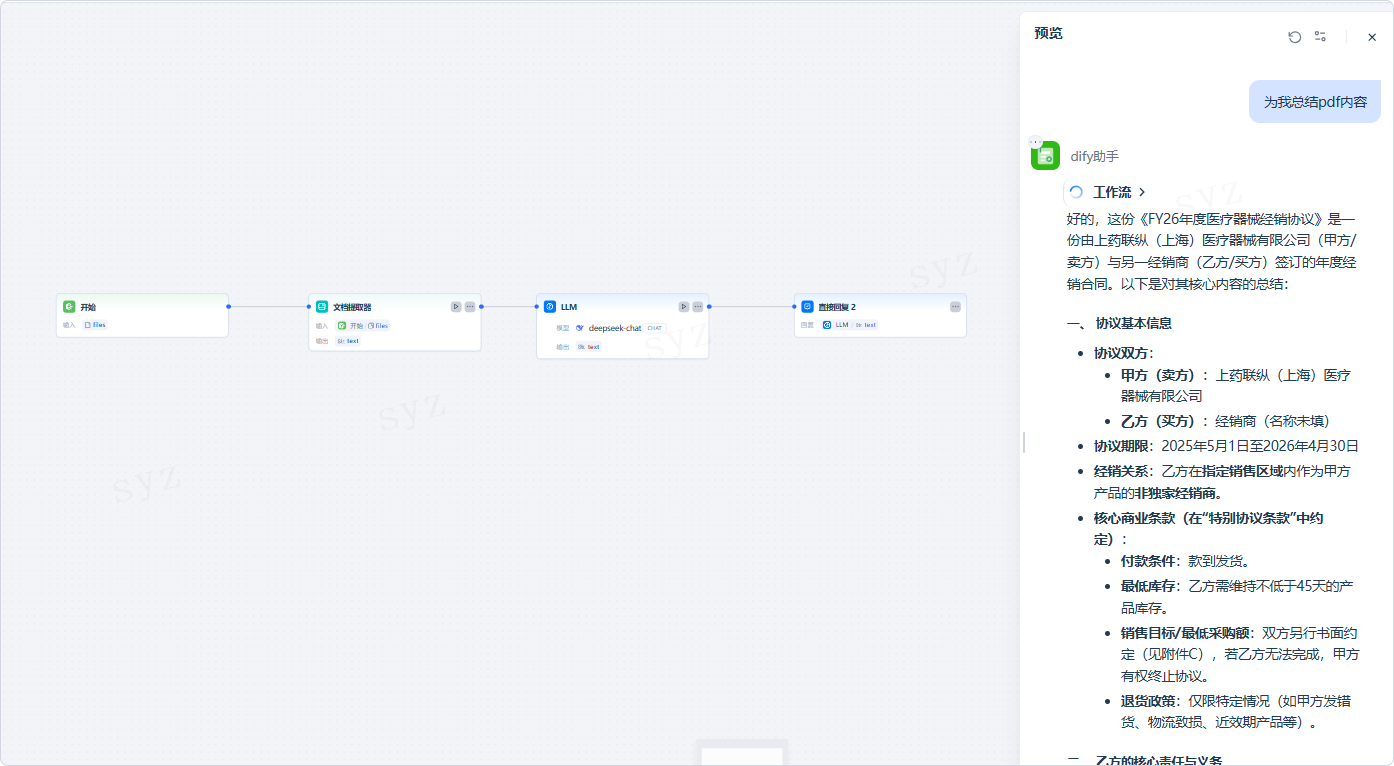
示例场景
PDF文档对话智能体
开始节点(文件上传)
↓
文档提取器(提取 PDF 文本)
↓
LLM 节点(回答用户问题)
↓
直接回复节点(输出结果)该流程可快速实现“上传 PDF → 阅读解析 → 问答输出”的完整闭环。
用户可上传任意文档,并通过自然语言与智能体对话获取分析结果。
输出变量说明
文档提取器节点的输出变量固定为 text:
| 输入类型 | 输出变量类型 | 说明 |
|---|---|---|
| File | string | 提取的文档内容 |
| Array[File] | array[string] | 提取的多个文档内容,数组内每一项对应一个文件 |
提示
若输出为数组,通常需结合
与其他节点配合使用
开始节点 → 文档提取器:获取用户上传的文件。- 文档提取器 →
LLM 节点 :将提取的文本作为 LLM 提示输入。 - 文档提取器 →
模板转换节点 :将提取内容格式化为结构化文本或摘要模板。 - 文档提取器 →
变量赋值节点 :将提取结果写入会话变量以供后续对话使用。
小结
文档提取器节点是所有基于文件交互的智能体中最关键的基础节点之一。
它承担了“从文件到可理解文本”的桥梁作用,使 AI Center 的 LLM 节点能够读取、理解并处理用户上传的真实文档。
通过与其他节点等配合使用,你可以轻松构建如“文件问答”“合同审阅”“报告分析”等智能文件理解类智能体。