变量赋值节点
变量赋值节点
【变量赋值】节点用于在工作流中向可写入变量(如会话变量、循环变量或自定义变量)进行赋值。
它通常用于在流程运行过程中动态更新变量的值,以便后续节点能够基于最新的数据进行计算或判断。
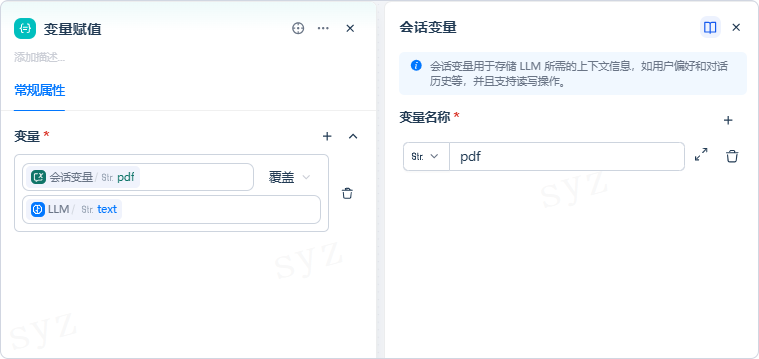
适用场景
- 在循环次数节点中更新循环变量(如计数器或中间结果);
- 在条件判断后,为不同路径设置统一变量;
- 处理 LLM 输出,提取并写入结构化字段;
- 在流程中缓存中间结果或标志位;
- 向会话变量写入信息,实现对话记忆。
节点结构
变量赋值节点包含以下配置项:
| 配置项 | 说明 | 示例 |
|---|---|---|
| 目标变量 | 选择要写入的目标变量,可为全局变量、会话变量或自定义变量 | user_name、count、summary |
| 赋值内容 | 输入固定值或引用上游节点输出 | {{ LLM.output }}、count + 1 |
| 数据类型 | 自动识别或手动指定(String、Number、Object、Array、File) | - |
| 覆盖方式 | 决定是否覆盖原值或追加 | 覆盖:替换旧值;追加:拼接至数组或字符串末尾 |
建议
若变量为数组或对象类型,可使用 Jinja 表达式 对其字段或元素进行更新。
使用场景示例
通过 变量赋值节点,你可以将会话过程中的上下文、上传至对话框的文件、用户输入的偏好信息等写入会话变量,并在后续对话中引用这些已存储的信息,导向不同的处理流程或进行个性化回复。
场景 1:自动提取并存储对话信息
示例:
开始对话后,LLM 会自动判断用户输入是否包含需要记住的事实、偏好或历史记录。如果有,LLM 会提取并存储这些信息,然后再用这些信息作为上下文来回答。如果没有新的信息需要保存,则直接使用已有记忆知识进行回答。

配置流程:
设置会话变量
创建一个会话变量数组memories,类型为array[object],用于存储用户的事实、偏好和历史记录。判断和提取记忆
- 添加条件判断节点,使用 LLM 判断用户输入是否包含新信息。
- 如果有新信息,使用 LLM 节点提取这些信息。
- 如果没有新信息,直接使用现有记忆回答。
变量赋值/写入
- 在有新信息的分支中,使用变量赋值节点将新信息追加(append)到
memories数组中。 - 使用转义功能将 LLM 输出的文本字符串转换为适合存储在
array[object]中的格式。
- 在有新信息的分支中,使用变量赋值节点将新信息追加(append)到
变量读取和使用
- 在后续 LLM 节点中,将
memories数组内容转换为字符串,并插入 LLM 的提示词中作为上下文。 - LLM 使用这些历史信息生成个性化回复。
- 在后续 LLM 节点中,将
图中的code节点代码如下::
- 将字符串转义为 object
import json
def main(arg1: str) -> object:
try:
input_data = json.loads(arg1)
memory = input_data.get("memory", {})
result = {
"facts": memory.get("facts", []),
"preferences": memory.get("preferences", []),
"memories": memory.get("memories", [])
}
return {"mem": result}
except json.JSONDecodeError:
return {"result": "Error: Invalid JSON string"}
except Exception as e:
return {"result": f"Error: {str(e)}"}- 将 object 转义为字符串
import json
def main(arg1: list) -> str:
try:
# Assume arg1[0] is the dictionary we need to process
context = arg1[0] if arg1 else {}
# Construct the memory object
memory = {"memory": context}
# Convert the object to a JSON string
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
# Wrap the JSON string in <answer> tags
result = f"<answer>{json_str}</answer>"
return {
"result": result
}
except Exception as e:
return {
"result": f"<answer>Error: {str(e)}</answer>"
}场景 2
记录用户的初始偏好信息,在会话内记住用户输入的语言偏好,在后续对话中持续使用该语言类型进行回复。
示例:
用户在对话开始前,在 language 输入框内指定了 “中文”,该语言将会被写入会话变量,LLM 在后续答复时会参考会话变量中的信息,在后续对话中持续使用 “中文” 进行回复。
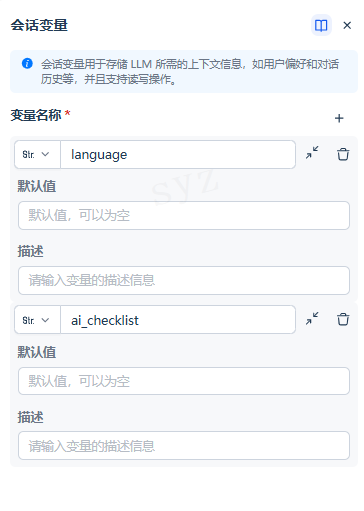
配置流程:
设置会话变量
首先设置一个会话变量language,在会话流程开始时添加一个条件判断节点,用来判断language变量的值是否为空。变量写入/赋值
首轮对话开始时,若language变量值为空,则使用 LLM 节点提取用户输入的语言,再通过变量赋值节点将该语言类型写入到会话变量language中。变量读取
在后续对话轮次中,language变量已存储用户语言偏好。LLM 节点通过引用language变量,使用用户的偏好语言类型进行回复。
场景 3
辅助 Checklist 检查,在会话内通过会话变量记录用户的输入项,更新 Checklist 中的内容,并在后续对话中检查遗漏项。
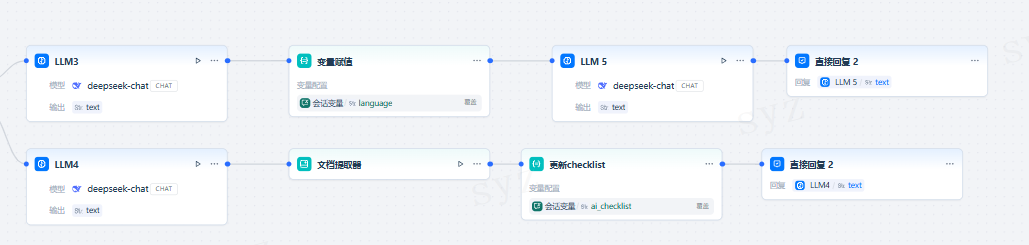
示例:
开始对话后,LLM 会要求用户在对话框内输入 Checklist 所涉及的事项,用户一旦提及 Checklist 中的内容,将会更新并存储至会话变量内。LLM 会在每轮对话后提醒用户继续补充遗漏项。
配置流程:
设置会话变量
首先设置一个会话变量ai_checklist,在 LLM 内引用该变量作为上下文进行检查。变量赋值/写入
每一轮对话时,在 LLM 节点内检查ai_checklist内的值并比对用户输入。若用户提供了新的信息,则更新 Checklist 并将输出内容通过变量赋值节点写入到ai_checklist内。变量读取
每一轮对话读取ai_checklist内的值并比对用户输入,直至所有 Checklist 完成。
使用技巧
- 使用 Jinja 表达式 可灵活组合赋值逻辑,例如:
{{ count + 1 }}或
{{ text | trim | upper }}- 若目标变量为数组,可使用追加模式以保留历史值;
- 若需要在多个节点间共享变量,建议使用会话变量;
- 若仅在循环/局部范围内使用,可用临时变量。
使用变量赋值节点
添加变量赋值节点
点击节点右侧 + 号,选择 “变量赋值” 节点,填写 “赋值的变量” 和 “设置变量”。
- 赋值的变量:选择被赋值变量,即指定需要被赋值的目标会话变量。
- 设置变量:选择需要赋值的变量,即指定需要被转换的源变量。
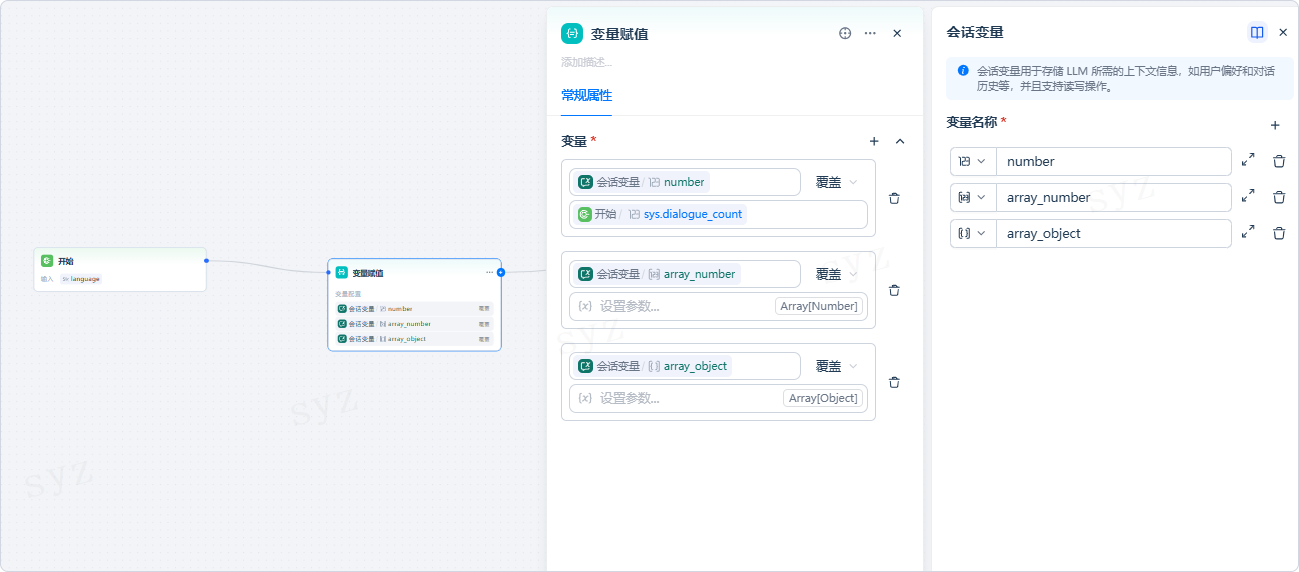
指定变量的写入模式
目标变量的数据类型将影响变量的写入模式。以下是不同变量类型的写入模式:
1. 目标变量类型:String
- 覆盖:将源变量直接覆盖至目标变量
- 清空:清空所选中变量中的内容
- 设置:手动指定一个值,无需设置源变量
2. 目标变量类型:Number
- 覆盖:将源变量直接覆盖至目标变量
- 清空:清空所选中变量中的内容
- 设置:手动指定一个值,无需设置源变量
- 数字处理:对目标变量进行加减乘除操作
3. 目标变量类型:Object
- 覆盖:将源变量的内容直接覆盖至目标变量
- 清空:清空所选中变量中的内容
- 设置:手动指定一个值,无需设置源变量
4. 目标变量类型:Array
- 覆盖:将源变量的内容直接覆盖至目标变量
- 清空:清空所选中变量中的内容
- 追加:在目标的数组变量中添加一个新的元素
- 扩展:在目标的数组变量中添加新的数组,即一次性添加多个元素
- 移除:从数组中移除元素,可选择从头部移除(First)或尾部移除(Last,默认为头部移除)
注意事项
- 变量赋值节点不会自动创建新变量,请确保目标变量已在上游或全局中声明;
- 不同数据类型的变量不能混合赋值;
- 若在并行分支中同时更新同一变量,可能会出现写入冲突,建议使用独立变量或合并节点。
小结
变量赋值节点是流程中的关键中间处理环节,常用于:
- 传递中间状态;
- 动态更新变量值;
- 管理循环与分支的数据流。
与