大语言模型设置
大语言模型设置
在 大语言模型设置 模块中,您可以为智能体选择所使用的基础大语言模型(LLM),并根据需求配置相应的参数。
不同模型在语言理解、生成风格和性能方面有所差异,选择合适的模型能够显著提升智能体的表现。
选择模型
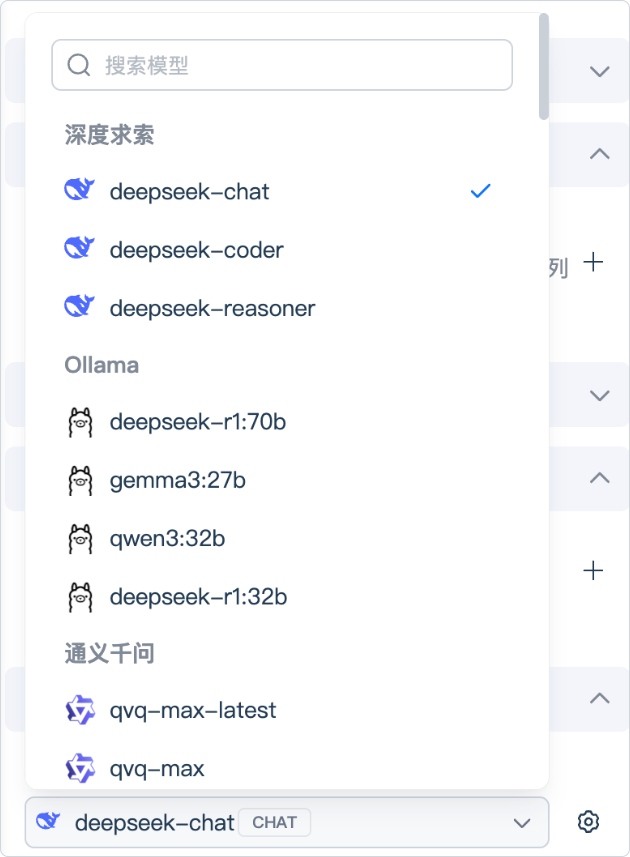
点击下拉框后,系统会列出可用的大语言模型列表,例如:DeepSeek、Qwen、Doubao 等等。
您可以根据业务场景选择最合适的模型:
- 若追求更自然、流畅的回答,可选择高性能通用模型
- 若需私有部署或行业专用模型,可选择企业自建模型或国产模型
设置模型参数
在模型选择框右侧点击  ,即可打开 参数设置面板。
,即可打开 参数设置面板。
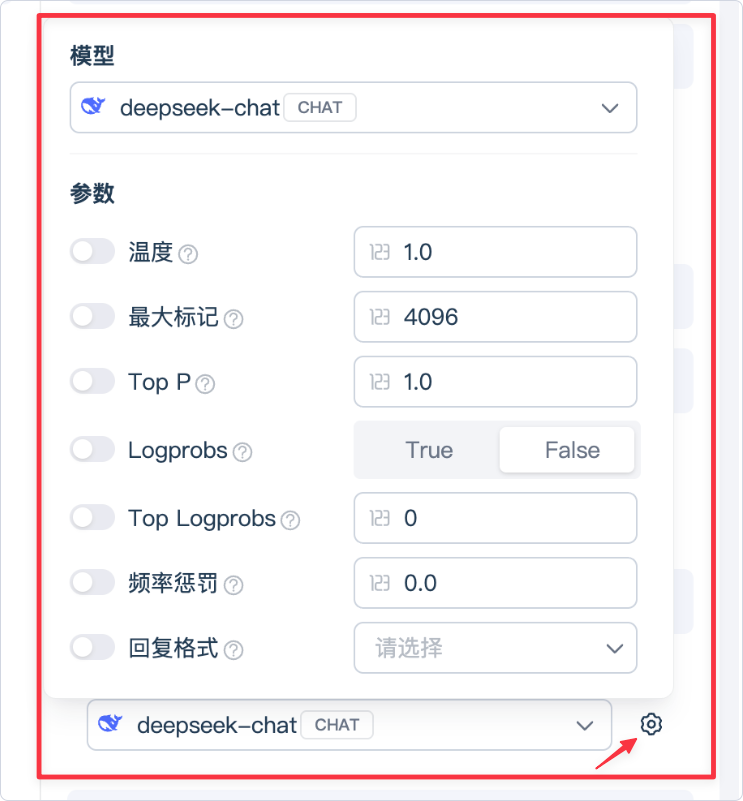
以 DeepSeek-Chat 为例,您可以配置以下参数:
| 参数 | 说明 | 推荐范围 / 默认值 |
|---|---|---|
| 温度(Temperature) | 控制生成内容的随机性。值越高(如 1.0–1.5)→ 回复更有创意但不稳定;值越低(如 0.2–0.5)→ 回复更稳定更可控。 | 默认 1.0 |
| 最大标记(Max Tokens | 模型单次输出的最大字数(Token 数量)。值越大可输出更长文本,但响应时间与消耗也更高。 | 默认 4096 |
| Top P(核采样) | 控制输出词汇的概率分布,与温度共同影响创造性。保持 1.0 即为关闭限制。 | 默认 1.0 |
| Logprobs | 是否返回模型生成每个词的概率,用于分析、调试或评分。True 表示开启。 | 默认 False |
| Top Logprobs | 当 Logprobs 开启时,设置返回多少个备选词的概率。例如设为 5,则返回前 5 个候选词。 | 默认 0(不返回) |
| 频率惩罚(Frequency Penalty) | 控制模型重复用词的惩罚程度。值越高→越避免重复。 | 默认 0.0 |
| 回复格式(Response Format) | 指定模型输出的格式,如 text、json、markdown、html 等。 | 默认空(自动识别) |
使用建议
- 若您对模型参数不熟悉,建议保持默认设置即可
- 修改参数前,可在右侧调试区实时验证生成效果
- 不同模型支持的参数项可能略有差异,建议在正式使用前进行测试
注意
参数配置影响智能体的生成质量与性能,若不确定其作用,请谨慎修改或咨询管理员。