索引方法与检索设置
索引方法与检索设置
在完成分段设置后,需要为结构化内容配置“索引方式”与“检索设置”。
合理的索引与检索将直接影响智能体对知识库内容的召回效率与回答准确性。
设定索引方式
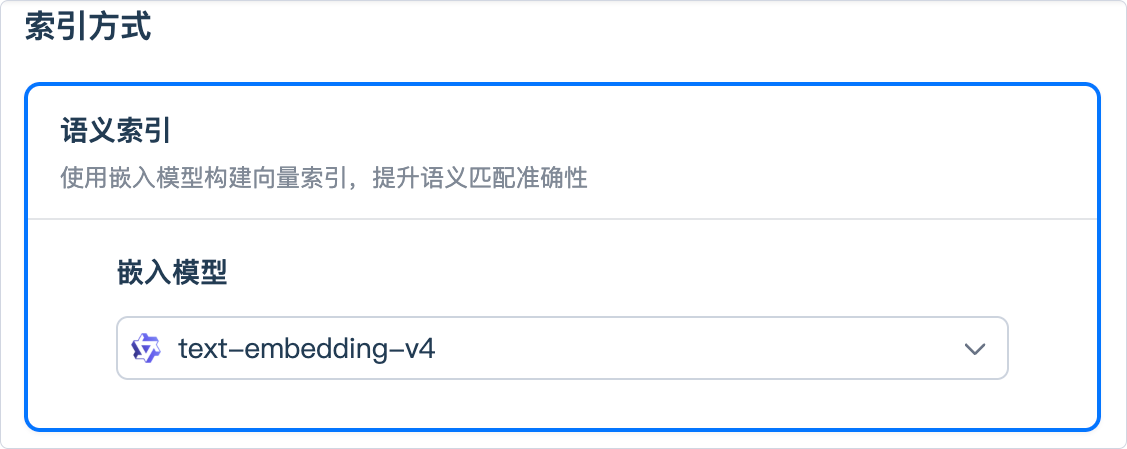
AI Center 采用「语义索引」方式。
语义索引会将已分段的文本转换为向量表示(Embedding),并在查询时把用户问题同样向量化,通过比较向量相似度来召回最相关的内容分段。
关于 Embedding / 嵌入模型
- Embedding 是一种将离散变量(单词、句子、段落、文档等)映射到连续向量空间的表示方法。
- 它以低维、稠密的数值向量来保留语义信息,既减少维度又提高检索效率。
- Embedding 模型 专门用于将文本向量化,能够有效捕捉语义相似度,为后续的内容检索与重排序提供基础。
选择嵌入模型的参考要点:
- 语种覆盖与多语能力:是否支持中文/英文/日文等混合语料
- 向量维度:维度越高,表达力越强但存储与计算成本更高
- 领域适配:通用模型 vs. 行业专用模型(法务、医疗、财务等)
- 时延与成本:在线服务 vs. 自建服务的吞吐与费用约束
- 一致性:同一知识库内建议固定一种嵌入模型,避免相似度指标失真
说明:采用语义索引后,知识库将按所选嵌入模型完成向量化与入库。若需要切换嵌入模型,建议新建知识库并重新向量化。
检索设置
AI Center 在「语义索引」下提供三种检索方式:向量检索、全文检索、混合检索。
您可按业务需求选择单一或组合方式来取得最优的召回效果。
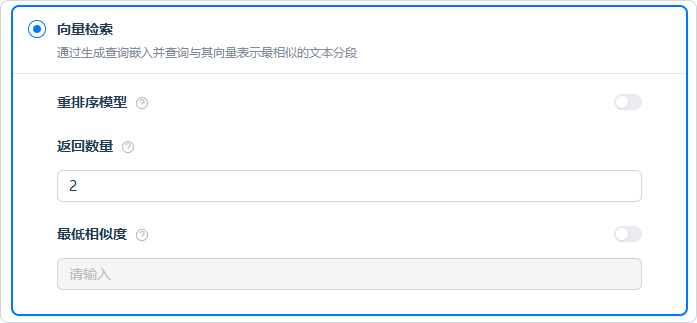
1. 向量检索
将用户查询向量化,比较查询向量与知识库文本向量的距离,召回最相近的内容分段(语义匹配)
可配置项:
- 重排序模型:
对已召回的内容分段进行二次重排序,进一步提升排序质量
注意
开启后会产生相应的模型调用费用。
返回数量:
指定返回给模型的分段数量。数值越大,可用上下文越多,但也更占用上下文窗口最低相似度:
仅返回相似度不低于该阈值的分段。数值越高,结果更严格、数量更少
注意
在 AI Center 中,「返回数量」与「最低相似度」在启用 重排序模型 时生效;未启用时由检索引擎使用内部策略进行截断与过滤。
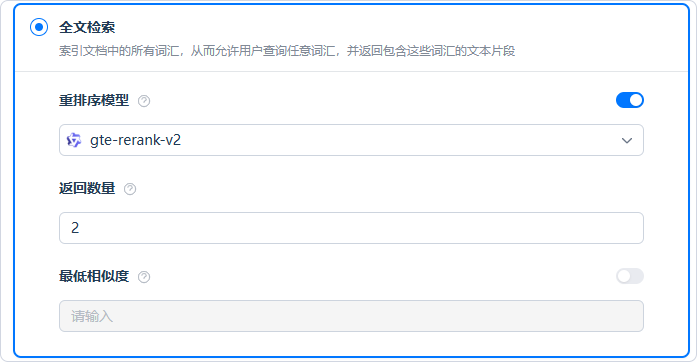
2. 全文检索
基于关键词的倒排索引检索(明文匹配)。适用于已知专有名词、编号、术语等精确查询场景。
可配置项:
- 重排序模型:启用后对全文检索的结果进行语义层面的二次重排
- 返回数量:指定返回给模型的分段数量
- 最低相似度:同样仅在启用重排序模型时生效
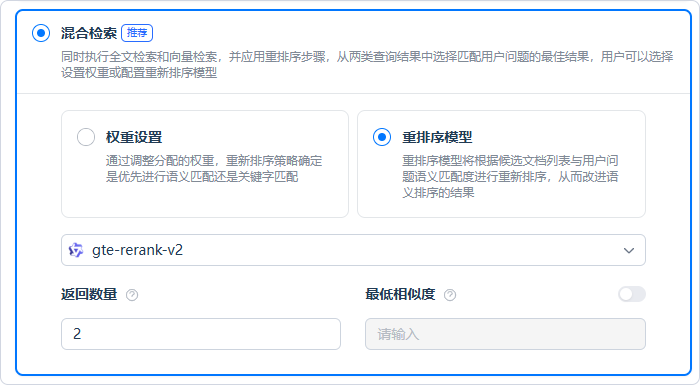
3. 混合检索
同时执行【向量检索】与【全文检索】,再以权重或 重排序模型 的方式合并结果,兼顾语义理解与关键词精确命中。
两种合并方式:
- 权重合并:为「语义检索」与「关键词检索」分别设定权重
- 语义权重 = 1:等同仅用向量检索
- 关键词权重 = 1:等同仅用全文检索
- 自定义比例:在不同场景间调参取平衡(例如 0.7/0.3、0.5/0.5)
- 重排序模型 合并:启用重排序模型对两路结果进行统一重排
可配置项:
- 返回数量:指定返回给模型的分段数量
- 最低相似度:在启用重排序模型或权重合并时生效;若仅采用默认合并策略,则由系统内部算法确定截断与过滤
设置建议与常见搭配
- FAQ/客服类(短问短答):向量检索;必要时开启 重排序模型;返回数量 3–5,最低相似度 0.4–0.6
- 制度/规范/手册(长文):分层分段 + 混合检索;语义权重略高(如 0.6–0.8);开启 重排序模型
- 强术语/强编号场景:全文检索或混合检索(提高关键词权重);返回数量 3–8
- 多语言知识库:优先选择多语嵌入模型;采用向量或混合检索,并视情况开启 重排序模型