分段设置(内容预览与清洗)
分段设置(内容预览与清洗)
文档上传至知识库后,系统会对内容进行分段与清洗。
这是知识数据进入检索前的重要预处理过程,长文本将被自动划分为多个结构化的内容区块(Chunks),以便后续高效召回与问答。
分段处理的核心目标,是让大语言模型(LLM)能够在有限的上下文窗口内快速检索到最相关的知识内容,从而生成更准确的回答。
合理的分段方式与清洗策略,可以显著提升检索命中率、减少噪音干扰,并避免模型出现幻觉回答。
分段与清洗策略简介
分段
由于大语言模型的上下文窗口有限,无法一次性处理整个知识库的内容,因此需要将文档拆分为多个内容块。
系统通过计算问题与各内容块的语义相似度,从知识库中召回相关度最高的若干分段(Top-K 召回),并将这些分段作为上下文提供给模型。
合理的分段设置有助于:
- 提升问题与内容块的匹配精度
- 保留足够的上下文信息
- 降低不相关信息对模型回答的干扰
清洗
清洗是指在录入前对原始文本进行格式优化与无效信息过滤。
AI Center 已内置自动清洗策略,例如:
- 去除多余空格、换行符、制表符
- 删除无意义的符号、URL 和邮箱地址等
清洗后的文本将更便于模型理解与检索。
分段模式
AI Center 支持三种分段模式:自动分段、规则分段和分层分段。
开发者可根据文档类型与业务场景,选择最合适的分段方式。
1. 自动分段(Auto)

系统自动完成内容切分与格式清洗,无需人工配置。
AI Center 将依据文本结构(如标题层级、段落符号、换行符等)智能判断分段位置,并执行标准化处理。
适用场景:
- 一般文本、FAQ 或无复杂层次的内容
- 快速构建与验证知识库内容时
优点:无需配置即可使用,适合非技术人员或初次建库。
缺点:分段规则不可自定义,粒度控制较弱。
2. 规则分段(Rule-based)
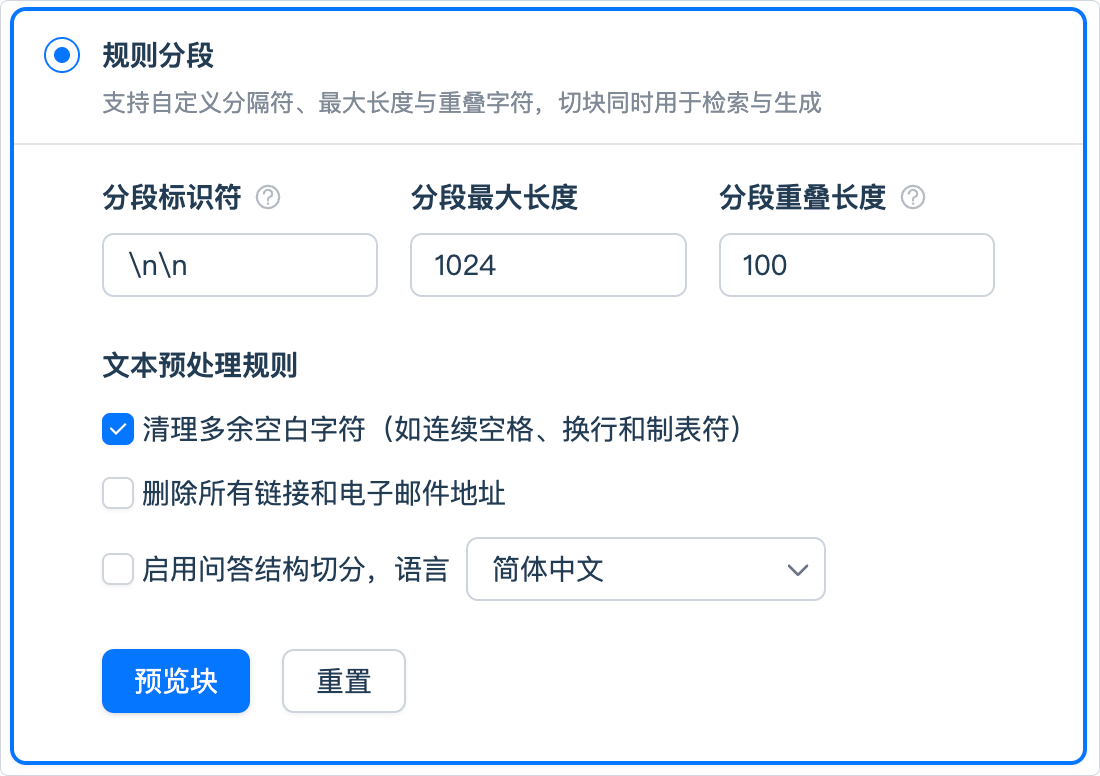
规则分段模式允许开发者根据文档结构自定义切分规则。
系统将按照用户定义的“分段标识符”和“最大长度”等参数,将文本划分为多个内容块。
配置项说明:
分段标识符:
默认值为\n(换行符),即按照段落进行分块。
支持使用 正则表达式 自定义规则,例如:\n:按段落分段[。?!]:按句号、问号、感叹号分句###:按标题结构分。
分段最大长度:
指定单个分段的最大文本长度(默认 500 Tokens,最大 4000 Tokens)。
超出该长度的部分将自动切分为新段。分段重叠长度:
指相邻分段之间共享的文本长度,用于保留上下文连续性。
建议设置为分段长度的 10%~25%。文本预处理规则(可选):
- 替换连续空格、换行符和制表符
- 删除所有 URL 和电子邮件地址
完成设置后,点击【预览区块】即可查看分段效果。
如修改规则,请重新点击按钮以生成新的分段结果。若上传了多个文件,可通过顶部文档标签快速切换并查看不同文档的分段情况。
3. 分层分段(Hierarchical)
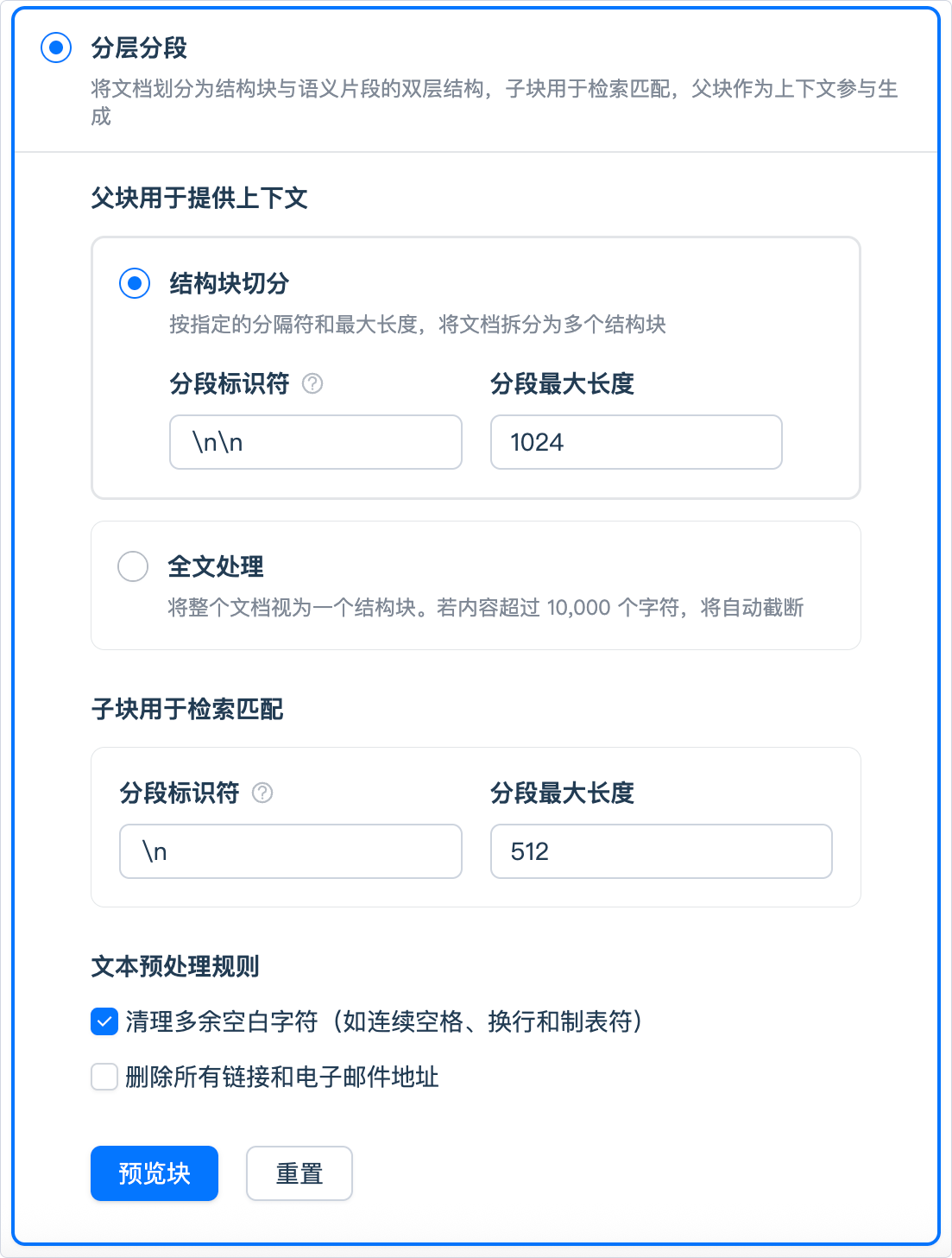
分层分段模式(父子分段)采用“双层结构”进行内容切分,在保证检索精准度的同时,保留更完整的上下文信息。
该模式在 AI Center 中常用于技术文档、手册类内容或企业制度类长文档。
工作机制:
子分段(Child Chunk): 将文档拆分为较小的信息单元(如句子),用于精确匹配用户问题
父分段(Parent Chunk):保留较大的文本结构(如段落或章节),在召回相关子分段后,为 LLM 提供完整上下文
模型检索时,系统先通过子分段进行匹配定位,再关联父分段内容作为补充,最终生成更完整的答案
父分段设置
分段方式
- 段落模式:按换行符或正则标识符分段,每段视为一个父区块
- 全文模式:不分段,将全文作为单个父区块(保留前 10,000 Tokens)
分段标识符:默认值为
\n,可自定义正则表达式分段最大长度:默认 500 Tokens,最大 4000 Tokens
子分段设置
- 分段标识符:默认按句子切分,可自定义规则
- 分段最大长度:默认 200 Tokens,最大 4000 Tokens
- 文本预处理:可选项包括替换空格/换行符及删除 URL
配置完成后,点击 「预览块」 可查看父子分段结构。
高亮部分表示子区块,背景蓝色区域表示父区块,便于直观查看文本分层效果
三、三种模式对比
| 分段模式 | 特点 | 适用场景 | 是否可自定义 |
|---|---|---|---|
| 自动分段 | 自动清洗与切分,零配置 | 一般文本、FAQ、轻量场景 | 否 |
| 规则分段 | 用户自定义分隔符、长度、重叠 | 技术文档、规范、制度类文档 | 是 |
| 分层分段 | 父子双层结构,精准与上下文兼顾 | 复杂结构文档、手册、培训资料 | 是(分别配置父/子分段) |
分段设置完成后,下一步需要选择【索引方式】,以决定知识内容的向量化与检索性能。