-
outlook 接收不到邮件
2020-01-21 09:10 -
请问 APP 的怎么用 RPA 爬数据
2020-01-06 18:18能说的详细点吗
用什么工具抓包,大致思路是什么 -
重新打开或刷新网页就无法操作控件的问题定位
2019-11-27 14:47我发现上面的解决方法,对 IE 浏览器是好用的,但是对谷歌浏览器不管用,怎么办。
-
对于合并单元格的 excel,怎么读取处理
2019-09-16 10:33你真是太棒了,正是我需要的,爱死你了
-
IE 浏览器元素顺序不固定,怎么写 selector
2019-09-10 08:21已经解决,方法如下:
做个循环,循环里面先读取文本,然后判断,不是就继续,是就点击,然后跳出循环。
selector 在循环里拼。
感谢各位。 -
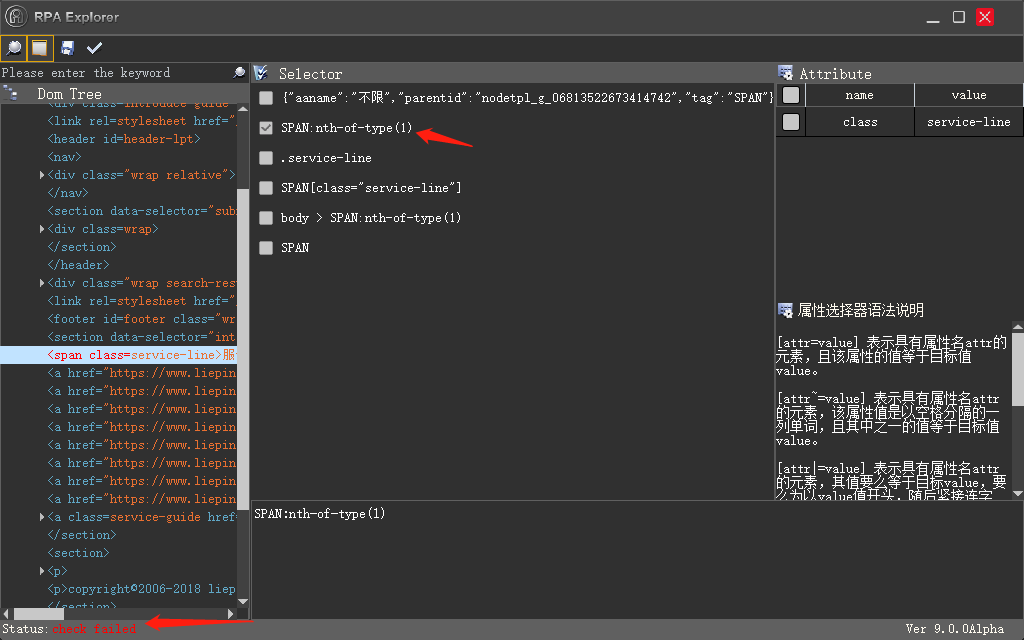
猎聘网的 selector 有个属性随机变化,没有规律,我改怎么办
2019-09-04 10:05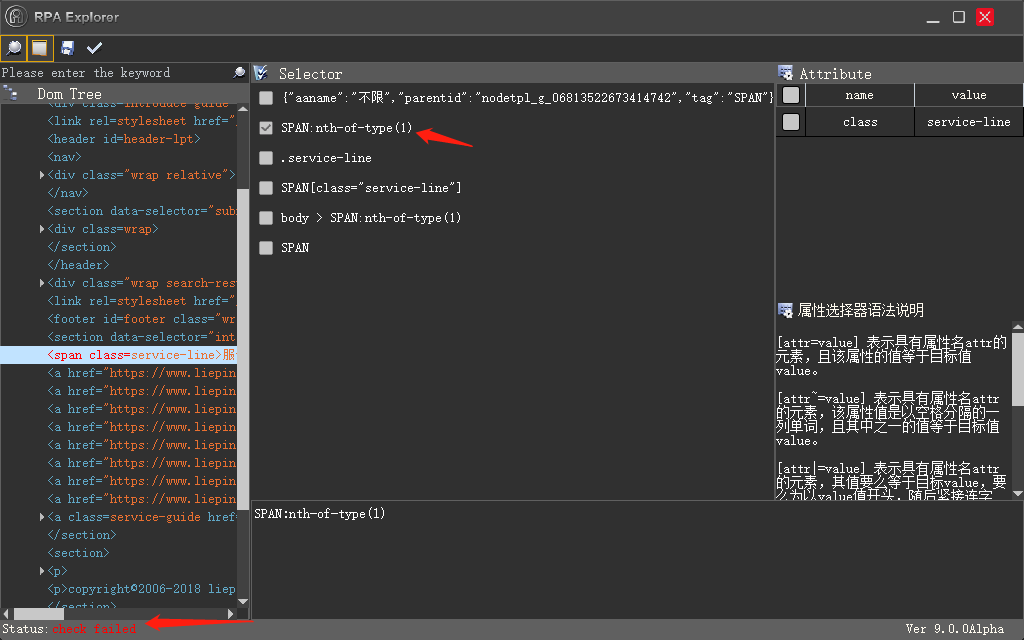
-
猎聘网的 selector 有个属性随机变化,没有规律,我改怎么办
2019-09-04 09:03换一个路径,发现其他路径不能用,check 是失败的,不知道为什么
-
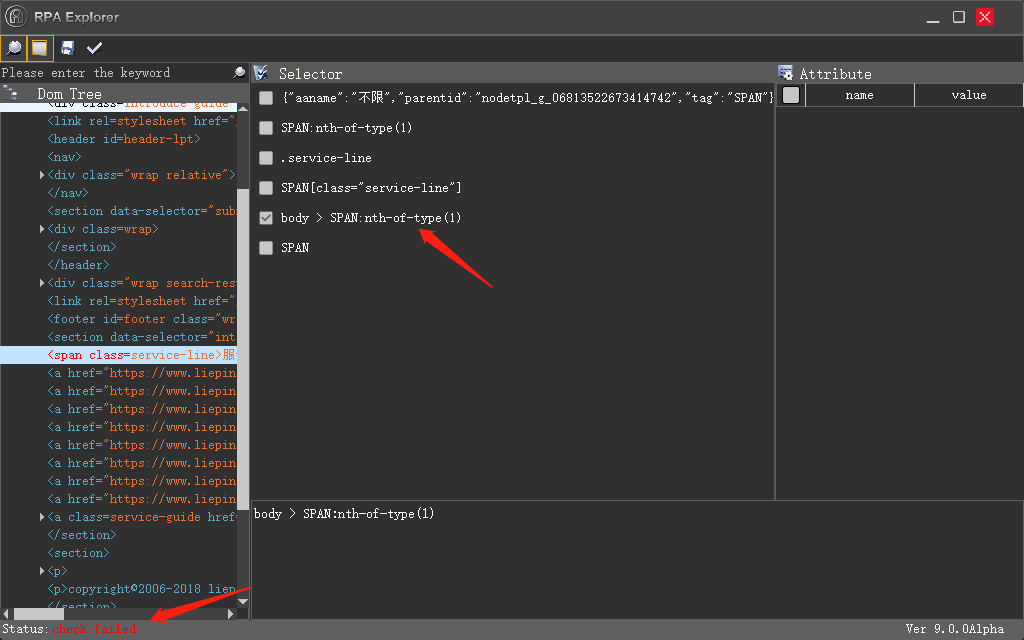
怎么获取一个页面满足某种条件的 selector
2019-09-04 08:31不知道为什么,其他路径我选中用不了,check 也是失败的,我看 IE 浏览器的正常,唯独这个谷歌的不行。
我这个项目必须用谷歌浏览器,因为要用个谷歌插件和另外一个系统对接。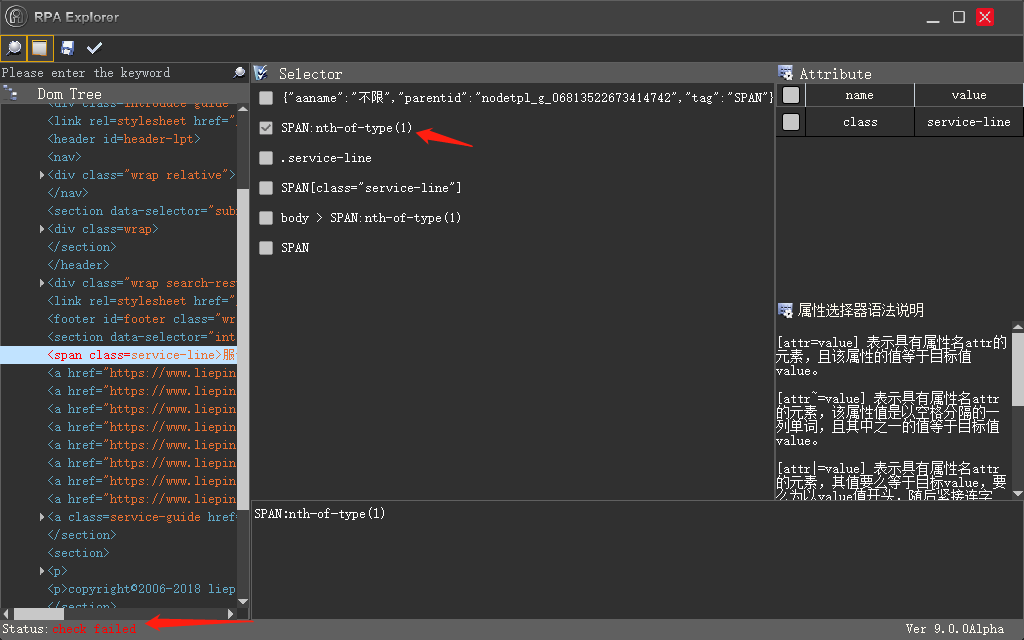
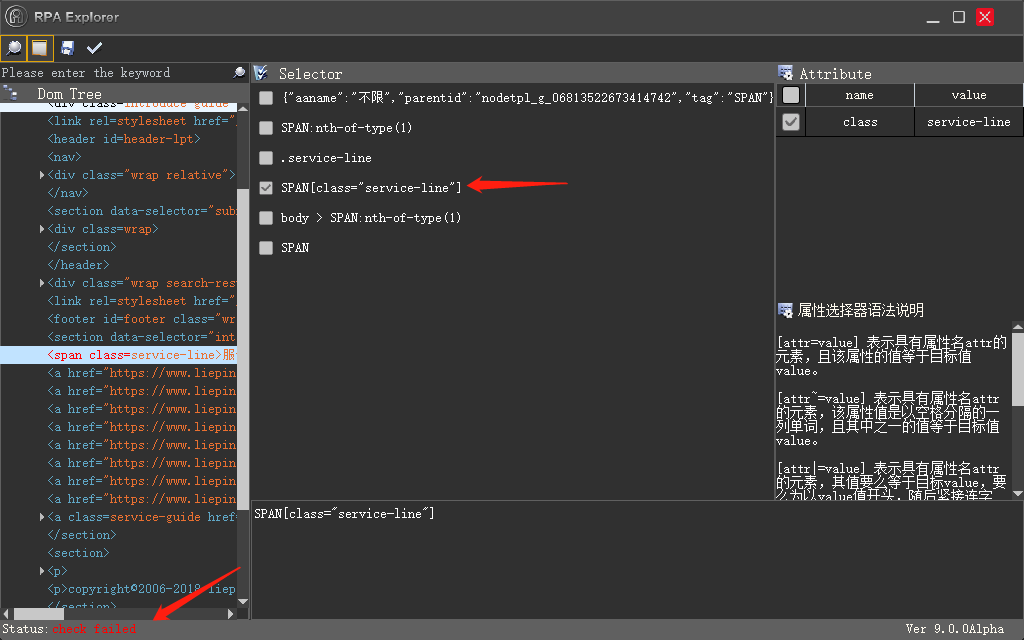
-
怎么取出 dom 中,样式里面的地址
2019-08-30 16:52谢谢你,用 requests 模块。
import requests
from lxml import etreeurl=‘https://item.jd.com/2710503.html#crumb-wrap’
r = requests.get(url)
print(r.text)
tree = etree.HTML(r.text) -
怎么取出 dom 中,样式里面的地址
2019-08-30 16:29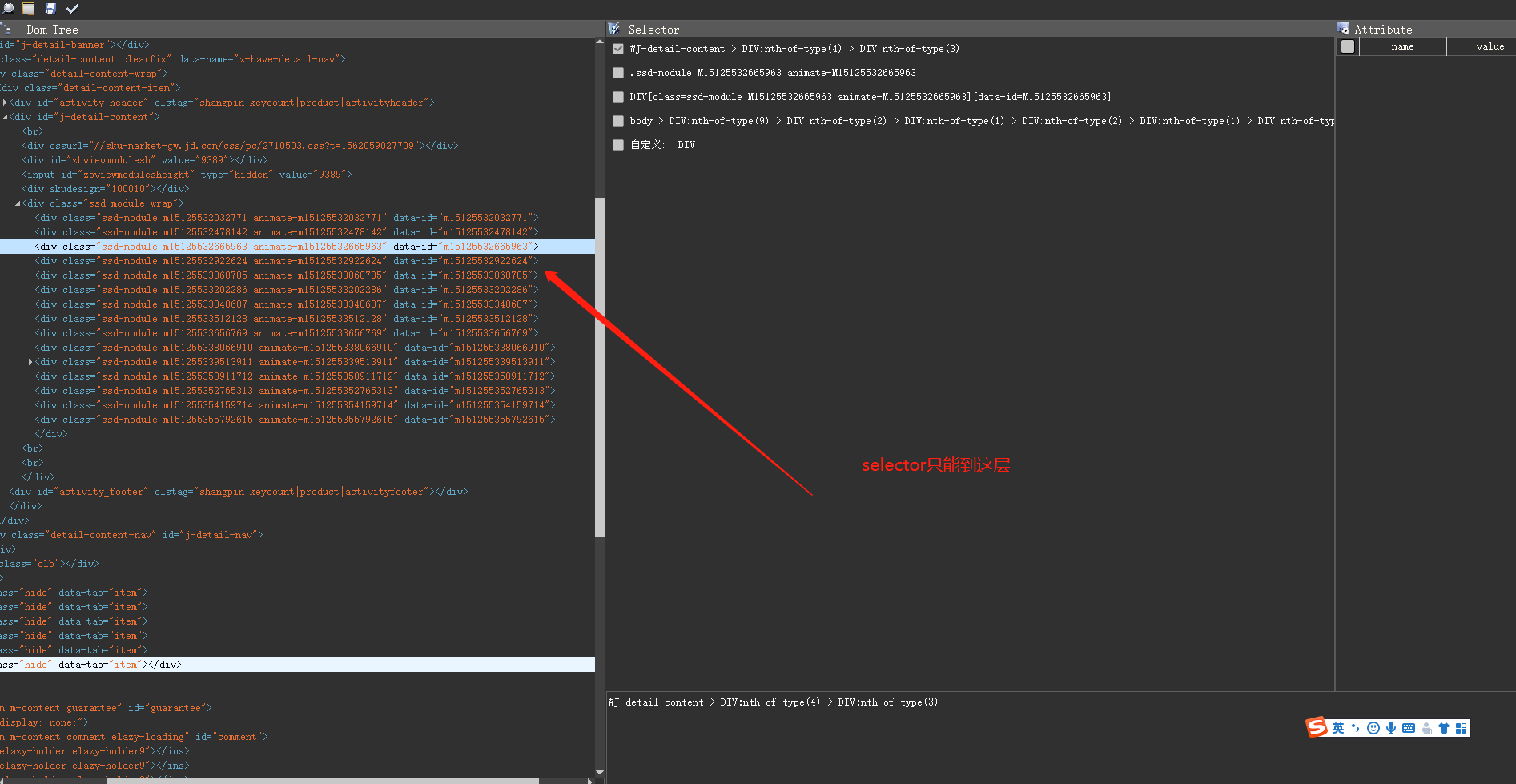
-
怎么取出 dom 中,样式里面的地址
2019-08-30 16:28最主要的是,ubpa.iie..get_html 获取不到右边的 html 内容,我想知道这个内容怎么获取出来。
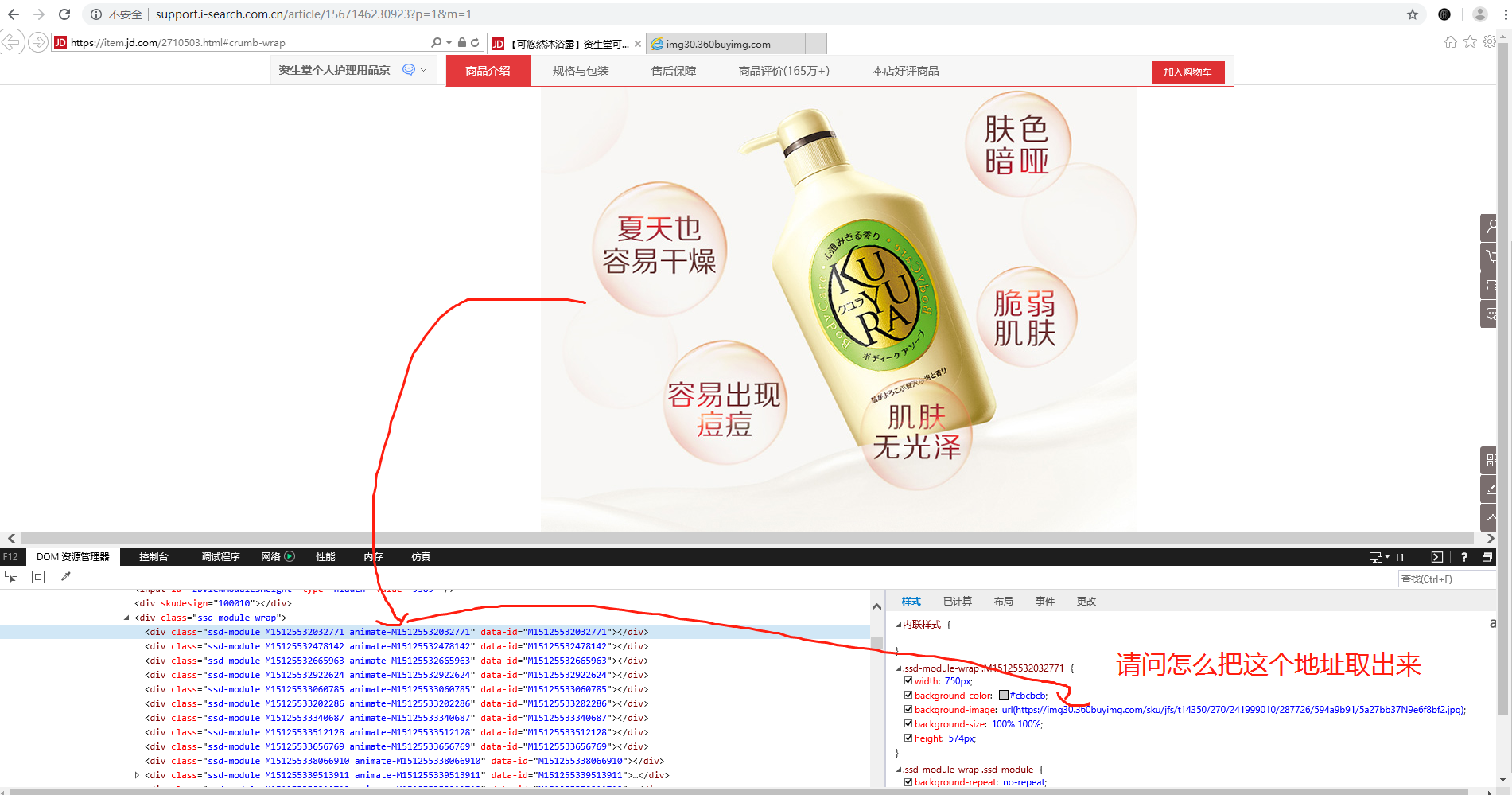
-
怎么取出 dom 中,样式里面的地址
2019-08-30 15:59您好:
我看了 from bs4 import BeautifulSoup 库,我看是从 html 里面提取属性的。
但是现在我不知道应该怎么样获取下这个 html 里面的内容。 -
在一个长页面,怎么实现滑轮滚动
2019-08-30 14:17我想到一个办法,就是不知道怎么把地址取出来。
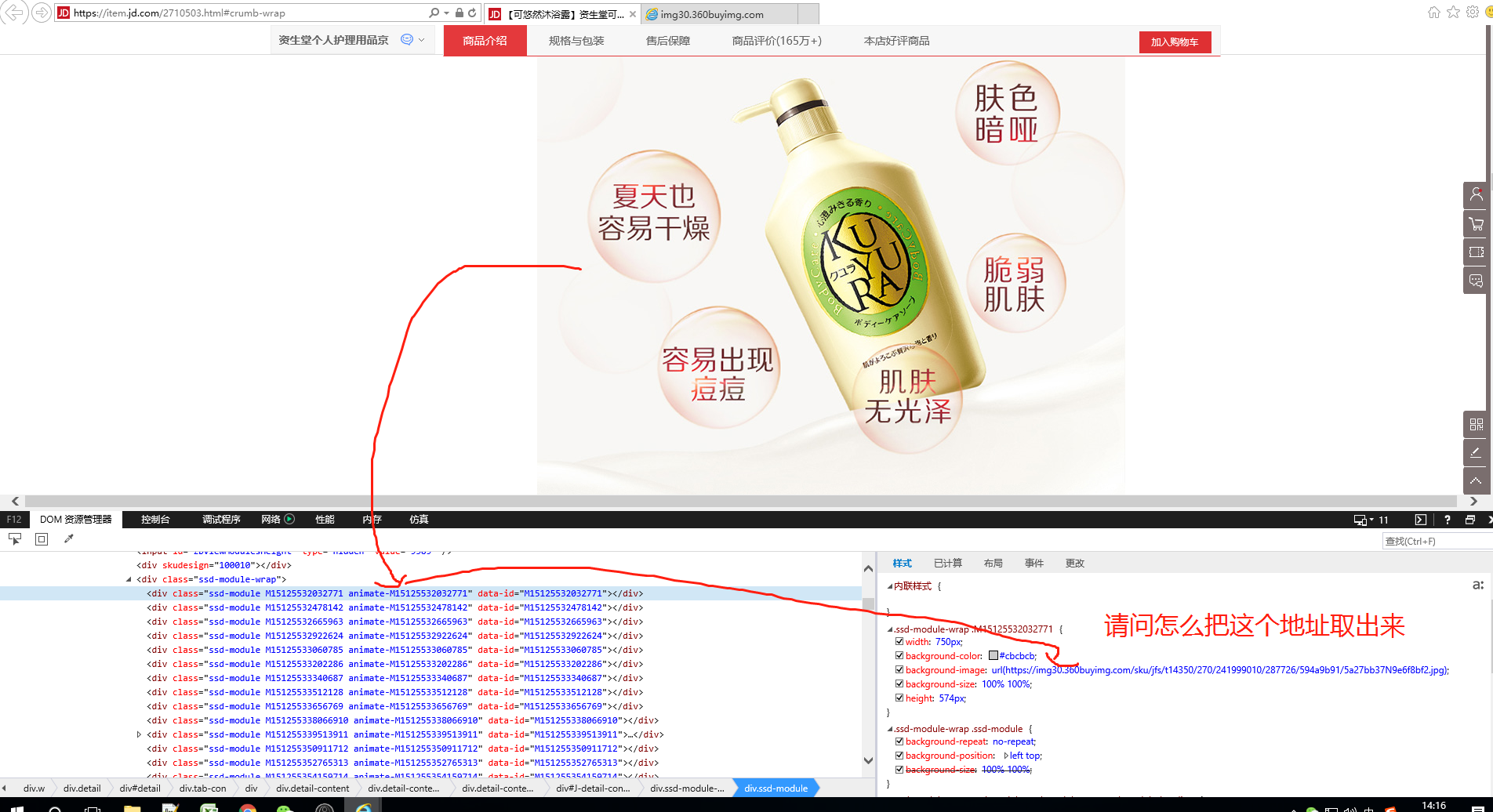
-
我要在京东和淘宝上更新商品价格,价格在每个页面位置不一样怎么办
2019-08-19 14:39更正一下:
我要在京东和淘宝上获取商品价格,价格在每个页面位置不一样怎么办
是获取商品价格
七月的七
qms7ljvl1x

- 0 标签
- 18 帖子
- 14 回帖

都试了,不行,我准备放弃了。