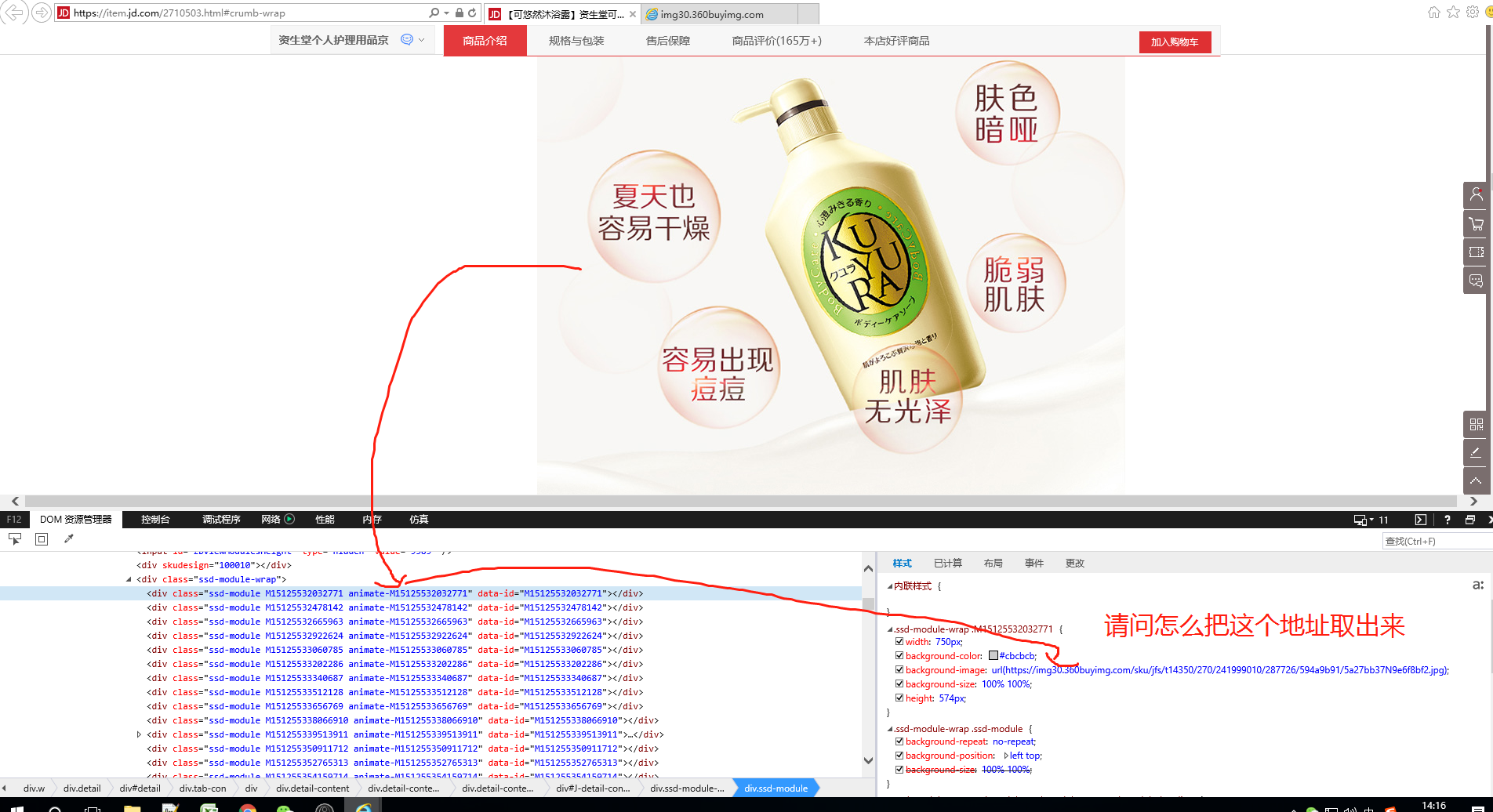
"怎么取出 dom 中,样式里面的地址,如下: [图片]"
怎么取出 dom 中,样式里面的地址,如下:
谢谢你,用 requests 模块。import requestsfrom lxml import etree
url=‘https://item.jd.com/2710503.html#crumb-wrap’r = requests.get(url)print(r.text)tree = etree.HTML(r.text)
这个只能写代码实现 https://www.jb51.net/article/121593.htm 爬虫不是也可以玩这个么
最主要的是,ubpa.iie..get_html 获取不到右边的 html 内容,我想知道这个内容怎么获取出来。
可参考 http://support.i-search.com.cn/article/1538019514108 ,可以百度下有很多方法可以获取 html
您好:我看了 from bs4 import BeautifulSoup 库,我看是从 html 里面提取属性的。但是现在我不知道应该怎么样获取下这个 html 里面的内容。
这个要写代码了,试试 from bs4 import BeautifulSoup 库

 Rpa 5367 号会员
寻求帮助
•
7 回帖
•
1.1K
浏览
•
2019-08-30 14:23:50
Rpa 5367 号会员
寻求帮助
•
7 回帖
•
1.1K
浏览
•
2019-08-30 14:23:50

谢谢你,用 requests 模块。
import requests
from lxml import etree
url=‘https://item.jd.com/2710503.html#crumb-wrap’
r = requests.get(url)
print(r.text)
tree = etree.HTML(r.text)
这个只能写代码实现 https://www.jb51.net/article/121593.htm 爬虫不是也可以玩这个么
最主要的是,ubpa.iie..get_html 获取不到右边的 html 内容,我想知道这个内容怎么获取出来。
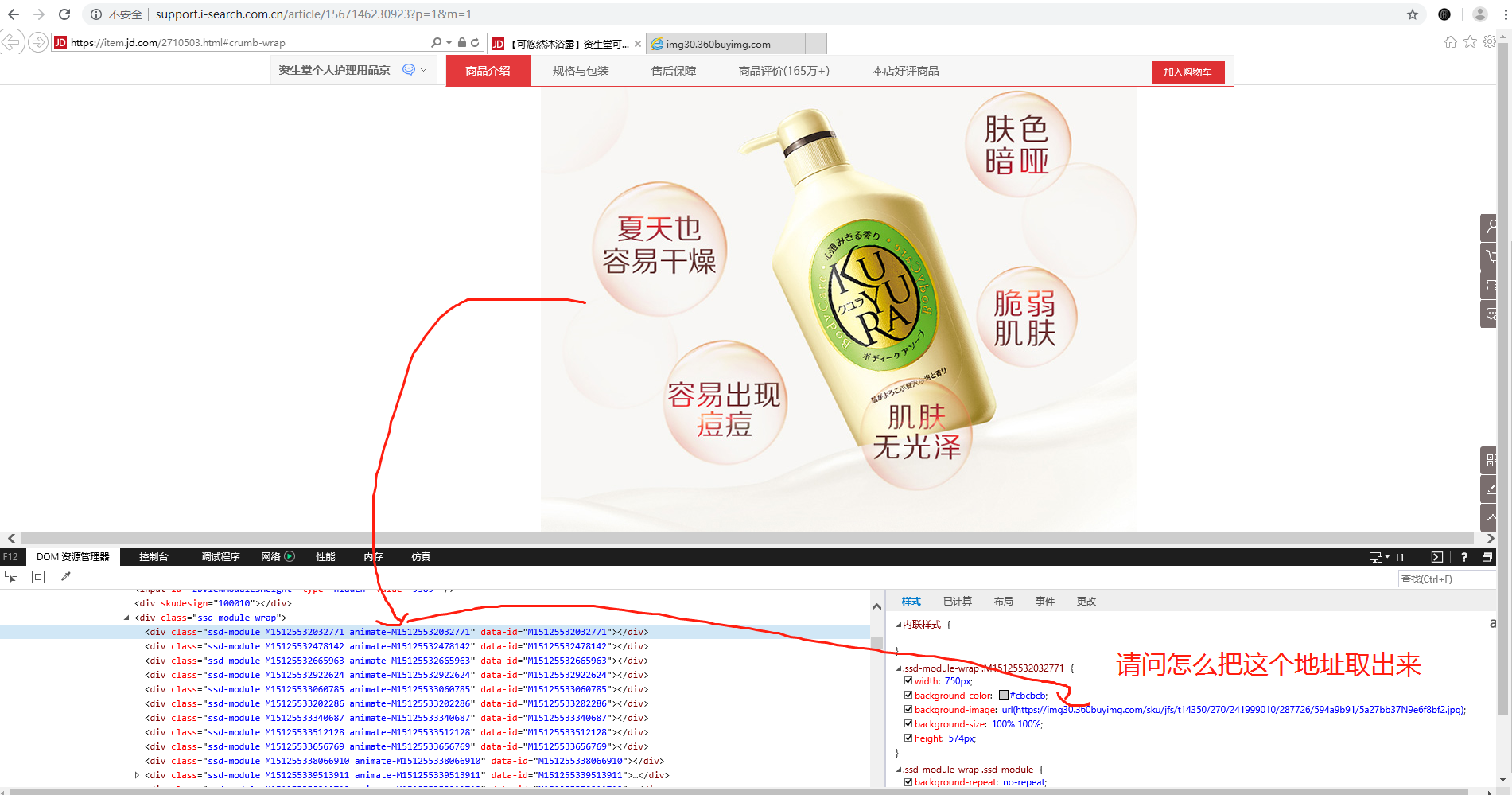
可参考 http://support.i-search.com.cn/article/1538019514108 ,可以百度下有很多方法可以获取 html
您好:
我看了 from bs4 import BeautifulSoup 库,我看是从 html 里面提取属性的。
但是现在我不知道应该怎么样获取下这个 html 里面的内容。
这个要写代码了,试试 from bs4 import BeautifulSoup 库