

RPA 流程制作中藏着哪些 Python 基础知识?
背景
- 安装完 RPA 设计器后,在制作流程过程中,我们可以通过拖拽组件和拾取的方式,来完成我们想要的动作,从而让电脑帮我们做事情;
- 但有时候与同事和在社区里进行交流时,会看到一些没听过的词:
导入、变量、判断条件、列表、字典、循环逻辑等; - 有些词其实是 Python 计算机编程语言中的名词,此帖是模拟从一个刚接触 RPA 和 Python 的角度,以及用简洁易懂的措辞来讲解 Python 基础;
- 本帖力求易懂,故此会存在逻辑不严谨或观念表述不确切的情况,请大家见谅并指正;
版本
- iSRPA 2022.2 版本,请在社区下载并安装,链接: 👉【 https://support.i-search.com.cn/article/1672402098020】 👈
- Python3.6(RPA 设计器自带,
.\ISRPA\Python\目录)
内容
- 本帖中的全部代码,都已上传到【艺赛旗开源仓库】,链接: 🚀 【rpa_py_base.py】 🚀
01、Main.py 是什么?(Python 代码文件)
- #Python 代码和我们常见的
.txt、.docx、.xlsx文件相似,他叫.py文件,使用记事本(等其他文本编辑器)打开后,可以输入任何内容,当然只有符合 Python 语言要求(语法)才能够被识别为代码;
- #如何创建和执行一个 Python 代码文件?
- #新建一个
a.txt文本文件,然后修改文件名为a.py,这就是 Python 文件;(当然也可以使用 VSCode 或 PyCharm 等编辑器) - #使用 RPA 设计器安装目录下的 python.exe 来执行命令:
python.exe a.py即可;- #RPA 设计器安装目录假定在 C 盘(
C:\Program Files\ISRPA\Python\python.exe) - #假设
a.py代码文件在 C 盘(C:\py_learning\a.py) - #需要在【RPA 设计器】底部【控制台】点击【终端】命令行,执行
cd C:\py_learning进入代码所在文件夹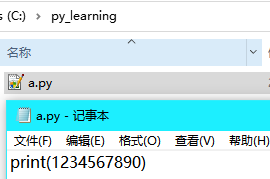
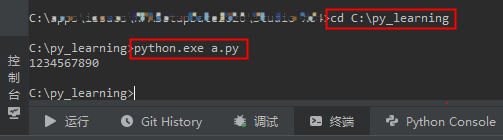
- #RPA 设计器安装目录假定在 C 盘(
- #新建一个
- #RPA 设计器创建的项目,会自动产生一个 Main.py 的文件,可以在设计器左侧栏【我的工程】中,在【项目名称】上右击,在弹出的菜单中点击【打开项目所在文件夹】,可以看到 codes 文件夹下的这个文件
.\codes\Main.py;
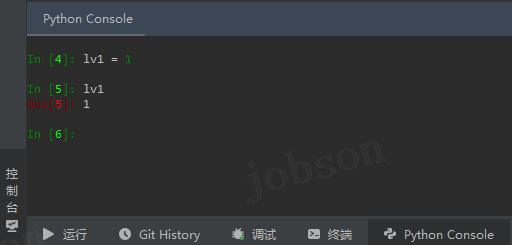
02、如何快速查看代码结果?(Python Console 使用)
- #RPA 设计器底部,控制台,Python Console 标签栏;接下来的代码都可以尝试在此控制台查看运行结果,可不用新建.py 文件来运行;
03、哪些名称能被认识(Python 保留字)
- #暂时不用记住,了解即可,部分后面会写到;
- #RPA 流程中常见关键词:
- 逻辑相关
and、or、is、not、False、True、None、in - 控制相关
if、else、elif、for、while、continue、break - 异常相关
try、except、finally、raise - 函数和类相关
def、class、return - 其他
import、from、as、pass
- 逻辑相关
- #RPA 流程中常见符号
- 运算类
+、-、*、/、=、>、<、==、!= - 语句类
:、(、)、[、]、{、}、,、'、"、#、.
- 非 Python 代码内容,可以使用
#或'''加以注释,帮助理解代码功能# 我是一行注释,解释下面几行代码的 # # 接下来是几个小功能代码的解释 ''' 我是多行注释 使用成对的三个单引号(也可以是三个双引号) 常用于对整个文件的功能简介 '''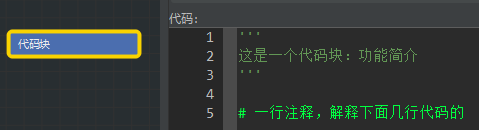
04、流程变量(声明变量与赋值)
- #RPA 设计器左边栏【我的工程】下方,可以添加【流程变量】,可以将组件的返回值“赋值”给【流程变量】;
- #将流程变量拖拽并连线到返回值上,即为【赋值】动作;

- #那在 Python 本身如何声明变量,并给变量赋值呢?
- #声明一个名叫“lv_1”的数字变量:
lv_1 = 1; - #变量的英文名通常叫
variable,设计器中lv大概表示:local variable; - #建议变量名称尽可能的采用英文词语(词意明确),如:
is_check可以使用checked表达已勾选; - #如果只使用拼音(建议全拼并 _ 下划线分隔),如:
yi_gou_xuan;
- #声明一个名叫“lv_1”的数字变量:
05、变量默认值(数据类型)
- #RPA【流程变量】添加后,设计器右侧属性栏,可以设置默认值,例如:
'abc'、123;
- #【流程变量】属性栏默认值可以填写哪些 Python 自带的数据类型?
- #数值
int、float- 整数,
lv_int = 1 - 负数,
lv_int = -1 - 小数,
lv_float = 1.0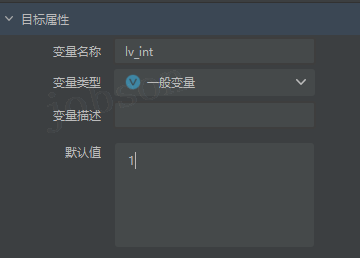
- 整数,
- #数值
- #字符串
str- 单行(单引号),
lv_str = 'abc123你好(){}"...",-=+@!;'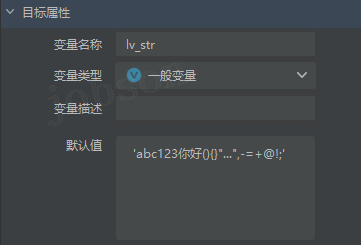
- 多行:
lv_str = '''这是第1行 这是第"2"行 。。。 第'n'行 '''- 单双引号注意点:
'("双引号在里")',"('单引号在里')",'''("双引号在里",'单引号在里')'''!
- 单行(单引号),
- #元组
tuple- 一组固定的有序数据(数组),
lv_tuple = (1, 0, 1, 'a', 'b', 'c')- 访问元素:
lv_tuple[0]和lv_tuple[2]都输出的是1
- 访问元素:
- 一组固定的有序数据(数组),
- #列表
list- 一组可变的有序数据(数组),
lv_list = [1, 0, 1, 'a', 'b', 'c']- 访问元素:
lv_list[-1]和lv_list[-2]分别输出是c和b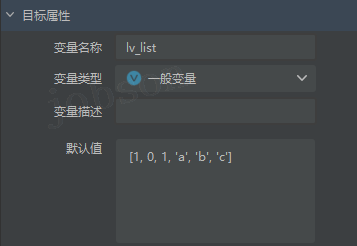
- 访问元素:
- 一组可变的有序数据(数组),
- #集合
set- 一组无重复的可变无序数据(数组),
lv_set = {1, 0, 'a', 'b', 'c'}
- 一组无重复的可变无序数据(数组),
- #字典
dict键→值对应的可变无序的数据(哈希表),lv_dict = {'a': 1, 0: 'b', 1: 'c'}- 访问键值,
lv_dict['a']和lv_dict[0]都输出的是1 和 'b'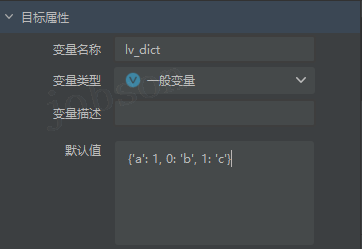
- 访问键值,
- #其他详细的数据类型的方法和数据处理,将在后面写到,如:字符串大写,字符串长度,列表循环遍历,字典键值等;
06、查看变量数据和类型以及转换?(常见函数)
- #打印出变量数据值
print函数,print(lv_int),输出1repr函数,repr(lv_int),输出'1'
- #查看数据类型
type函数,type(lv_int),输出int
- #类型转换
int和float函数,常用于字符串数字转为数值类型,int(lv_str)- 不适合的数据强制转换会报错,如:
int('a') - 小数转换容错,如:
int(float('1.0')),先转为浮点再转为整型
- 不适合的数据强制转换会报错,如:
str函数,把其他类型转为字符串类型,str(lv_int)list函数,常用于把可迭代数据转为列表,list(lv_str)dict函数,常用于字典的初始化,dict(a=1, b=2, c=3)
- #长度
len函数,查看数据长度,适用于:字符串、列表、字典、等数据类型;len(lv_str)、len(lv_list)、len(lv_dict)
07、默认值中拼接其他变量(字符串格式化)
- #普通字符串拼接,
lv_f = f'拼接{lv_int}和{lv_str}。'
- #文件路径拼接,
lv_rf = rf'C:\{lv_int}\a.doc'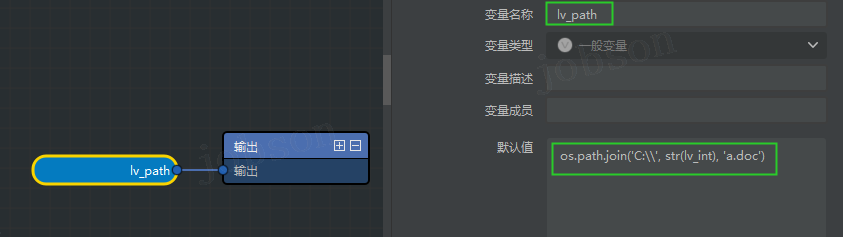
- 建议“针对专有体系”(系统路径)的字符串处理时,使用专有库,如自带的
os.path库:import os.path lv_path = os.path.join('C:\\', str(lv_int), 'a.doc')
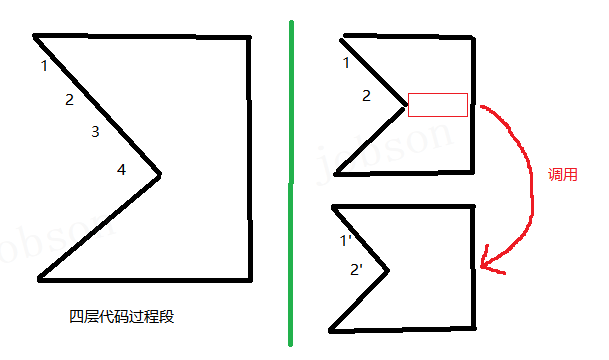
08、RPA 项目中的代码有换行和缩进代表什么?(代码过程段)
- #有的代码换行后为什么会有缩进?(: 冒号的作用)
- 代码和写文档内容(文章)类似,一行上从最左边开始输入;
- 那一直输入肯定不行(语句不通顺),肯定是要【标点符号】的,那 Python 中对应的就是【换行】;
- 其次换行后一直都是从最左侧顶格开始输入的话,那就会没有段落,故此 Python 中有一个【代码过程段】概念;
- Python 中像写文章那样开头空两格代表一个段落,且在结尾用
冒号:来表示下一行新的【过程段】开始; - 同时多个【子过程段】的空格要递增,即:上一层空 4 格的话,那下一次就要空 8 格;
- #Python 代码的层级关系是类似文件夹与子文件夹吗?
- 有一些类似,但会存在一种快捷方式的场景;一共 4 层【过程段】,可以连续新建 4 层嵌套文件夹;也可以新建 2 个 2 层嵌套文件夹,然后在第一个文件夹内放入另外一个文件夹的快捷方式;
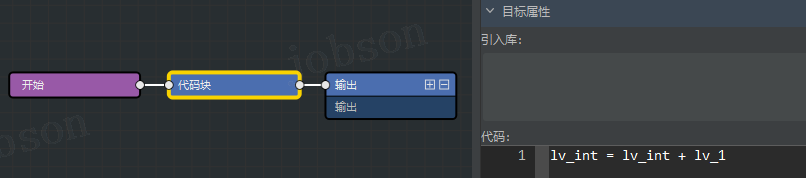
- #为什么修改设计器中的【代码】后,再运行就会消失?
- 设计器运行(F5)或编译(F9)后,Main.py 代码文件会根据组件重新写入代码;
- 故此可以将“新增的代码”使用【代码块】组件,然后将此组件连接到“流程画布”中;
09、不同条件执行不同流程(IF 分支)
- #分支条件怎么写?
- 设计器中【IF 分支】组件,默认有一个条件 1 和对应 2 个分支:条件为真时、条件为假时;
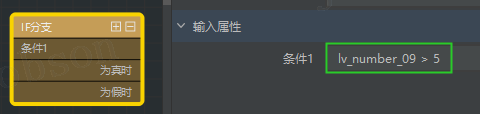
- 设计器中【IF 分支】组件,默认有一个条件 1 和对应 2 个分支:条件为真时、条件为假时;
- 【IF 分支】组件右侧属性栏中,条件 1(不带单引号)输入:
lv_number_09 > 5# 判断输入的个位数是否大于5 # 假设输入的数字是5 if lv_number_09 > 5: print(f'数字{lv_number_09}大于5') elif lv_number_09 == 5: print(f'数字{lv_number_09}等于5') else: print(f'数字{lv_number_09}小于5')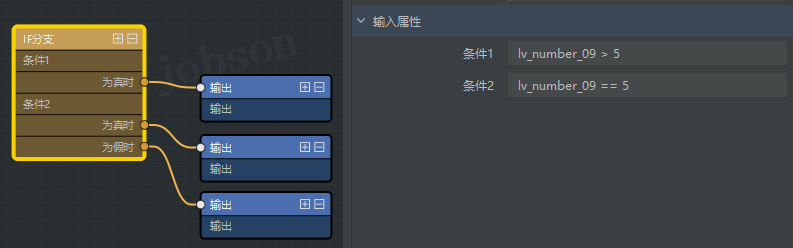
- #这条分支什么都不做(pass)
- 设计器中拖拽一个【Pass 空语句】

- 对应的 Python 代码:
if lv_number_09 >= 5: pass else: print(f'数字{lv_number_09}小于5') - 设计器中拖拽一个【Pass 空语句】
- #结合变量赋值(if…else…)
- 如果超过 5 就是
大否则小,lv_bl = '大' if lv_number_09 > 5 else '小'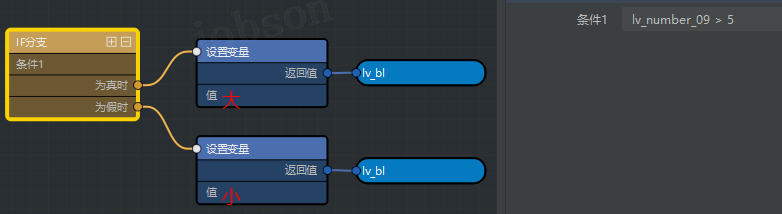
- 如果超过 5 就是
- #其他常见的逻辑条件写法
- 包含:
1 in [1, 2, 3] - 不包含:
1 not in [1, 2, 3] - 等于:
1 == 1 - 不等于:
1 != 1 - 是‘真’:
0 is True - 是‘假’:
0 is False - 是‘空’:
0 is None - 不是‘空’:
0 is not None - 等于‘空字符’:
0 == '',不能写成0 is ''
- 包含:
10、取出一组数据中的每一个元素(For 循环)
- #手动创建列表并逐个取出显示

for i in [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]: print(i) - #或者使用变量传递,再逐个取出显示
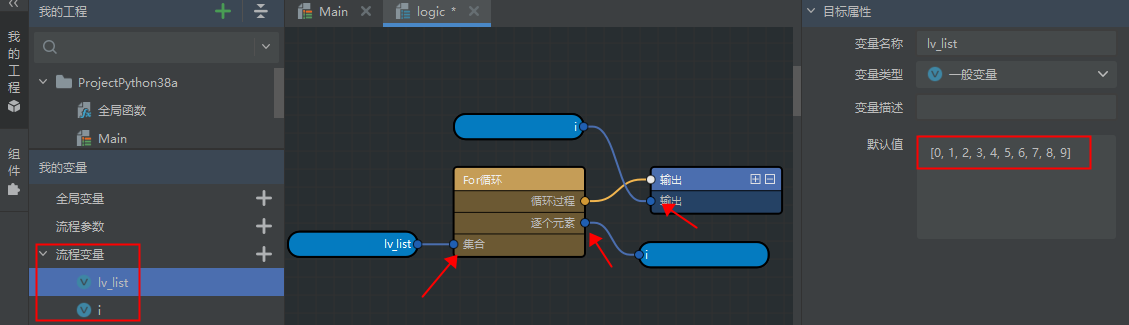
- #除了手动生成一个列表集合外,还可以使用
range()函数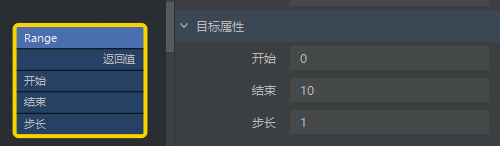
- 生成 0-9 的列表:
range(10) - 生成 10-19 的列表:
range(10, 20)
print([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) print(list(range(10))) print(list(range(10, 20))) - 生成 0-9 的列表:
- #逐个元素

# 逐个取出0-9的数字 for i in range(10): print(i)
- #带上序号
# 逐个取出abc的序号和值 for number, value in enumerate(['a', 'b', 'c']): print(number, value) # 输出 0 a 1 b 2 c
- #跳过特定元素(continue)

for i in range(10): # 如果是奇数则跳过 if i % 2: continue print(i)
- #找到想要的元素则结束循环(break)

for i in range(10): # 如果超过5则退出,只要0-5的数字 if i > 5: break print(i)
11、多执行几次直到成功再继续(While 循环)
-
#设定结束条件(while True)
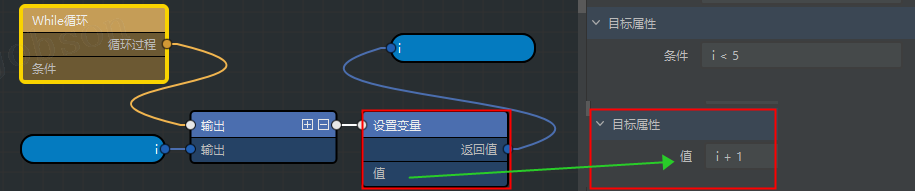
-
#当不满足
i < 5条件时则结束循环,继续下面的代码;i = 0 while i < 5: print(i) i = i + 1 print(i) # 输出:0、1、2、3、4、5
-
#执行到一半重头开始(continue)

-
#在满足
i < 5条件前提下,当变量i == 3时则不输出变量;i = 0 while i < 5: i = i + 1 if i == 3: continue print(i) print(i) # 输出:1、2、4、5、5
-
#提前触发结束继续下面的流程(break)

-
#在满足
i < 5条件前提下,当变量i == 3时则不输出接下来的变量i = 0 while i < 5: i = i + 1 if i == 3: break print(i) print(i) # 输出:1、2、3
12、如果执行有报错怎么办?(Try 异常)
- #为了模拟一些场景,介绍一个 Python 自带模块:
random,用来产生一些随机数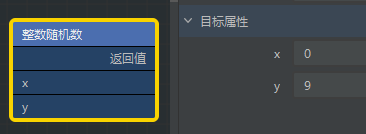
# 随机出一个0-9的数字 import random print(random.randint(0, 9))
-
#试一试,如果没报错最好(except)
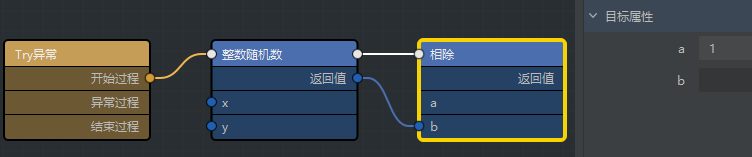
-
#使用
1 / 一个随机数,如果分母是 0 则会报错try: number = random.randint(0, 9) print(number, 1 / number) except: pass finally: pass
- #看一看报错是什么(Exception)
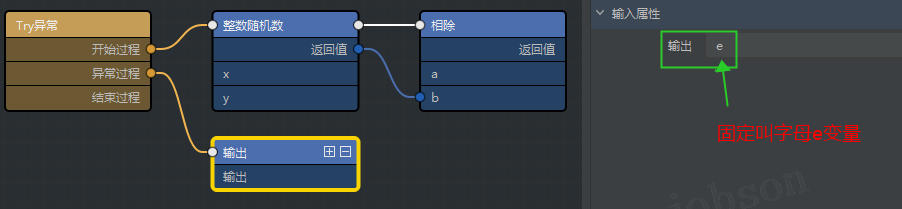
try: number = random.randint(0, 9) print(number, 1 / number) except Exception as e: print(e)
- #报错了也不管,仍然需要执行(finally)
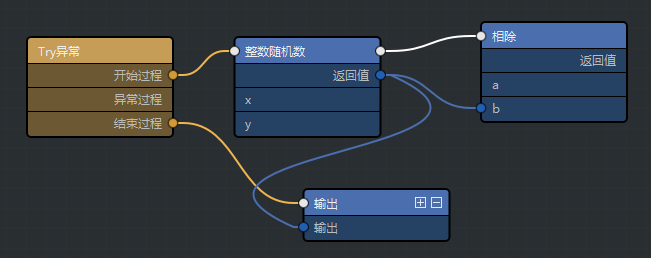
try: number = random.randint(0, 9) print(number, 1 / number) finally: print(number)
- #设定自己特有的报错信息(raise)
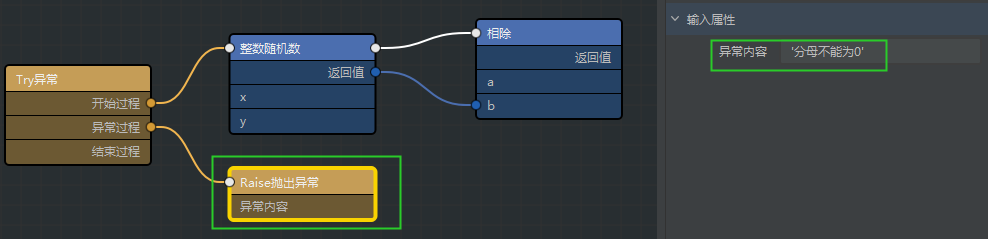
try: number = random.randint(0, 9) print(number, 1 / number) except Exception as e: raise Exception(f'分母不能为0,{e}')
13、把代码块里的复杂功能整理一下(全局函数)
全部代码可以像以上内容那样,都放在一个文件里,并且像瀑布那样从上到下依次执行;随着代码越来越多(超过 500、1000、3000),那将是比较庞大且“混乱”的;那如果像切蛋糕一样,分成一小块一小块的,放在旁边摆好,需要执行哪一块再拿过来,这样的分块方法就是【函数】。
- #函数定义与返回值
def function_name(param_name1, param_name2): '''函数说明,参数入参数量:0个-N个 param_name1 入参参数1说明 param_name2 入参参数2说明 ''' # 一块代码 # 假设这里有30行 argument_name = f'{param_name1}, {param_name2}' # 返回出参,返回值个数:1个或N多个,默认返回值None return argument_name
- #函数调用与入参
new_name = function_name('A', 'B') print(new_name) # 输出:'A, B'字符串
- #流程参数怎么用?
RPA 设计器中的一个【子流程】,相当于是一个【函数】,那么在【子流程】中添加的【流程参数】,也就是这个【函数】的【入参】,想要调用该【子流程(函数)】时,就需要传递【流程参数(入参)】;默认情况下【子流程】是没有【流程参数】的。
def logic(pv_1, pv_2): '''名为logic的子流程''' pass # 主流程中调用子流程 result = logic(1, 2)
- 怎么在代码块里使用全局函数和自定义函数?
先定义全局函数(双击左侧栏【全局函数】菜单),添加名为 sum 和 inc 两个【函数】,然后在面板画布上添加【全局函数】组件,并选择 sum 函数,填写所需参数。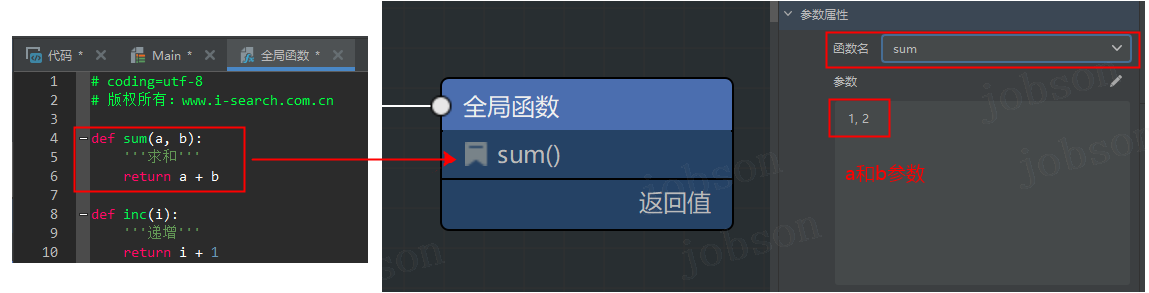
- 代码块中使用全局函数和自定义函数,代码块中自定义的【函数】只能在本代码块使用!
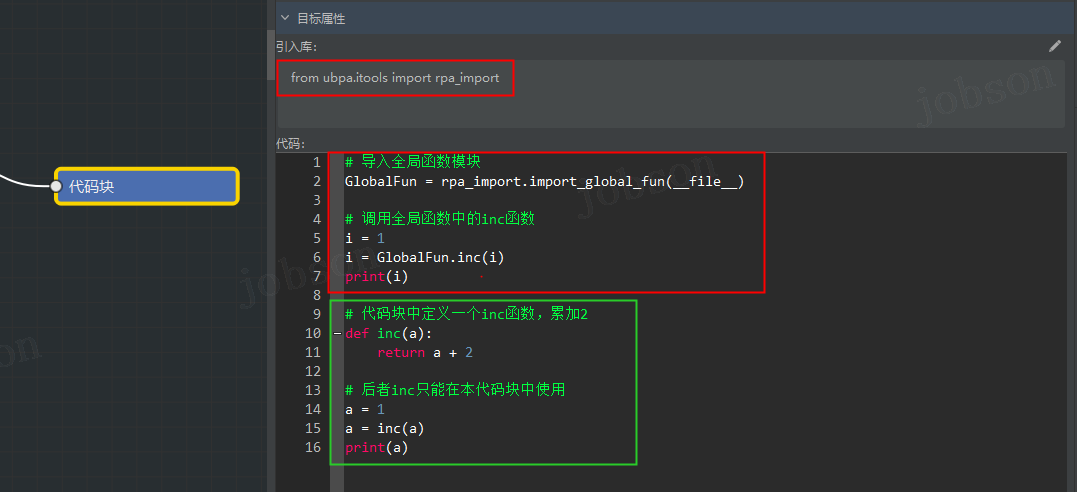
from ubpa.itools import rpa_import # 导入全局函数模块 GlobalFun = rpa_import.import_global_fun(__file__) # 调用全局函数中的inc函数 i = 1 i = GlobalFun.inc(i) print(i) # 输出:2 # 代码块中定义一个inc函数,累加2 def inc(a): return a + 2 # 后者inc只能在本代码块中使用 a = 1 a = inc(a) print(a) # 输出:3
- #关于函数还有:参数默认值,限定参数数据类型,限定函数返回值类型,不确定参数,多返回值与接收,函数内外变量作用域,等;感兴趣的可以进一步在社区搜索学习。
14、如何使用 import 导入自带库(import 第三方库)
- #导入 Python 自带的库
# 自带的库是不用额外安装的,如:sys、os、time、datetime等 # 一般在.py文件代码的顶部导入 import os import sys import time from datetime import datetime # from ... import ...的用法是将import的模块所在路径放入from中, # 这样同路径的模块即可放在一起导入,例如: import ubpa.iexcel as iexcel import ubpa.iimg as iimg import ubpa.ijava as ijava # 可以合并在一起导入: from ubpa import iexcel, iimg, ijava
- #导入第三方库
需要先安装才可以导入成功,第三方库安装方法详见另一贴(链接):【 如何在 iSRPA 设计器中安装第三方 Python 库? 】# 在原生Python安装第三方库命令(cmd命令行),已pandas为例:pip install pandas # 安装完成后即可导入 import pandas as pd # as 是给pandas取一个别名的意思,即简化长名称库的使用。 # 例如RPA设计器中常看到的: import ubpa.iautomation as iautomation # 可以取个别名: from ubpa import iautomation as ia
- #导入自行复制到项目 codes 目录的 py 模块
将上面【全局函数】中的代码,放入一个叫global_func.py代码文件中,并保存到项目的 codes 目录: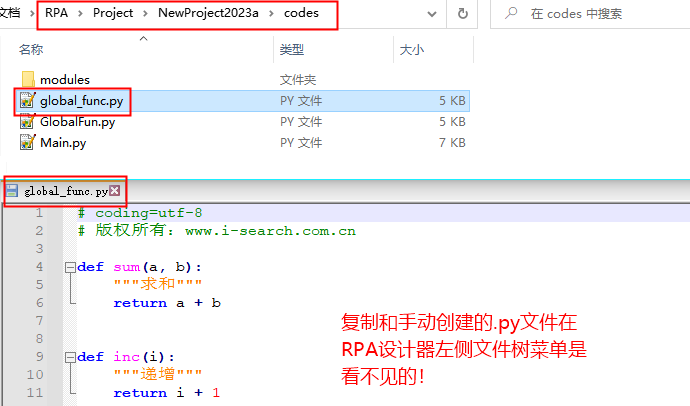
# 直接导入codes目录下的global_func模块 import global_func a, b = 1, 1 c = global_func.sum(a, b) print(c) # 输出:2
- #RPA 常用的库
- 自带的:
os、sys、time、datetime、pathlib、json、re、等 - 第三方:
python-dateutil、requests、pandas、numpy、等 - 社区有贴主发的很不错,请阅读了解更多的库(及其作用):【 分享个非常非常实用的 python 进阶 】
- 自带的:
15、使用代码块对常用数据快速处理(字符串、列表、字典)
- #字符串方法
s = ' i-search iS-RPA ' # 字符替换(去除全部空格) print(s.replace(" ", "")) # 输出'i-searchiS-RPA' # 去除首尾空格(还有对应的l左边和r右边空格) print(s.strip()) # 输出'i-search iS-RPA' # 分割字符串为列表,默认按空格分割,可以指定分隔符 print(s.split()) # 输出['i-search', 'iS-RPA'] print(s.split(" ")) # 输出['', 'i-search', 'iS-RPA', ''] # 将字符串统一转为小写lower或大写upper,降低字符串比较错误 print("aBc".lower() == "abc") # 返回True # 判断字符串以什么内容开头startswith或结尾endswith(比如判断文件格式) print("a.docx".endswith(".docx")) # 返回True # 字符串间拼接 r, p, a = 'R', 'P', 'A' print(r + '-' + p + '-' + a) # 加法运算符+拼接 print(f'{r}-{p}-{a}') # 字符串格式化符f拼接 # 将字符串列表拼接为字符串 print("-".join(['R', 'P', 'A'])) # 输出'R-P-A' # 字符串还有很多方法,可以使用自带的函数dir来查看字符还有哪些方法 print(dir(s))
- #列表方法
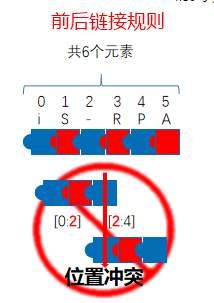
lv_list1 = ['i', 'S', '-'] lv_list2 = ['R', 'P', 'A'] # 列表拼接 print(lv_list1 + lv_list2) # 输出['i', 'S', '-', 'R', 'P', 'A'] words: list = list("iS-RPA") # 等同words = ['i', 'S', '-', 'R', 'P', 'A'] # 取、改 words[0], words[len(words) - 1], words[-1] # 取值'i', 'A', 'A' words[0] = 'I' # 修改第一个元素的内容,从'i'改为'I' # 增、删 words.insert(0, '('), words.append(')') # 首、尾添加元素 words.remove('S'), words.pop(0) # 按“值、索引”删除其中1个元素 # 排序 sorted(words, reverse=False) # 正、反排序,reverse默认为True(正序) list(reversed(words)) # 颠倒顺序,并不排序 # 切片,从开始到结尾前(不含结尾,遵守链接规则) words: list = list("iS-RPA") print(words[0:2], words[2:4], words[4:6]) # ['i', 'S'] ['-', 'R'] ['P', 'A'] print(words[0:6:2]) # 往后2个索引取一次值,['i', '-', 'P'] - #字符串也支持此切片规则,但字典不支持切片!
- #字典方法
words: dict = dict(R=0, P=1, A=2) # 等同words = {'R': 0, 'P': 1, 'A': 2} # 字典是无序的,不支持切片,且key不能是可变数据(比如:{[1,2,3]: 'ABC'}) words['C'] = 3, words.pop('C', 3) # 添加和删除元素 words.update({"R": 1, "C": 4}) # 更新字典{'R': 1, 'P': 1, 'A': 2, 'C': 4} print(words['C']), words.get('C', 3) # 取值,建议使用get方法(key不存在就返回默认值3) print(words.keys(), words.values()) # 获取所有key和所有value # ['R', 'P', 'A', 'C'] [1, 1, 2, 4] list(words.items()) # 成对获取key和value,[('S', 0), ('N', 1), ('P', 2)]
16、RPA 流程制作中常用的模块和函数简述
- #
open函数读写文本文件# 常用来在运行过程中存储中间过程数据 # 文件有很多打开模式,一般是读(r)和写(w),更多模式查看此链接 # https://www.runoob.com/python/file-methods.html # 创建一个1.txt文件并写入'abc'字符串 with open('1.txt', 'w') as fp: fp.write("abc") # 读取1.txt文件 with open('1.txt', 'r') as fp: print(fp.read()) # 常用的读是r+模式(避免文件不存在而读取报错); # 追加写入a+模式(项目过程变量追加存储)
- #
os.path模块# 常用于拼接和获取(处理)路径,流程制作中可以处理路径类的流程变量和组件返回结果。 import os # 拼接文件路径:'C:\\work\\a.doc' path = os.path.join('C:\\', 'work', 'a.doc') # 拆分出:目录、文件 directory, file = os.path.split(path) # ('C:\\work', 'a.doc') # 等同于: directory = os.path.dirname(path) # 'C:\\work' file = os.path.basename(path) # 'a.doc' # 拆分出文件的名称和扩展名 file_name, extension_name = os.path.splitext(file) # 'a', '.doc' # 路径是否存在,文件、文件夹 os.path.exists(path) # 返回True存在、False不存在 # 判断路径是否文件夹或文件,前提是路径要存在,不存在都是False os.path.isdir(path) os.path.isfile(path)
- #
time模块# 常用于计算时间戳和延时执行 import time start_time = time.time() # 获取当前时间戳 time.sleep(2) # 延时2秒执行接下来的语句 print(time.time() - start_time) # 计算运行时长,大约是2秒多一点
- #
datetime与dateutil模块# 常用来在RPA设计器中获取日期和时间,以及格式化日期和时间 from datetime import datetime from dateutil.parser import parse # 当前日期时间 now = datetime.now() print(now.date(), now.time()) # 日期时间格式化显示,更多格式化字符含义,查看此链接 # https://www.runoob.com/python/python-date-time.html print(now.strftime('%Y-%m-%d %H:%M:%S')) # 日期字符串,转为日期对象(datetime),格式不对应会报错 dt = datetime.strptime('2023-01-01 00:30:59', '%Y-%m-%d %H:%M:%S') # 使用dateutil模块快速解析出日期对象(datetime) print(parse('2023-01-01 00:30:59')) print(parse('2023-01-01 00:30')) print(parse('2023-01-01')) # 日期间比较 print(parse('2023-01-01') > parse('2023-01-02')) # False
- #
json模块# 常用来解析json字符串内容,多用于读取RPA项目配置中的json配置文件 import json json_str = """ { "a": 1, "b": 2, "c": 3 } """ # 将json字符串转为dict字典类型数据 data = json.loads(json_str) print(data) # 输出:{'a': 1, 'b': 2, 'c': 3} # 将dict字典转换为json字符串 data_json = json.dumps(data) print(data_json) # 输出:'{"a": 1, "b": 2, "c": 3}'
- #
pandas.DataFrame模块 - RPA 设计器中有些组件的返回值就是此类型,DataFrame 有点类似于 excel 的数据表格,如图:
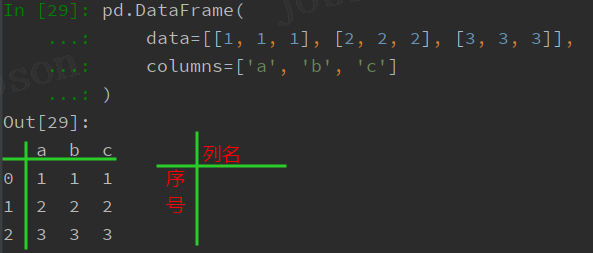
# DataFrame有点类似于excel的数据表格,更多内容浏览该链接: # https://www.runoob.com/pandas/pandas-tutorial.html import pandas as pd # 创建一个DataFrame数据 df = pd.DataFrame( data=[[1, 1, 1], [2, 2, 2], [3, 3, 3]], columns=['a', 'b', 'c'] ) print(df) # 取出一列转为列表 print(df["a"].to_list()) # 新增一列 df["d"] = [4, 4, 4] print(df) # 取出第一行转为列表,行从0开始计数 print(df.loc[0].to_list()) # 取出(第三行,b列)单元格内容 print(df.loc[2, 'b']) # 输出:3 # 导出为excel表格 df.to_excel("1.xlsx", index=False) # 从excel导入数据为DataFrame df = pd.read_excel("1.xlsx") print(df)
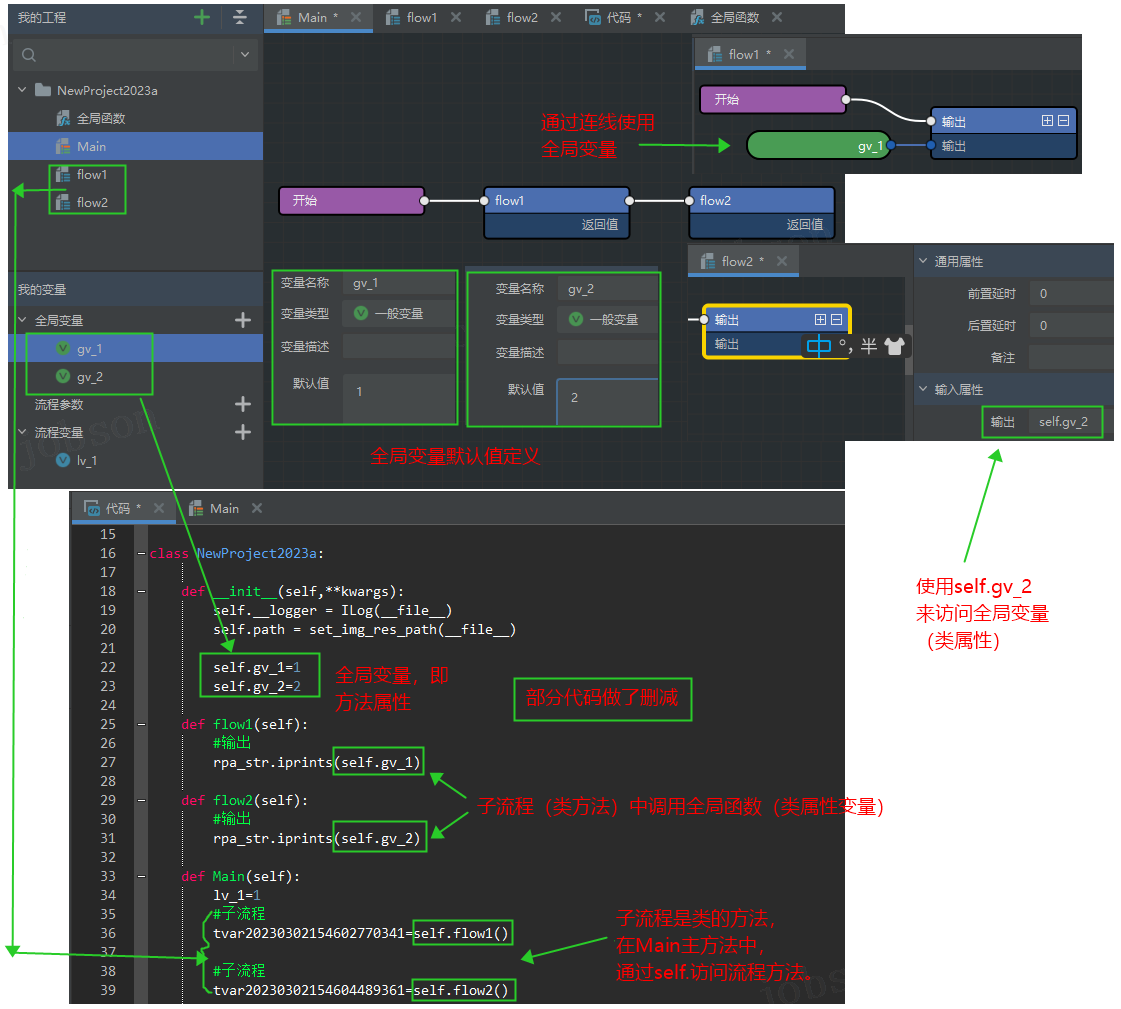
17、全局变量使用时为什么是 self. 开头?(对象声明与实例化)
- #有了函数为什么需要类?
把管理代码,比喻成管理超市里的物品,超市会把商品分类,不同类的商品信息会有差异,每日整理的方式也不同;例如蔬菜和水果要按斤称重,且要每日摘去不适合销售的部分;薯片和饮料按件计费,可能半月才会查一次是否过期。故此,我们应当把执行类似或有关联的功能代码(函数)放在一类,比如处理日期的,处理字符串的,统计社区优质帖的,等等。一个超市: 超市名称 = 汪旺超市 超市地址 = 大黄路 今日总优惠 = 9.5折 蔬菜水果区: 今日特别优惠 = 9.0折 每日检查损耗 副食饮料区: 今日无优惠 每月检查过期
- #如何声明一个类
class?class NewProject2023a: """一个RPA新项目""" def __init__(self): """初始化方法 固定参数叫self,表示类自己 """ # 定义类属性(也就是RPA的全局变量) self.path = __file__ def main(self): """主方法,一般方法名称小写开头 在每一个方法中都可以使用类本身(self)的属性(变量) """ lv_1 = 1 print(lv_1) # 使用self.来访问类属性 print(self.path) # 类的更多信息,查看链接:https://zhuanlan.zhihu.com/p/426006204
- #如何实例化并使用类方法和属性?
# 实例化对象 pro = NewProject2023a() # 调用类方法(与函数区分)和属性 pro.main() print(pro.path)
- #RPA 中 Main.py 哪里有类的影子?
注意
- #更多两个下划线开头的是什么?(
__file__,__init__,__name__, 等)- 获取当前.py 所在文件路径:
__file__ - 初始方法(文件):
__init__ - 判断是否在当前.py 文件内运行:
__name__ == '__main__' - 更多双下划线(魔法方法和变量),请查看此链接:
- http://www.coolpython.net/python_senior/senior_oop/py-magic-method.html
- 获取当前.py 所在文件路径:

👍 👍 👍