

用 ISRPA 实现:爬取网页文章到自己的网站中
扒拉别人文章到自己网站的做法通常叫:采集。
为什么要扒拉别人的内容? 为了收录和排名。
今天探讨下 ISRPA 下怎么采集。
上思路,上代码。
思路
过往的 CMS 系统可针对个别网站特点将固定的内容采集到自己的 CMS 里,代码量高、可维护性差。
自从有了 ISRPA,大大缩小的代码量、可用性更高。
下面通过以下三个步骤简述采集思路。
- 抓取文章地址;
- 抓取文章标题和内容;
- 更新到 CMS;
第一步:获取文章地址

获取到的文章地址,被一行行写入文本。
代码实现
1.1 预览流程

1.2 先看下文章列表(截图仅为举例):
1.3 再看下文章翻页:
每页十篇文章,总计 264*10 篇;
1.4 观察每页的规律
第一页:
第二页:
很快,总结文章列表地址的规律(列表页的页码和地址最后的位数对应):
www.XX.com/zhucegongsi/0-1
www.XX.com/zhucegongsi/0-2
…
www.XX.com/zhucegongsi/0-10
每页 10 篇文章,10 页就 100 篇。
1.5 列表中每篇文章的格式

以上是页面的内容,以下是 HTML 代码的格式

可发现,每个li里包含一个地址;要把a标签中的href抓取出来;
1.6 设计思路:双层循环
外层循环,打开十个列表页,内层循环,抓取每页中的十个地址;
代码简述
2.1 自增变量和地址格式化
先循环起来,设置自增变量 i,i>10 时,跳出循环;
地址格式化:'http://www.xx.cn/gongsiqiming/0-{}'.format(i), 根据列表页规律,循环打开每一页;
2.2 打开指定文本
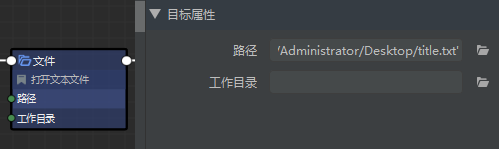
抓取到的地址要写入文本。
2.3 循环抓取文章代码块
内层循环变量j,j 自增;
根据路径规律,格式化路径变量 li_path:'body > DIV:nth-of-type(1) > DIV:nth-of-type(1) > UL:nth-of-type(2) > LI:nth-of-type({})'.format(j)
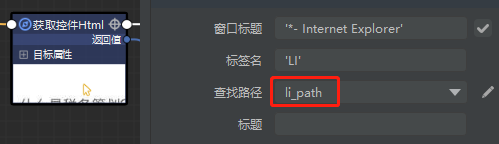
通过‘获取控制 HTML’抓取每篇文章中的 li块代码,赋值给 li_html;
2.4 从抓取的代码块中过滤出地址,使用正则匹配,匹配结果赋值给 l_href。
使用re模块,匹配出href。re.findall(r'href="(\S+)"',li_html)[0]
2.5 将匹配的地址写入文本

五件组件的意思:获取块代码,过滤 href,激活文本窗口,写入 href,回车换行;
看这个实例:
如何过滤通过“获取控件 html”组件获取的代码,比如:抽取 A 标签的 href 属性值
第二步:获取文章标题与内容

获取到的文章,被一个个放入指定文件夹。
代码实例
看这个实例 如何通过一篇文章的 URL 抓取标题和内容
第三步:更新到自己的 CMS 中
将文章一个个读取,再发布到自己网站中。
