

如何过滤通过“获取控件 html”组件获取的代码,比如:抽取 A 标签的 href 属性值
通过“获取控件 html”组件,能获取一段 html,如下:
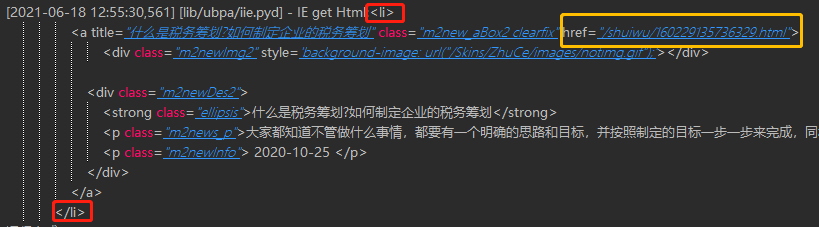
获取到一段 li 标签的代码,现在我只想获取这段代码中的 a 标签里的 href 属性的值 。 即链接地址。
自己研究了一下,思路是:
将返回的 html 赋给变量,用正则匹配 URL,再赋给变量

正则需要引入 re 模块。
获取到的 html 形如:
<a title="什么是税务筹划?如何制定企业的税务筹划" class="m2new_aBox2 clearfix" href="/shuiwu/160229135736329.html">
<div class="m2newImg2" style='background-image: url("/Skins/ZhuCe/images/notimg.gif");'></div>
<div class="m2newDes2">
<strong class="ellipsis">什么是税务筹划?如何制定企业的税务筹划</strong>
<p class="m2news_p">大家都知道不管做什么事情,都要有一个明确的思路和目标</p>
<p class="m2newInfo"> 2020-10-25 </p>
</div>
</a>
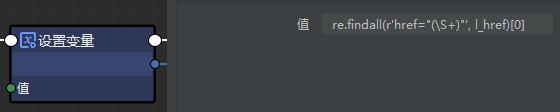
把 html 结果赋给变量 l_href
需求是抓取这里面的 href 即: /shuiwu/160229135736329.html
使用正则匹配 href="(\S+)"
使用 findall 函数抓取,函数返回列表,所以取值[0], 就有了如下:
re.findall(r'href="(\S+)"', l_href)[0]
得到的结果是: /shuiwu/160229135736329.html , 如下:


😂 大佬,收下我的膝盖