

正则表达式使用系列(六)贪婪模式与非贪婪模式
贪婪模式与非贪婪模式
贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 (*);
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 (?);
Python 里数量词默认是贪婪的。
示例一
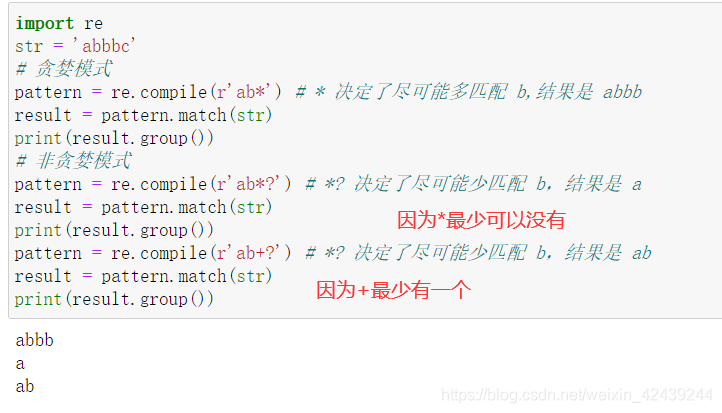
import re
str = 'abbbc'
# 贪婪模式
pattern = re.compile(r'ab*') # * 决定了尽可能多匹配 b,结果是 abbb
result = pattern.match(str)
print(result.group())
# 非贪婪模式
pattern = re.compile(r'ab*?') # *? 决定了尽可能少匹配 b,结果是 a
result = pattern.match(str)
print(result.group())
pattern = re.compile(r'ab+?') # *? 决定了尽可能少匹配 b,结果是 ab
result = pattern.match(str)
print(result.group())
示例二
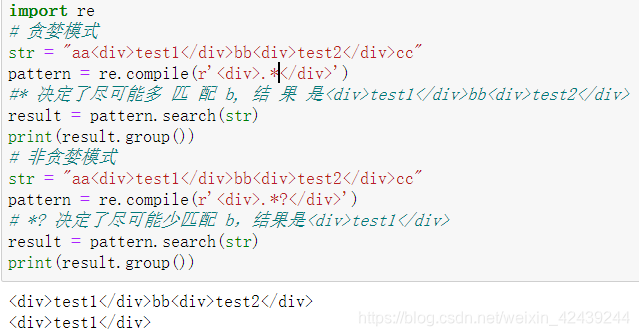
import re
# 贪婪模式
str = "aa<div>test1</div>bb<div>test2</div>cc"
pattern = re.compile(r'<div>.*</div>') #* 决 定 了 尽 可 能 多 匹 配 b, 结 果 是
<div>test1</div>bb<div>test2</div>
result = pattern.search(str)
print(result.group())
# 非贪婪模式
str = "aa<div>test1</div>bb<div>test2</div>cc"
pattern = re.compile(r'<div>.*?</div>') # *? 决定了尽可能少匹配 b,结果是<div>test1</div>
result = pattern.search(str)
print(result.group())
正则表达式测试网址
http://tool.oschina.net/regex/
匹配中文
中文的 unicode 编码范围 主要在 [u4e00-u9fa5] (全角(中文)标点等除外),丌过,
在大部分情况下,应该是够用的。
假设现在想把字符串 title = u’你好,hello,世界’ 中的中文提取出来,可以这么做:
import re
title = '你好,hello,世界'
pattern = re.compile(r'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print(result)
正则表达式学习传送门:
正则表达式使用系列(一)生成 Pattern 对象
正则表达式使用系列(二)match 方法
正则表达式使用系列(三)search 方法
正则表达式使用系列(四)findall 方法
正则表达式使用系列(五)finditer、split、sub 方法

回帖内容已被屏蔽。
可以,写的越来越好了啊
,向你学习!