


Ocr 识别代码重构——方便 7.0 版本使用 8.0 新增的艺赛旗接口
- 现在艺赛旗自行提供验证码、OCR 等识别的 saas 服务,现在在线接口改为向艺赛旗服务器请求服务
8.0 新增了更加强大的 ocr 识别,但库中的代码只提供了简单的功能,因此决定重构一下代码。
首先查看 ubpa.iocr 可知目前的 ocr 识别一共分为艺赛旗接口、百度接口、谷歌 tesseract 以及云打码平台这几种。
对应到控件中是这样:
其中获取 OCR 文本、身份证 OCR、营业执照 OCR 为艺赛旗接口,如果出现异常则换成调用百度接口;验证码对应云打码平台;滑动验证码也为艺赛旗接口,但出现异常不会切换成百度接口。
对同一张倒着的图片分别调用艺赛旗的 general_recognize()函数和百度的 bd_general_recognize() 函数发现结果一致,猜测艺赛旗自行提供的接口与百度类似,因此尝试在原函数上增加百度通用文字识别的功能。
原函数代码如下:
#通用文字识别
def general_recognize(image_path=""):
__logger.info(u"Ready to execute [general_recognize]")
text=""
try:
client = get_client()
image = get_file_content(image_path)
data = client.basicGeneral(image)
__list=data['words_result']
list_str = []
for index in range(len(__list)):
dict_str=__list[index]
list_str.append(dict_str['words'])
text = ''.join(list_str)
return text
except Exception as e:
__logger.error('First recognition error:'+str(e))
bd_general_recognize(image_path)
finally:
__logger.debug('[general_recognize] result :[' + text + ']')
__logger.echo_msg(u"end execute [general_recognize]")
涉及参数传递的地方都在 ubpa\iip\ocr.py 文件中,而文件的 IipOcr 类又继承了 ubpa\iip\base.py 文件中的 IipOcrBase 类,非常复杂,将其重构后增加功能就比较方便了。
重构后的通用文字识别函数如下:
def general_recognize(self, language_type='CHN_ENG', detect_direction='true', detect_language='false', probability='true', probability_value=0.6): # 通用文字识别
__logger.info(u"Ready to execute [general_recognize]")
data = {}
options = {}
options["language_type"] = language_type
'''识别语言类型,默认为CHN_ENG。
可选值包括:CHN_ENG:中英文混合;
ENG:英文;
POR:葡萄牙语;
FRE:法语;
GER:德语;
ITA:意大利语;
SPA:西班牙语;
RUS:俄语;
JAP:日语;
KOR:韩语;'''
options["detect_direction"] = detect_direction # 是否检测图像朝向,默认不检测
options["detect_language"] = detect_language # 是否检测语言,默认不检测。当前支持中文、英语、日语、韩语
options['probability'] = probability
data.update(options)
try:
image = get_file_content(self.img_path)
data['image'] = base64.b64encode(image).decode()
obj = self._request(self._generalBasicUrl, data)
data_dict = json.loads(json.dumps(obj))
_list=data_dict['words_result']
if probability == 'true':
list_str = []
for index in range(len(_list)):
words = _list[index].get('words')
probability = _list[index].get('probability').get('min')
if probability < probability_value: # probability_value为置信度阈值
pass
else:
list_str.append(words)
text = list_str
else:
list_str = []
for index in range(len(_list)):
dict_str=_list[index]
list_str.append(dict_str['words'])
text = '\n'.join(list_str)
return text
except Exception as e:
__logger.error('First recognition error:'+str(e))
bd_general_recognize(image_path)
finally:
__logger.debug('[general_recognize] result :[' + text + ']')
__logger.echo_msg(u"end execute [general_recognize]")
加入了识别语言类型、检测图像朝向、输出置信度的功能。
对于一张倒着的图片,识别效果如下:

完整代码在 Iocr.py 文件中,使用时直接拷贝至项目文件夹中的 codecs 文件夹下,然后新增代码块,在引入库中输入 import Iocr,就可以在下面的代码一栏中进行调用了。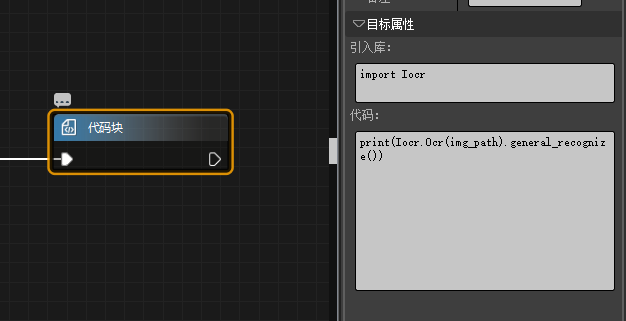
3e755bb66a0e4af0b3955cbc4c546f65_Iocr.py
.py 文件下载后删掉第 167 行的内容:
——WebKitFormBoundaryKNhEQsjrTd5Q8C3e–

给哈哈大佬点赞
这个就是为了方便没控件或者没有相关库的情况下调用的,可以拿 7.0 的设计器尝试一下
有的吧,在 OCR 组件内,你确定你是 8.0 么 😆
我 8.0 版本没这个控件
👍🏻