

在网页中的可变元素如何准确定位
网页中,我们拾取的时候,关键目标属性如下: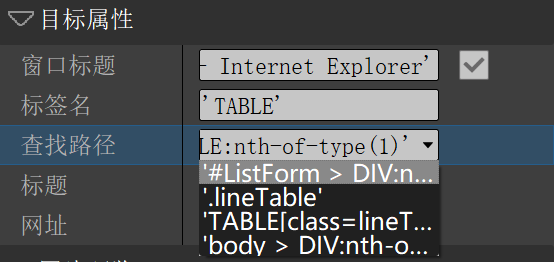
可以看到,首先系统会定位窗口标题,然后系统会定位标签名,这个例子是TABLE,网页代码中是<TABLE xxxxxxx>,系统会匹配路径(selector),其实这里面,我们基本兼容的 CSS selector,大家可以在百度查找一下这个概念
要注意的是,如图所示,我们自动生成的 selector 有 4 中,你可以在里面切换
也可以自己学习 selector,尝试观察我们要的目标的唯一性
在网页检查 / 审查小技巧中,我们可以检查元素,例如: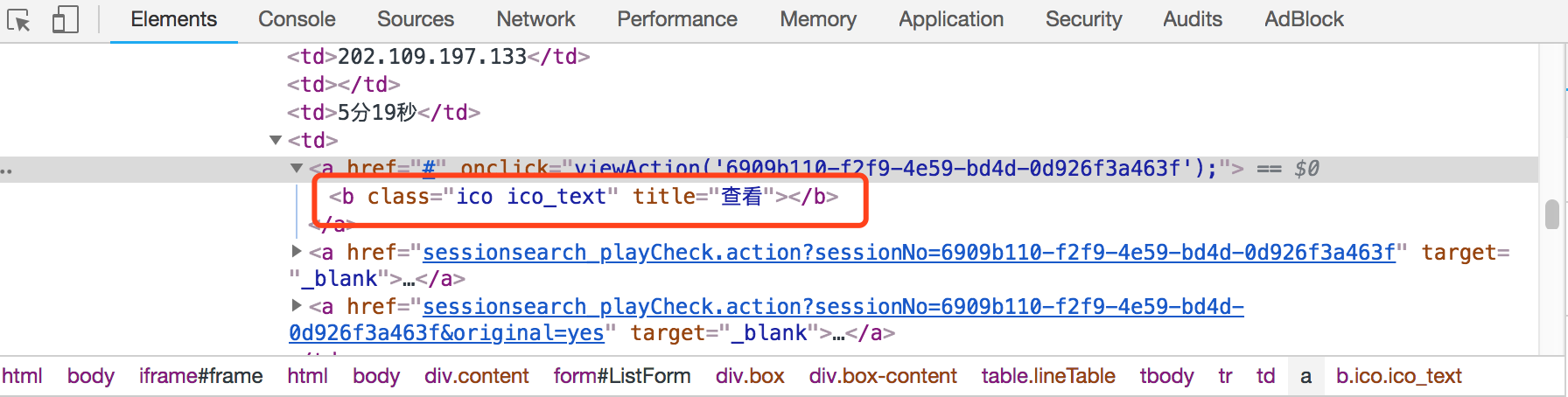
我们要点击红框这个元素,那么,我们可以尝试自行设定查找路径:
* [title="查看"]表示有title="查看"属性
* 或者设置.ico.ico_text,表示类是ico ico_text, 注意,类名不能有空格
当然,这些 selector 是否唯一,需要自行测试,但是对动态移动的元素来说,我们必须找到他唯一的标识是什么,并自行定位查找。

希望以后能拾取到 iframe 里的元素
selenium webdrive
补充几个常见的写法, 针对正文中红框的元素
以上写法可以组合使用,在 chrome 中,可以用 ctrl + f 来确定是不是唯一的
如果实在找不到唯一的,有几个需要处理,或者要检查正文,可以用一下方法来查看
这个方法可以遍历到正文 + selector 要求,get_text 是我假设获取正文的函数,大概原理如此