-
【优化建议】关于核心属性的识别和批量替换
2022-01-13 16:32 -
列表的分类问题
2022-01-13 10:18社区支持 markdown 的
for i in range(1,10): print(i) -
考核时间
2022-01-13 10:16目前还没发···
-
考核时间
2022-01-13 10:16一般会发置顶贴。
-
获取结构化数据的翻页属性
2022-01-13 10:14很抱歉,现在才回复···
我测试了一下,发现是 【翻页元素】的属性发生了变化。
下图是拾取后,默认的结果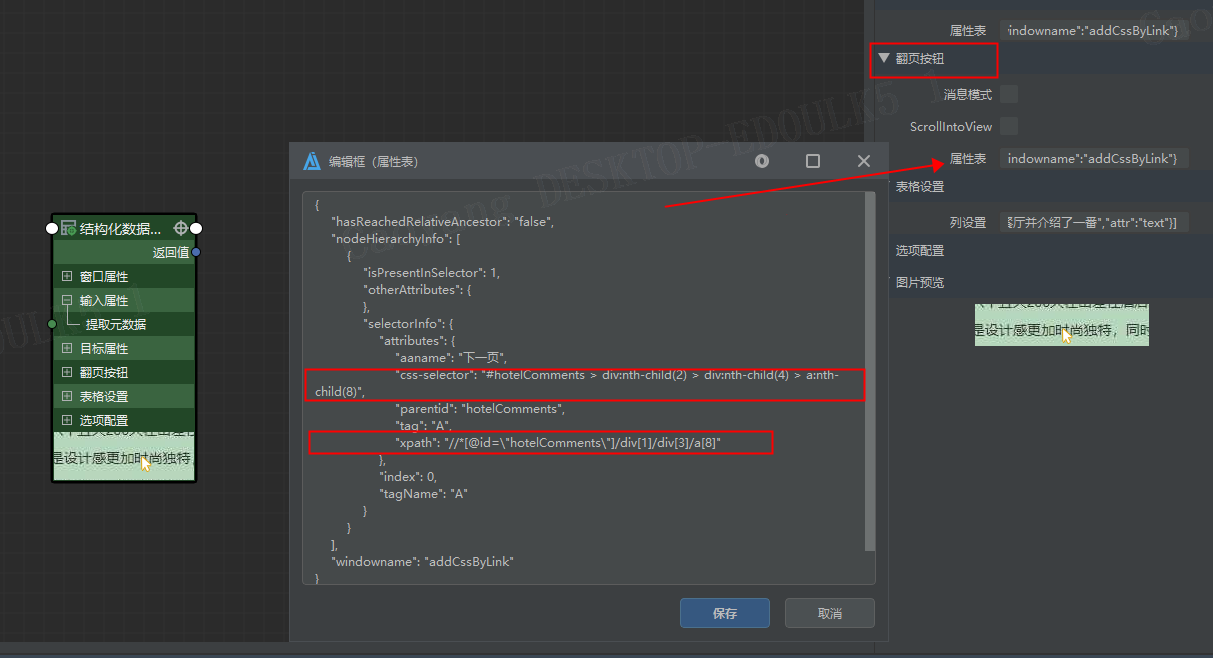
在翻到第 2 页时,xpath 和 css 与 第一页拾取的结果 不一样了··· 导致第二页执行翻页动作失败。
请删除 红色方框内的内容, 最好再按下 编辑框右上角的【json 格式化】按键,检查 json 格式 😄
请再次测试。 -
每天都在续命当中
2022-01-13 10:05你可以写一些帖子,关于设计器使用的经验,或者提些优化建议(界面、组件功能、运行逻辑)。
应该是会有奖励的··· -
获取结构化数据的翻页属性
2022-01-06 15:53可以提供个网址么?我试一下。
根据日志信息,应该是 翻页按键的属性变了, 导致无法继续翻页。 -
获取结构化数据的翻页属性
2022-01-06 10:29请提供下日志,好么?
可以修改下【翻页按键】的属性, 有可能是翻页后,翻页按键属性改变了。 -
医疗的安利谁那有?
2021-12-13 16:47什么意思···
-
关于验证码问题
2021-12-02 10:5410.3 版本 验证码组件右侧有 code_type 参数呀 ~~~
所以 你是修改了此参数,但返回结果 不能满足预期么?可以给个网址例子么 ~~ 我看看
-
关于验证码问题
2021-12-02 10:33抱歉,我看看·········
-
Passion Led Us Here | 艺赛旗 2022 校园招聘
2021-11-30 11:44图上有的,实习 一天 150~~~
正常市场薪酬水平··· -
返回不重复练习
2021-11-30 11:24有一个库 collections, 你也可以看看, 虽然不能直接得出这题的答案 ~~~
但我觉得这个库很有趣 😆from collections import Counter string = `abcdeab` ret = Counter(string) print(ret) >>> Counter({'a': 2, 'b': 2, 'c': 1, 'd': 1, 'e': 1}) -
返回不重复练习
2021-11-30 11:14for i in string: if string.index(i) == string.rindex(i): print(f"found it! value is :{i}") break # index(i) rindex(i) 如果一致,说明是相同的元素,即只出现一次。 -
返回不重复练习
2021-11-26 18:02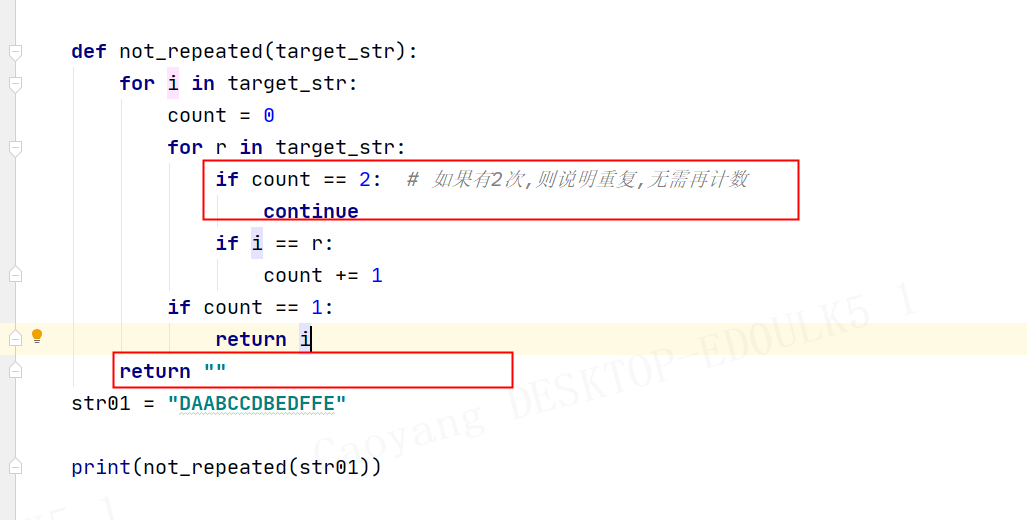
没花太多时间思考 ~~ 还是基于你的思路,做了些许优化 -
「高阶培训」第二十期 - 11.25-11.26
2021-11-26 17:20赞!
讲的很好! -
2021.2.0 如何快速定位报错组件
2021-11-18 11:18在下方控制台,点击报错信息 ( 如下图红色区域),即可跳转。
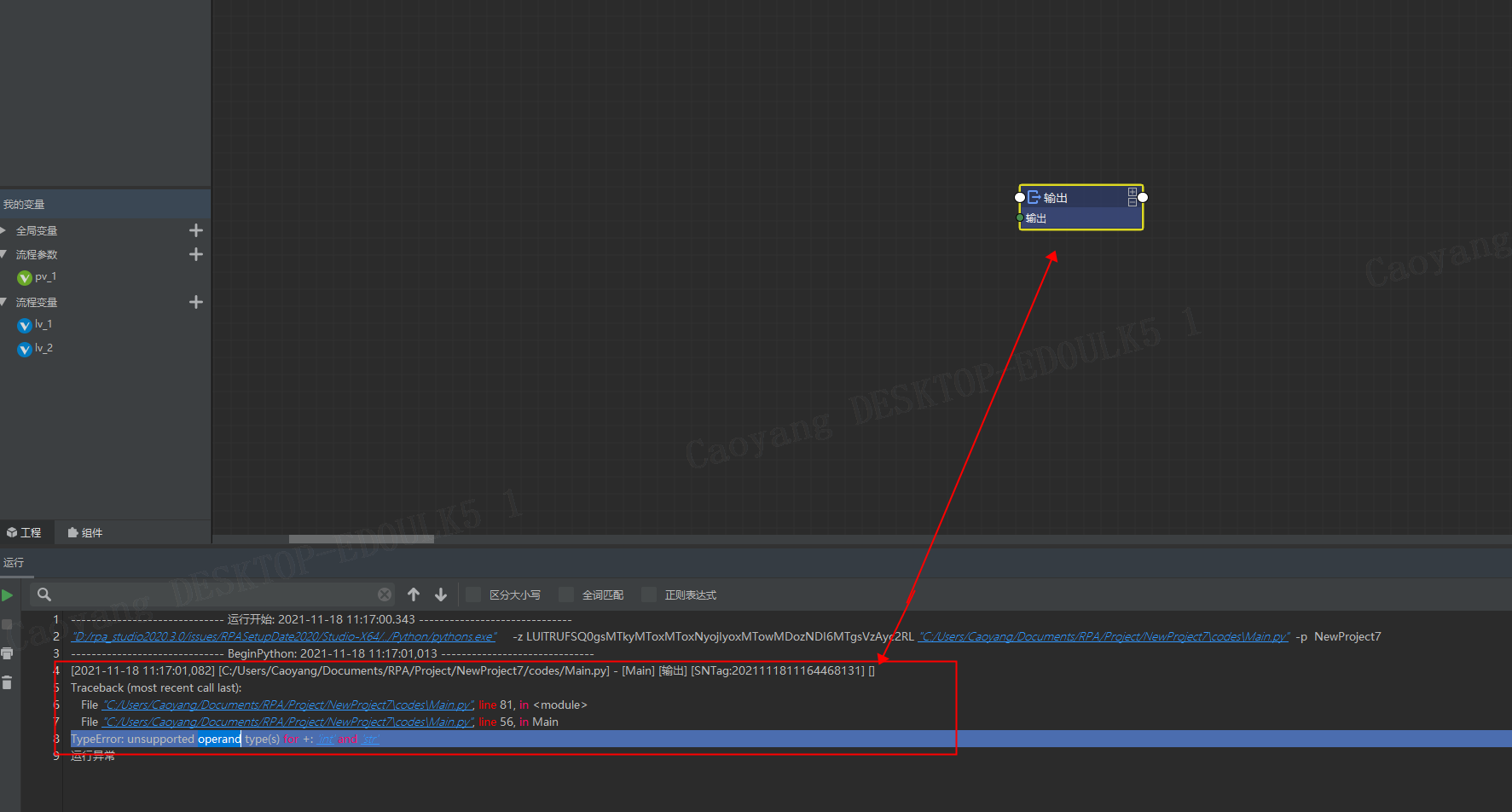
-
拾取表格返回的值的 bug
2021-11-12 16:59其实 pandas 读取数据就是这个规则。

-
【控制】- 拾取表格(web)”hearder“参数建议
2021-11-12 11:10打扰下 ~ 我最近正在修改这个问题。
我调用的是 pandas 模块的方法。
html 里 table 的 head 是有标签的,比如html = """ <table> <thead> <tr> <th> header 1 </th> <th> header 2 </th> <th> header 3 </th> </tr> </thead> <tr> <td> 001 </td> <td> A </td> <td> 1 </td> </tr> <tr> <td> 002 </td> <td> B </td> <td> 2 </td> </tr> <tr> <td> 003 </td> <td> C </td> <td> 3 </td> </tr> </table> """th 字段内的数据 默认被解析为 header。
我查看了文档,发现没有方法或者参数 可以在 read_html 时将 header 写入 table 的数据里。
我现在想要不要加个参数,来改进这个问题。
你有什么建议么 ~
-
2021-11-11 18:38 高手过招第八期—PDF 系列组件:真的很强大
高手过招第八期—PDF 系列组件:真的很强大
是否可以提供 pdf 呢···
我们这边测试下··· 😋 -
RPA 生态你们都给了啥建议?
2021-11-11 17:19的确很难,如果做到了,其实就和找一个专门的研发人员 给你定制项目一样···
但我前段时间看了微软的 Copilot, 觉得【场景化】还是可以实现的嘛, 哈哈哈哈
-
RPA 生态你们都给了啥建议?
2021-11-11 17:14场景 A 用户需要新增组件【登录账户】, 填写参数 (1) url (2) 账户 (3)密码 (4)ocr 识别的密钥 (如果有 ocr 需要的话)
>> 那么我们可以自动打开网页;识别 账户框、密码框,并填写; 如果有验证码,那么再自动填写 (无论是拖动的,还是按顺序点击的)诸如此类的。
其实这是我预想的机器人自动化。 😙
-
拾取表格返回的值的 bug
2021-11-11 17:08因为我调用的是 pandas 模块的方法
read_html(),它默认就是将 00123 转为 123。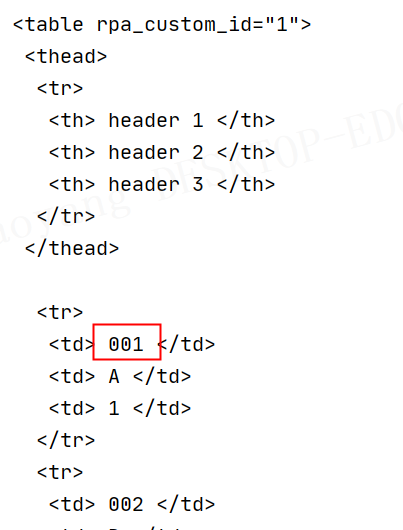
比如这张图,调用后,就是将 001 改为 1。 😞 -
拾取表格返回的值的 bug
2021-11-11 13:18你好 ~ 我最近正在修改这个问题。
初步方案是 组件右侧新增一个参数converters。
以你这个贴子表格为例,converters = {“项目代码”: str}, 那么就把 "01010000" 当成字符串处理,即可保留原值。你有什么建议么?
-
bug 反馈
2021-11-08 13:42可以提供些具体信息么···
-
深夜写试题
2021-11-08 13:41哈哈哈 你这长度厉害了 ~
-
RPA 生态你们都给了啥建议?
2021-11-04 17:14也就是 形成一连串的操作。
点 –> 线 –> 面
-
RPA 生态你们都给了啥建议?
2021-11-04 16:39我比较想做场景化的东西,比如 登录网页, 需要输入账户 密码, 通过验证码识别。
现在都是单个组件组合, 如果能做成一个场景,应该会好点。 -
循环获取电影和评分
2021-11-02 15:19再多给点信息好么···
你改动什么内容? 报错信息是什么?
U0JHU1NCSEQ
caoyang

- 0 标签
- 63 帖子
- 604 回帖

这的确是个问题。 有什么好办法呢······
一般情况下,会在生产环境重新拾取的···
集思广益下···