拾取表格
拾取表格
描述:从指定网页程序中提取表格元素数据
属性说明
通用属性
- 前置延时 - 组件功能执行之前等待的时间,单位为“ms”
- 后置延时 - 组件功能执行后等待的时间,单位为“ms”
- 备注- 组件备注说明,以便于理解和快速定位
- 等待 - 设置时间内的多次尝试
返回值
- 输出到变量 - 将返回值赋值给变量
拾取IE浏览器:
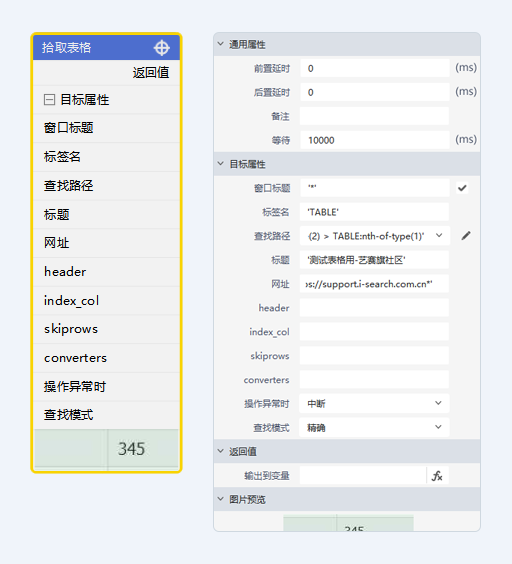
目标属性
- 窗口标题 - 拾取元素的IE窗口标题,支持通配*
- 标签名 - 元素的标签
- 查找路径 - 元素的属性
- 标题 - 拾取元素的网页窗口标题
- 网址 - 拾取元素页面的url,支持通配*
- header - 输入数据中行的下标(int整型),指定该行作为表头,默认为空、输入
0或者输入None,三种方式均默认网页表格第一行为表头 - index_col - 用以设置数据指定列为索引列,默认为空,即None,不进行设置;也可输入数据中指定列的下标,或列名的字符串,其对应类型为int整型和字符串
- skiprows - 从拾取的网页表格的第*行开始读取,*****填0或不填则默认读取全部,填入需是int型数据
- converters - 指定每列的格式。例:
{"列名1":str,"列名2":int} - 操作异常时 - 此组件报错时忽略错误继续执行流程,默认“中断”则异常时停止流程并跑出异常信息
- 查找模式 - 精确:只在当前网页查找拾取的元素,模糊:遍历全部网页查找拾取的元素
拾取Chrome、Firefox、Edge、Qihoo360模式:
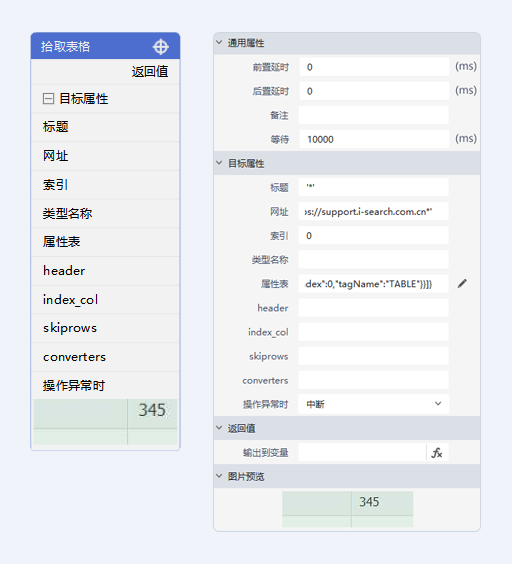
窗口属性
- 区域 - 拾取时元素的位置及大小
目标属性
- 标题 - 目标元素所在窗口的标题信息,支持通配__*__
- 网址 - 目标元素所在窗口的网址信息,支持通配__*__
- 索引 - 在找到的第几个元素上执行操作,一般为 0,即找到的第一个元素
- 类型名称 - 目标元素的类型名称
- 属性表 - 目标元素的 selector 与 xpath 等属性,可双击或点击右侧按钮进入属性编辑模式
- header - 输入数据中行的下标(int整型),指定该行作为表头,默认为空、输入0或者输入None,三种方式均默认网页表格第一行为表头
- index_col - 用以设置数据指定列为索引列,默认为空,即None,不进行设置;也可输入数据中指定列的下标,或列名的字符串,其对应类型为int整型和字符串
- skiprows - 从拾取的网页表格的第*行开始读取,*****填0或不填则默认读取全部,填入需是int型数据
- converters - 指定每列的格式。例:
- 操作异常时 - 此组件报错时忽略错误继续执行流程,默认中断则异常时停止流程并跑出异常信息
使用示例
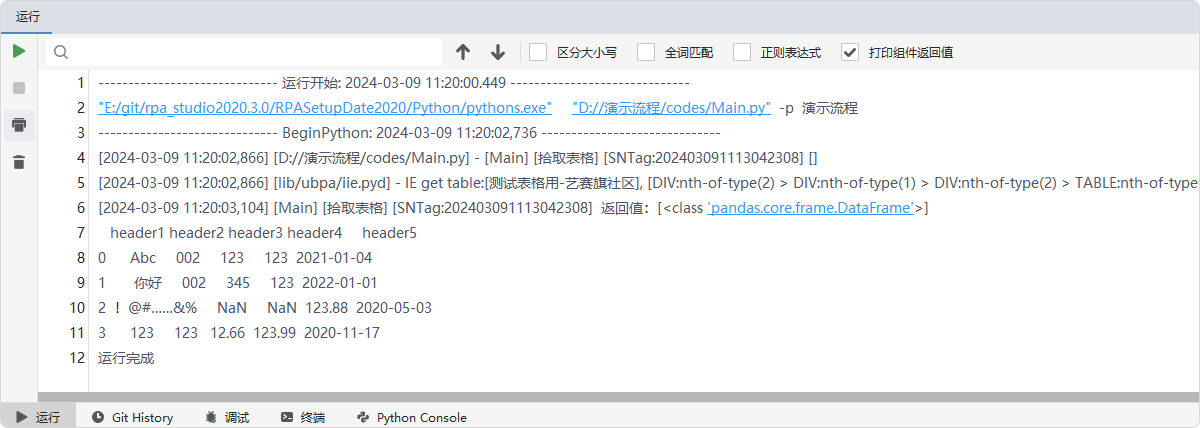
执行逻辑
添加【拾取表格】组件,选择  并点击--->拾取浏览器中表格标签的元素--->执行组件
并点击--->拾取浏览器中表格标签的元素--->执行组件

输出结果
执行组件后,控制台会返回当前拾取的元素的表格对象,返回数据类型“pandas.core.frame.DataFrame”