

requests 方式爬取豆瓣 top250 电影名
#!/usr/bin/python
# coding:utf-8
import requests
from bs4 import BeautifulSoup
test_url = ‘http://movie.douban.com/top250/’
def download_page(url):
headers = {
‘User-Agent’: ‘Mozilla/5.0
(Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/47.0.2526.80 Safari/537.36’
}
data =
requests.get(url,headers=headers).content
return data
movie_name_list = []
def parse_html(html):
soup = BeautifulSoup(html)
movie_list_soup
= soup.find(‘ol’, attrs={‘class’: ‘grid_view’})
if movie_list_soup != None:
for movie_li in movie_list_soup.find_all(‘li’):
detail
= movie_li.find(‘div’, attrs={‘class’: ‘hd’})
movie_name
= detail.find(‘span’, attrs={‘class’: ‘title’}).getText()
movie_name_list.append(movie_name)
next_page =
soup.find(‘span’, attrs={‘class’: ‘next’}).find(‘a’)
if next_page:
parse_html(download_page(test_url
+ next_page[‘href’]))
return movie_name_list
def main():
handle =
parse_html(download_page(test_url))
if handle != None:
handle =
list(handle)
for ele in handle:
print ele
if name == ‘main’:
main()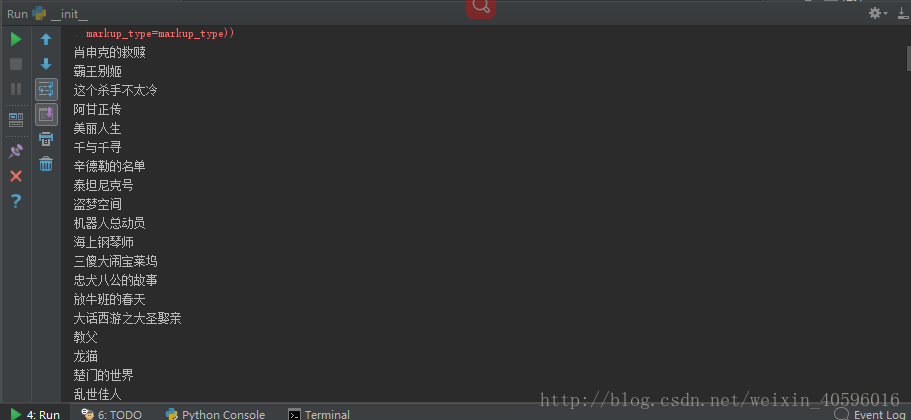

这个还是真厉害!