

python 如何提取 word 内的图片
方法一:解压.docx 文件提取图片
前言
.docx 文件其实也就是一个压缩文件,当我们将一个.docx 文件直接解压后可以看到如下目录
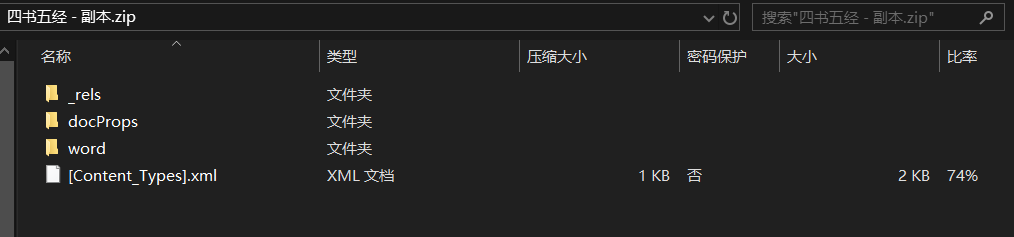
其中我们要找的图片就在 word/media 目录内,如图
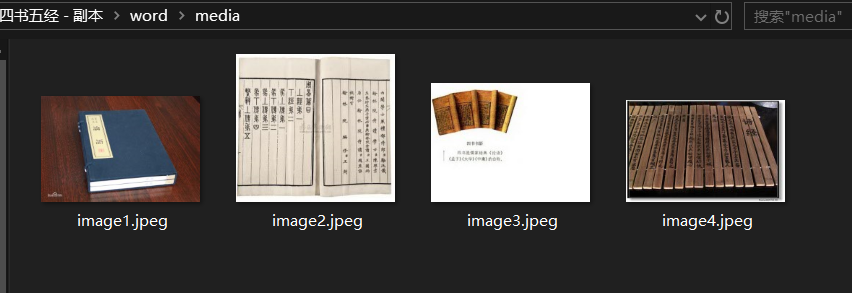
所以,要提取 word 内的图片就需要将.docx 文件解压,再从 media 文件内取得图片,然后将解压后的文件删除
代码
import os
import shutil
import zipfile
def get_pictures(word_path, result_path):
"""
获取word内的所有图片
:param word_path: word文件
:param result_path: 结果目录,无需手动创建
:return: None or generator,None:word内没有图片,generator:每个图片的路径
"""
tmp_path = f'{os.path.splitext(word_path)[0]}'
# 拷贝源文件后重命名再解压
splitext = os.path.splitext(word_path)
zip_path = shutil.copy(word_path, f'{splitext[0]}_new{splitext[1]}')
with zipfile.ZipFile(zip_path, 'r') as f:
for file in f.namelist():
f.extract(file, tmp_path)
os.remove(zip_path)
# 注:word图片在zip文件内的word/media目录下
pic_path = os.path.join(tmp_path, 'word/media')
if not os.path.exists(pic_path):
shutil.rmtree(tmp_path)
return 'no pictures found'
pictures = os.listdir(pic_path)
if not os.path.exists(result_path):
os.makedirs(result_path)
for picture in pictures:
# 根据word的文件名生成图片的名称
word_name = os.path.splitext(word_path)[0]
if os.sep in word_name:
new_name = word_name.split('\\')[-1]
else:
new_name = word_name.split('/')[-1]
picture_name = f'{new_name}_{picture}'
shutil.copy(os.path.join(pic_path, picture), os.path.join(result_path, picture_name))
shutil.rmtree(tmp_path)
return (os.path.join(result_path, pic) for pic in os.listdir(result_path))
方法二:利用三方库 docx 提取图片(推荐)
import docx
import os
def get_pictures(word_path, result_path):
"""
提取word文档内的图片
:param word_path: word文件
:param result_path: 结果目录
:return:
"""
doc = docx.Document(word_path)
dict_rel = doc.part._rels
for rel in dict_rel:
rel = dict_rel[rel]
if "image" in rel.target_ref:
if not os.path.exists(result_path):
os.makedirs(result_path)
img_name = re.findall("/(.*)", rel.target_ref)[0]
word_name = os.path.splitext(word_path)[0]
# print(os.sep)
if os.sep in word_name:
new_name = word_name.split('\\')[-1]
else:
new_name = word_name.split('/')[-1]
img_name = f'{new_name}_{img_name}'
with open(f'{result_path}/{img_name}', "wb") as f:
f.write(rel.target_part.blob)





喜从天降!系统刚检测到您在艺赛旗社区经验栏分享文章时,被从天而降的彩蛋砸中了头,里面竟是 1000Y 币! 2 个工作日内我们会帮忙将这 1000Y 币运送到您的仓库中。
【活动】重金求助,快来帮帮我们吧!