


pandas - 缺失值处理
缺失值的处理逻辑
对于 NaN 的数据,在 pandas 中我们处理起来非常容易
判断数据是否为NaN:pd.isnull(df) 或者 pd.notnull(df)
处理方式:
存在缺失值 nan,并且是 np.nan
- 删除
# pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
df.dropna()
- 替换缺失值
# 替换存在缺失值的样本
# 替换? 填充平均值,中位数
df['Metascore'].fillna(df['Metascore'].mean(), inplace=True)
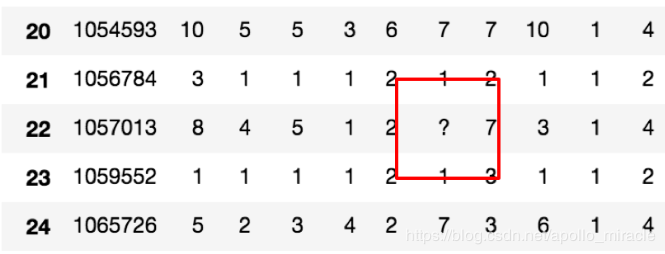
不是缺失值 nan,有默认标记的
数据是这样的: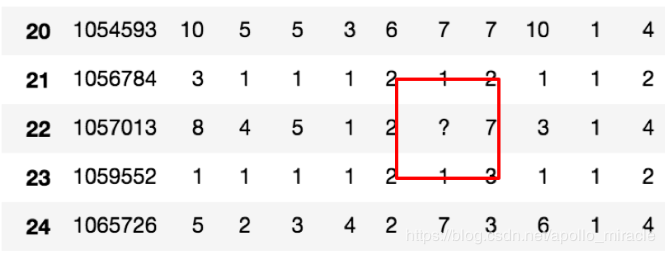
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
处理思路分析:
- 先替换‘?’为 np.nan
df.replace(to_replace=, value=)
- 再进行缺失值的处理
# 把一些其它值标记的缺失值,替换成np.nan
wis = wis.replace(to_replace='?', value=np.nan)
wis.dropna()
