

每日推荐 | 正则表达式获取网页 HTML 指定标签内容 - 循环获取社区首页帖子网址与标题
小伙伴们下午好 ~ 感谢阅读 💫 今日推荐

前两天有小伙伴遇到疑问:希望快速获取网页中某个帖子的 url,下面一段代码实现:循环获取社区首页全部帖子的 url 与标题
1. 需求
获取页面所有帖子的“Url”与“标题”信息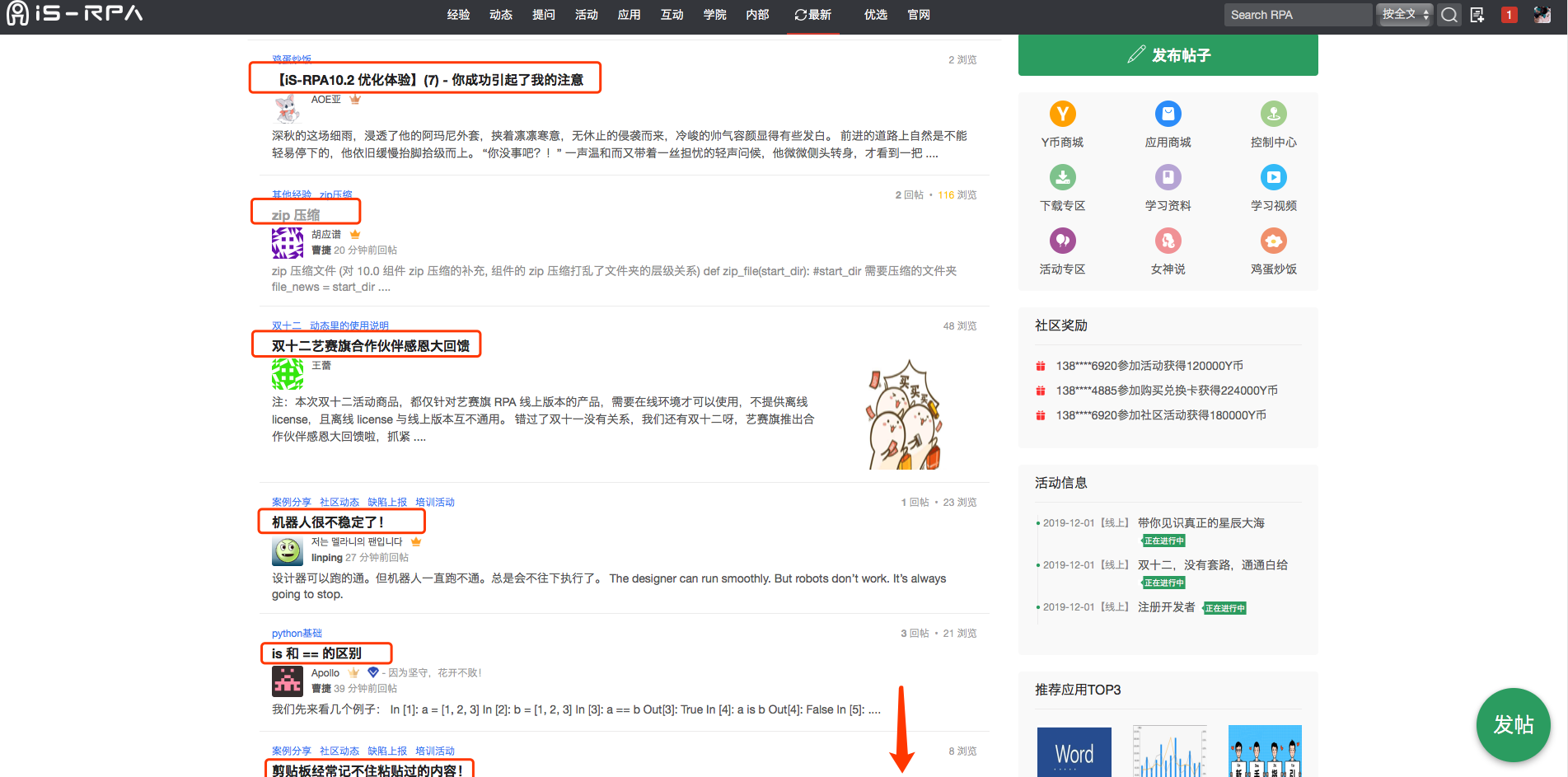
2. 分析
2.1 获取页面全部 HTML 信息
通过 requests.get(url) 即可实现;
也可以使用设计器内置的 iie 库(iie.get_html() 方法获取元素的 html 信息,适用 IE 浏览器)
2.2 将 HTML 信息写入文件
由于打印输出的 HTNL 信息为 str 类型,如果直接读行,是逐字遍历;因此我将它写入文件,可以以读行方式进行筛选
2.3 筛选帖子的 Selector 信息
通过“F2 开发者工具”查看到每个帖子的 selector 信息,发现 均以<a class="ft-a-title"开头,故以此作为查找依据;
可以根据自己的需求,定位元素的 selector,同理根据规律字符串作为查找依据
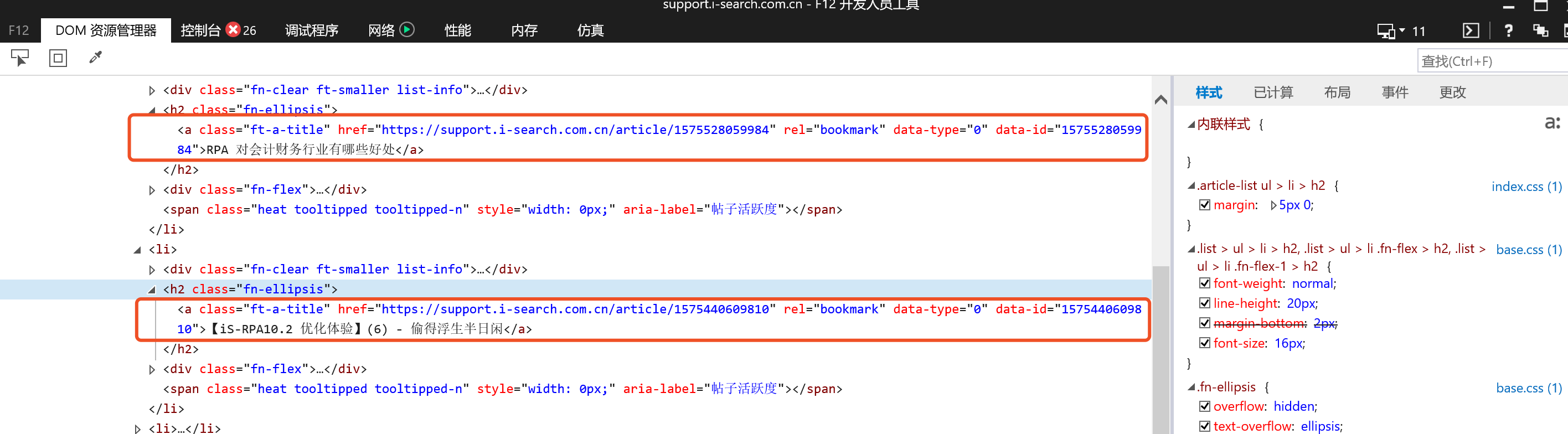
代码中: search = '<a class="ft-a-title"'
2.4 输出 Selector,为获取 Url 与标题做准备
主要为了获取 <a ..> < /a> 这个标签;以此获取帖子标题;因此需要将两行内容相加输出
本文参考来源:常用正则表达式爬取网页信息及分析 HTML 标签总结
代码中:line_html = data[line] + data[line+1]
2.5 根据正则表达式获取页面的帖子 URL 与标题信息
核心代码:
res_tr = r’<a .?>(.?)’
m_tr = re.findall(res_tr,html,re.S|re.M)
3. 实现代码
import requests
import re
#获取页面全部HTML信息
res = requests.get('https://support.i-search.com.cn/')
res.encoding = 'utf-8'
html = res.text
#print(html)
#将HTML信息写入文件
f = open(r"C:\Users\melanie\Desktop\web_html.txt",'w+',encoding="utf-8") #w+:以追加方式打开文件
f.write(html)
f.close()
#读取HTML信息
f = open(r"C:\Users\melanie\Desktop\web_html.txt",'r+',encoding="utf-8") #r+:以读写方式打开文件
data = f.readlines() #data是数组类型
count = 0 #初始化计数,计算获取的帖子的数量;也可以最后直接获取数组的长度
url_list = [] #用于存储帖子url
title_list = [] #用于存储帖子标题
search = '<a class="ft-a-title"' #查找条件,见上述分析
#逐行读取HTML信息
for line in range(len(data)):
if search in data[line]:
line_html = data[line] + data[line+1] #此句关键,见上述分析
#print(line_html)
#正则表达式获取帖子URL
res_url = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
link = re.findall(res_url , line_html, re.I|re.S|re.M)
for url in link:
print(url)
url_list.append(url) #将url加入数组
#正则表达式获取帖子标题
res = r'<a .*?>(.*?)</a>'
text=re.findall(res, line_html, re.I|re.S|re.M)
for content in text:
print(content)
title_list.append(content) #将标题加入数组
#匹配查找成功,计数+1
count += 1
else:
continue
#最终统计查找的帖子数量
print('当前页共计 '+ str(count) +' 篇帖子')
#打印所有url与标题
print(url_list)
print(title_list)
#最终务必记得关闭文件
f.close()
4. 运行结果
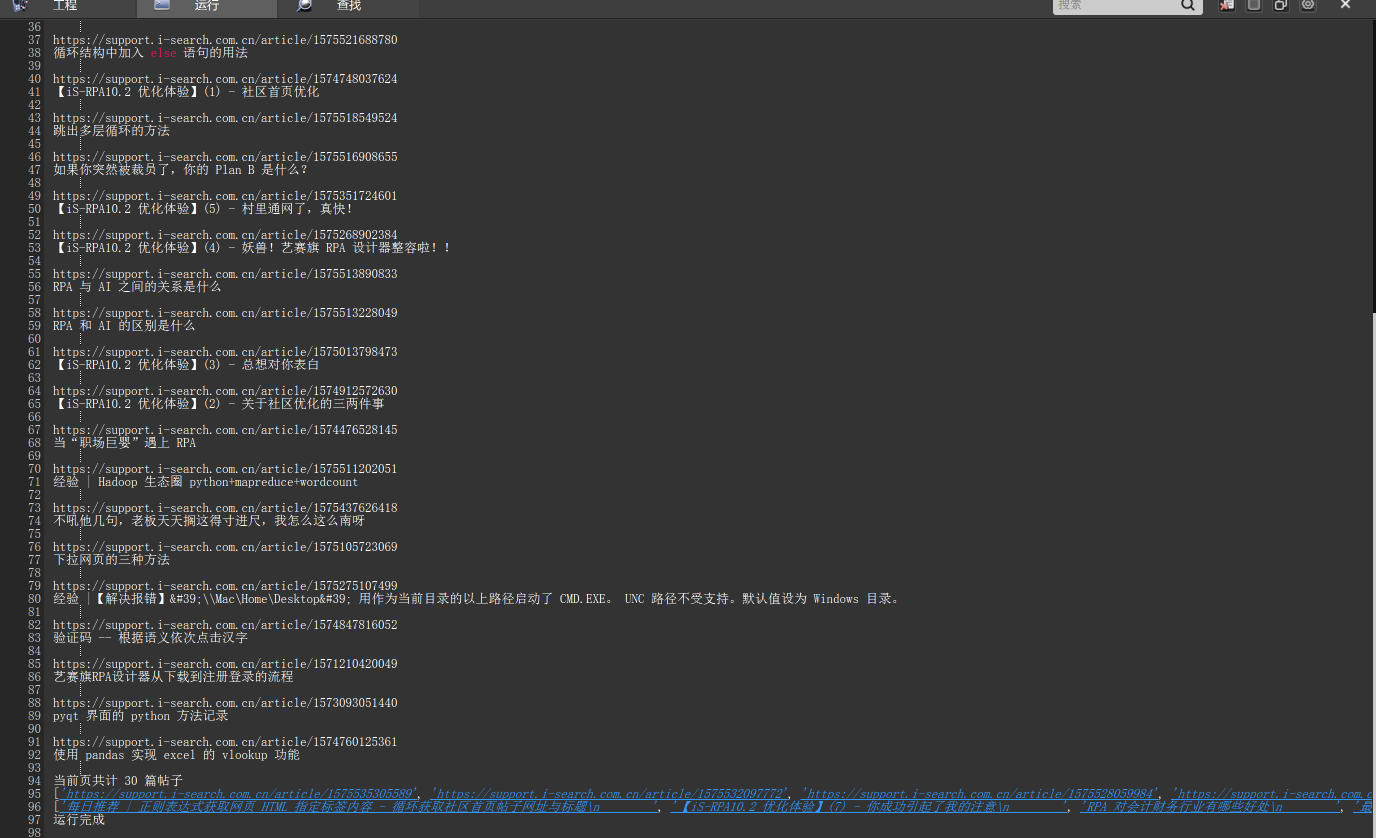
代码可直接拷贝运行;
关于获取页面 HTML 信息其他指定标签的内容,参考源文 常用正则表达式爬取网页信息及分析 HTML 标签总结
