


经验 | Python 读写 Excel 文件第三方库汇总
常见库简介
xlrd
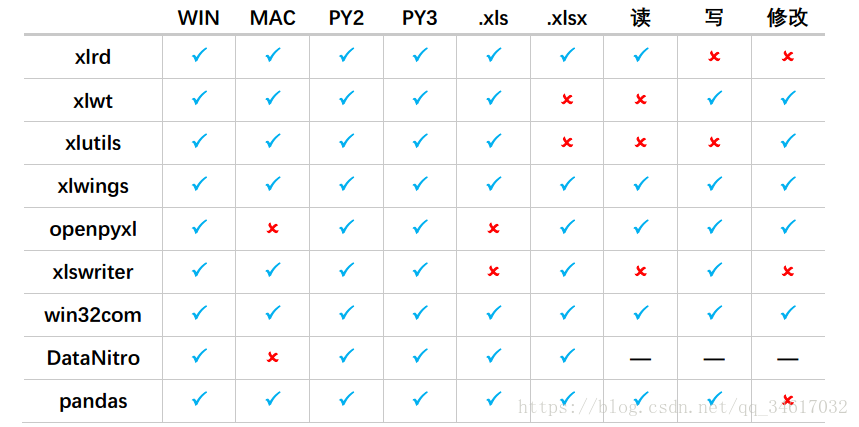
xlrd 是一个从 Excel 文件读取数据和格式化信息的库,支持.xls 以及.xlsx 文件。
http://xlrd.readthedocs.io/en/latest/
1、xlrd 支持.xls,.xlsx 文件的读
2、通过设置 on_demand 变量使 open_workbook() 函数只加载那些需要的 sheet,从而节省时间和内存(该方法对.xlsx 文件无效)。
3、xlrd.Book 对象有一个 unload_sheet 方法,它将从内存中卸载工作表,由工作表索引或工作表名称指定(该方法对.xlsx 文件无效)
xlwt
xlwt 是一个用于将数据和格式化信息写入旧 Excel 文件的库(如.xls)。
https://xlwt.readthedocs.io/en/latest/
1、xlwt 支持.xls 文件写。
xlutils
xlutils 是一个处理 Excel 文件的库,依赖于 xlrd 和 xlwt。
http://xlutils.readthedocs.io/en/latest/
1、xlutils 支持.xls 文件。
2、支持 Excel 操作。
xlwings
xlwings 是一个可以实现从 Excel 调用 Python,也可在 python 中调用 Excel 的库。
http://docs.xlwings.org/en/stable/index.html
1、xlwings 支持.xls 读,支持.xlsx 文件读写。
2、支持 Excel 操作。
3、支持 VBA。
4、强大的转换器可以处理大部分数据类型,包括在两个方向上的 numpy array 和 pandas DataFrame。
openpyxl
openpyxl 是一个用于读取和编写 Excel 2010 xlsx/xlsm/xltx/xltm 文件的库。
https://openpyxl.readthedocs.io/en/stable/
1、openpyxl 支持.xlsx 文件的读写。
2、支持 Excel 操作。
3、加载大.xlsx 文件可以使用 read_only 模式。
4、写入大.xlsx 文件可以使用 write_only 模式。
xlsxwriter
xlsxwriter 是一个用于创建 Excel .xlsx 文件的库。
https://xlsxwriter.readthedocs.io/
1、xlswriter 支持.xlsx 文件的写。
2、支持 VBA。
3、写入大.xlsx 文件时使用内存优化模式。
win32com
win32com 库存在于 pywin32 中,是一个读写和处理 Excel 文件的库。
http://pythonexcels.com/python-excel-mini-cookbook/
1、win32com 支持.xls,.xlsx 文件的读写,支持.xlsx 文件的写。
2、支持 Excel 操作。
DataNitro
DataNitro 是一个内嵌在 Excel 中的插件。
https://datanitro.com/docs/
1、DataNitro 支持.xls,.xlsx 文件的读写。
2、支持 Excel 操作。
3、支持 VBA。
4、收费
pandas
pandas 通过对 Excel 文件的读写实现数据输入输出
http://pandas.pydata.org/
1、pandas 支持.xls,.xlsx 文件的读写。
2、支持只加载每个表的单一工作页。
环境配置及可实现操作
注:DataNitro 作为插件使用需依托软件本身。
读写测试
测试计算机硬件和系统
电脑型号 微星 MS-7846 台式电脑
操作系统 Windows 7 旗舰版 64 位 SP1 (DirectX 11)
处理器 英特尔 Pentium(奔腾) G3260 @ 3.30GHz 双核
主板 微星 H81M-P32L (MS-7846) (英特尔 Haswell - Lynx Point)
内存 4 GB (金士顿 DDR3 1600MHz)
主硬盘 西数 WDC WD5000AZLX-00ZR6A0 (500 GB / 7200 转 / 分)
显卡 英特尔 Haswell Integrated Graphics Controller (256 MB / 微星)
测试用例
用例 1. 读.xls 文件的整个表(表有 5 个分页,每个分页有 2000 行 1200 列的整数)。
用例 2. 读.xlsx 文件的整个表(表有 5 个分页,每个分页有 2000 行 1200 列的整数)。
用例 3. 读.xls 文件的整个表(表有 1 个分页,页有 2000 行 1200 列的整数)。
用例 4. 读.xlsx 文件的整个表(表有 1 个分页,页有 2000 行 1200 列的整数)。
用例 5. 写.xls 文件的整个表(表有 5 个分页,每个分页有 2000 行 1200 列的整数)。
用例 6. 写.xlsx 文件的整个表(表有 5 个分页,每个分页有 2000 行 1200 列的整数)。
用例 7. 写.xls 文件的整个表(表有 1 个分页,页有 2000 行 1200 列的整数)。
用例 8. 写.xlsx 文件的整个表(表有 1 个分页,页有 2000 行 1200 列的整数)。
测试结果

注 1.xlwt 和 pandas 每个工作页最多写入 256 列,因此测试用例修改为每页有 2000 行 256 列的整数.
注 2.xlutils 读写依赖于 xlrd 和 xlwt,不单独测试。
注 3.openpyxl 测试两种模式,一是普通加载写入,二是 read_only/write_only 模式下的加载写入。
注 4.DataNitro 要收费,且需依托 Excel 使用,本次不测试。
读写性能比较
单从读写的性能上考虑,win32com 的性能是最好的,xlwings 其次。
openpyxl 虽然操作 Excel 的功能强大,但读写性能过于糟糕,尤其是写大表时,会占用大量内存(把我的 4G 内存用完了),开启 read_only 和 write_only 模式后对其性能有大幅提升,尤其是对读的性能提升很大,使其几乎不耗时(0.01 秒有点夸张,不过确实是加载上了)。pandas 把 Excel 当作数据读写的容器,为其强大的数据分析服务,因此读写性能表现中规中矩,但其对 Excel 文件兼容性是最好的,支持读写.xls,.xlsx 文件,且支持只读表中单一工作页。同样支持此功能的库还有 xlrd,但 xlrd 只支持读,并不支持写,且性能不突出,需要配合 xlutils 进行 Excel 操作,并使用 xlwt 保存数据,而 xlwt 只能写入.xls 文件(另一个可以写入.xls 文件的库是 pandas,且这两个写入的 Excel 文件最多只能有 256 列,其余库就我目前的了解均只能写入.xlsx 文件),性能一般。xlsxwriter 功能单一,一般用来创建.xlsx 文件,写入性能中庸。win32com 拥有最棒的读写性能,但该库存在于 pywin32 的库中,自身没有完善的文档,使用略吃力。xlwings 拥有和 win32com 不相伯仲的读写性能,强大的转换器可以处理大部分数据类型,包括二维的 numpy array 和 pandas DataFrame,可以轻松搞定数据分析的工作。
综合考虑,xlwings 的表现最佳,正如其名,xlwings——Make Excel Fly!
便捷性比较
本测试目前只是针对 Excel 文件的读写,并未涉及 Excel 操作,单从读写的便捷性来讲,各库的表现难分上下,但是 win32com 和 xlwings 这两个库可以在程序运行时实时在打开的 Excel 文件中进行操作,实现过程的可视化,其次 xlwings 的数据结构转换器使其可以快速的为 Excel 文件添加二维数据结构而不需要在 Excel 文件中重定位数据的行和列,因此从读写的便捷性来比较,仍是 xlwings 胜出。
测试代码
计时
import timeit
if __name__ == '__main__':
# 使用timeit计时
t = timeit.Timer('??()', setup='from __main__ import ??')
print(t.timeit(number=1))
xlrd
import xlrd
def test_xlrd_on_demand_false():
# f = xlrd.open_workbook('test_cases\\read_xls.xls', on_demand=False)
f = xlrd.open_workbook('test_cases\\read_xlsx.xlsx', on_demand=False)
def test_xlrd_on_demand_true():
# f = xlrd.open_workbook('test_cases\\read_xls.xls', on_demand=True)
f = xlrd.open_workbook('test_cases\\read_xlsx.xlsx', on_demand=True)
f.sheet_by_index(0)
xlwt
import xlwt
book = xlwt.Workbook()
def test_xlwt():
for s in range(5):
sheet = book.add_sheet(str(s))
for i in range(2000):
for j in range(256):
sheet.write(i, j, 65536)
book.save('test_cases\\write_xls.xls')
xlwings
import xlwings
def test_xlwings_read():
# f = xlwings.Book('test_cases\\read_xls.xls')
f = xlwings.Book('test_cases\\read_xlsx.xlsx')
import numpy as np
f = xlwings.Book('')
d = np.zeros([2000, 1200])
d += 65536
def test_xlwings_write():
for s in range(1):
sheet = f.sheets.add()
sheet.range('A1').value = d
f.save('test_cases\\write_xlsx.xlsx')
openpyxl
import openpyxl
def test_openpyxl_read():
f = openpyxl.load_workbook('test_cases\\read_xlsx.xlsx', read_only=True)
c = [65536] * 1200
f = openpyxl.Workbook(write_only=True)
def test_openpyxl_write():
for i in range(1):
sheet = f.create_sheet(title=str(i))
for row in range(2000):
sheet.append(c)
f.save('test_cases\\write_xlsx.xlsx')
xlsxwriter
import xlsxwriter
workbook = xlsxwriter.Workbook('test_cases\\write_xlsx.xlsx')
def test_xlsxwriter():
for s in range(1):
worksheet = workbook.add_worksheet()
for i in range(2000):
for j in range(1200):
worksheet.write(i, j, 65536)
workbook.close()
win32com
import win32com.client as win32
excel = win32.gencache.EnsureDispatch('Excel.Application')
def test_win32com_read():
# wb = excel.Workbooks.Open('E:\\excel\\test_cases\\read_xls.xls')
wb = excel.Workbooks.Open('E:\\excel\\test_cases\\read_xlsx.xlsx')
# excel.Visible = True
wb = excel.Workbooks.Add()
def test_win32com_write():
for i in range(1):
ws = wb.Worksheets.Add()
ws.Range("A1:ATD2000").Value = 65536
wb.SaveAs('E:\\excel\\test_cases\\write_xlsx.xlsx')
excel.Application.Quit()
pandas
import pandas as pd
def test_pandas_read():
for i in range(1, 6):
sheet_name = "Sheet" + str(i)
# df = pd.read_excel('test_cases\\read_xls.xls', sheet_name)
df = pd.read_excel('test_cases\\read_xlsx.xlsx', sheet_name)
import numpy as np
d = np.zeros([2000, 255])
d += 65536
df = pd.DataFrame(d)
# writer = pd.ExcelWriter('test_cases\\write_xls.xls')
writer = pd.ExcelWriter('test_cases\\write_xlsx.xlsx')
def test_pandas_write():
df.to_excel(writer, 'Sheet1')
df.to_excel(writer, 'Sheet2')
df.to_excel(writer, 'Sheet3')
df.to_excel(writer, 'Sheet4')
df.to_excel(writer, 'Sheet5')
writer.save()

哇,get√,已收藏