


Excel 处理技巧 - 数据处理 (三)
一、字段抽取
slice(start,stop)
start 表示开始位置
stop 表示结束位置
用法:
df.[列名].str.slice(开始位置,结束位置)
使用测试数据,我们读取“号码”一列,得到下图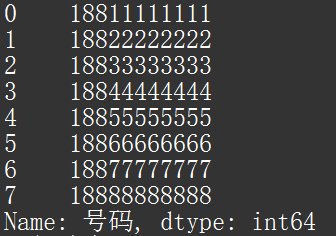
当我们需要从号码中抽取前 3 位(前 3 位可知道号码所属的运营商),代码如下:
df = pd.read_excel(io='//mac/Home/Desktop/test/test.xlsx')
df['号码'] = df['号码'].astype(str) # 属性转成字符串格式
df1 = df['号码'].str.slice(0,3)
print(df1)
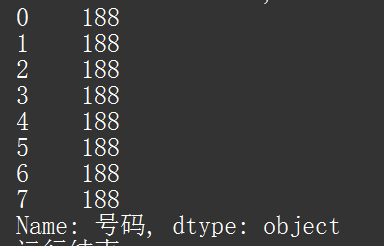
得到上图,代码中,可以看到我们将“号码”这一列的属性转成了字符串 Excel 处理技巧 (二) ,最后也说过,若对 int 类型直接操作,会报错。
好处: 在处理 Excel 某列提取其中固定的字段,我们就不用使用循环的方式去切割了。
二、字段拆分
split(sep,n,expand=False)
sep 表示用于分割字符串的分隔符;
n 表示分割后新增的列数;
expand 表示 是否展开为数据框,默认False,返回的是Series
为True,返回的是DateFrame
使用测试数据,读取“IP”一列,得到下图: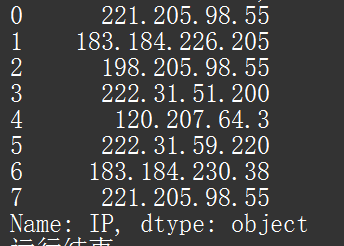
处理代码如下:
df = pd.read_excel(io='//mac/Home/Desktop/test/test.xlsx')
df['IP'] = df['IP'].astype(str)
df1 = df['IP'].str.split('.',4,True)
print(df1)
结果如下:
我们以“.”拆分,分成了 4 列,返回 DateFrame 类型的值。
好处:看看项目上遇到的那些需求有关 Excel 某列的拆分。
三、记录抽取
df[condition]
condition 表示过滤条件
通过测试数据,结果如下图: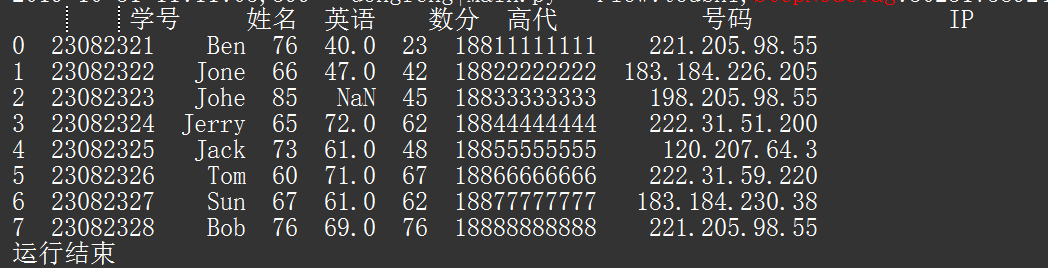
若需求,取出英语成绩 在 65-75 之间的数据,代码如下:
df = pd.read_excel(io='//mac/Home/Desktop/test/test.xlsx')
df1= df[df.英语.between(65,75)]
print(df1)

当然,还有很多的运算符,再此就不一一示范了。

这个必须点赞👍
😄