


Excel 处理技巧 (二)
数据清洗
1、重复值处理 **
(在多分数据合并出现重复 or 文件中对重复的数据只计算一次可用)
duplicated(self,subset=None,keep='first')
# keep='first' 表示除了第一次出现外,其余相同的数据都标记为重复
# keep='last' 表示除了最后一次出现外,其余相同的数据都标记为重复
# keep=False 表示所有相同的数据都被标记为重复值
# drop_duplicated() 则表示删除重复值
2、缺失值处理 **
(1) df.dropna() 去除数据有空所对应的行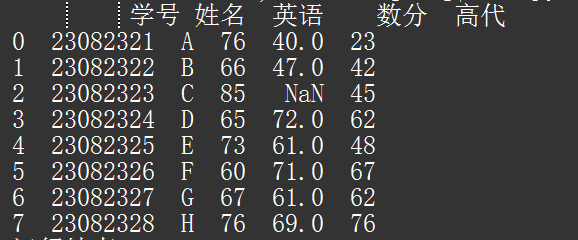
测试数据,通过“读取 Excel”组件直接读出,返回如上图:
会发现索引为 2,这行有一个空值,输出时,空值,默认以“Nan”显示
经过一下代码处理后:
df = pd.read_excel(io='//mac/Home/Desktop/test/test.xlsx')
df1 = df.dropna()
print(df1)
得到的结果为: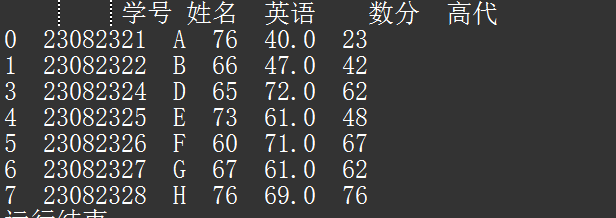
会发现索引为 2 的行,已经不存在了。
(2) df.fillna() 用其他数值替代缺失值
a、df.fillna(method='pad') 用前一个数据值替代Nan
b、df.fillna(method='bfill') 用后一个数据值替代Nan
c、df.fillna(df.mean()) 用平均数或者其他描述性统计量来代替Nan
d、df.fillna(df.mean()['填补列名':'计算均值的列名']) 使用选择列的均值进行缺失值的处理
e、df.fillna({'列名1':"值1",'列名2',"值2"}) 可以传入一个字典,对不同的列进行填充
同样适用上面的测试数据,对 a 点。
经过以下代码后:
df = pd.read_excel(io='//mac/Home/Desktop/test/test.xlsx')
df1 = df.fillna(method='pad')
print(df1)
得到的如下: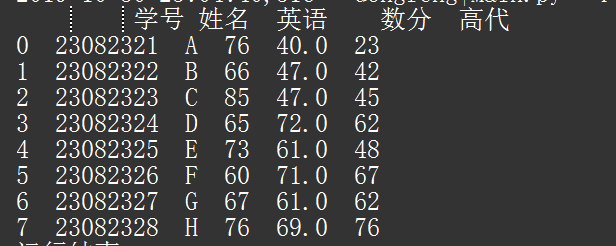
会发现,之前索引为 2,这行英语的值取得是索引 1,同列的数据。(剩下属性不做演示)
3、 df.strip()
清除字符串数据左右指定的字符 ** 默认空格(中间不清除)
通过测试数据,我们读取姓名一列,得到下图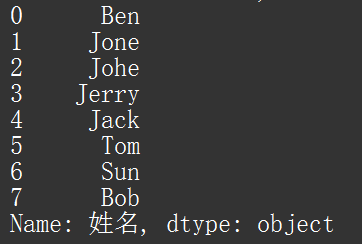
经过以下代码:
df = pd.read_excel(io='//mac/Home/Desktop/test/test.xlsx')
df1 = df['姓名'].str.strip('J')
print(df1)
得到如下图: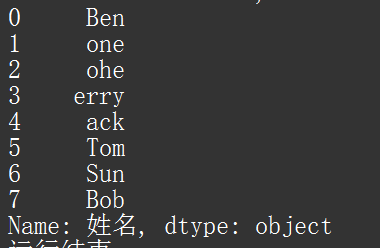
代码中,我们将姓名这一列,去除字段中首尾的“J”。(日常流程中,可能去除空字符串要较多一点,一般在多分不同来源的数据汇总的时候会出现这种问题)。
当然,该函数,还有两种写法,分别是:
a、df[列名].str.rstrip(去除的字符) # 去除尾部
b、df[列名].str.lstrip(去除的字符) # 去除首部
注意:
此方法只针对字符串格式,若列如测试数据中“学号”一列,使用此代码,会报错 :
AttributeError: Can only use .str accessor with string values, which use np.object_ dtype in pandas
解决方案,参照下贴 Excel 处理技巧 - 数据处理 (三)

这个必须点赞👍