

为什么 python 的 request.get 获取的网页代码不全
import requests
r = requests.get(pv_url)
html= r.text
print(html)
pv_url=‘https://item.jd.com/1172745.html#crumb-wrap |
上面这个 url 获取的 html 代码不全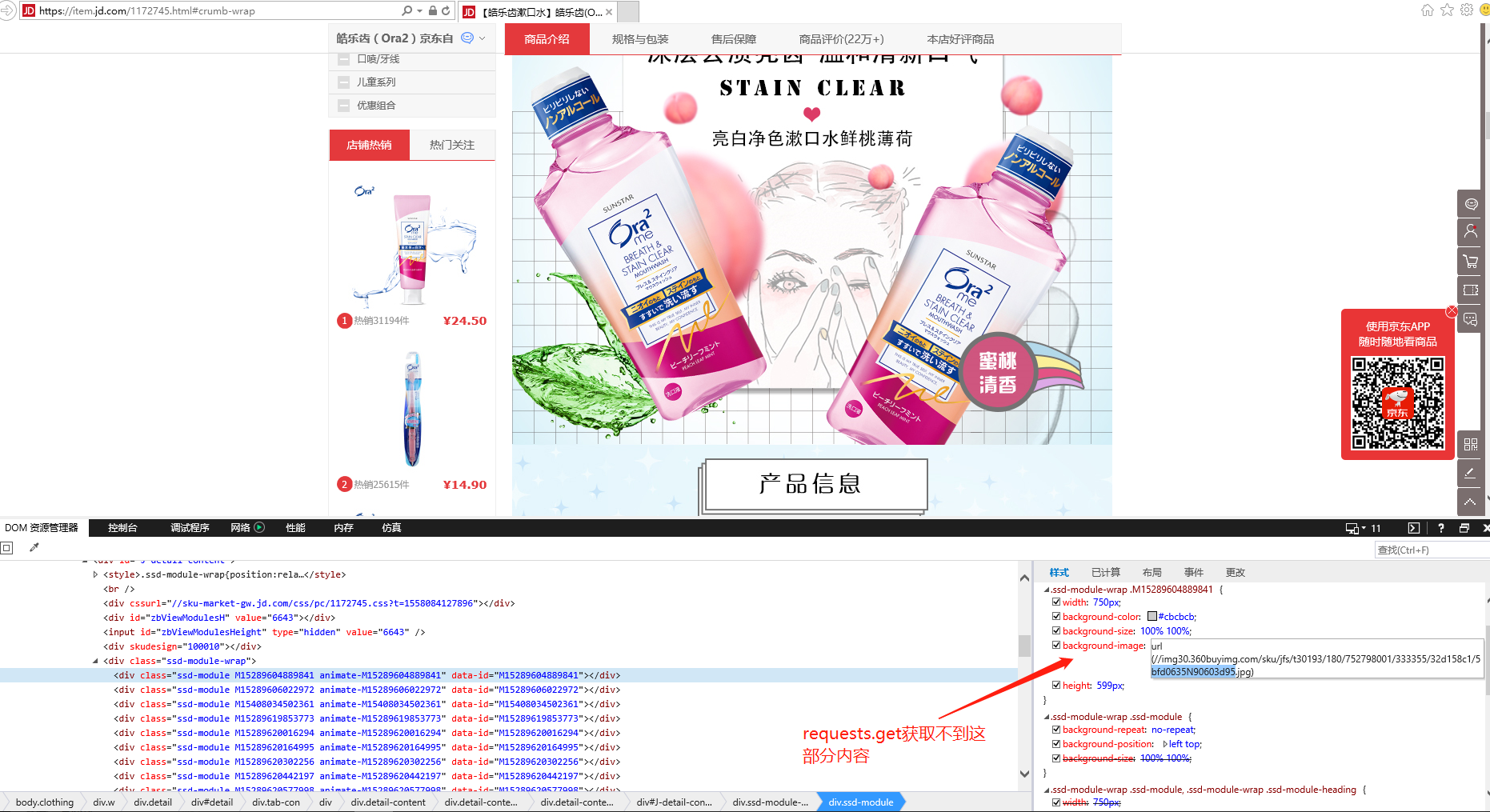
pv_url= https://item.jd.com/2710503.html#crumb-wrap](https://item.jd.com/2710503.html#crumb-wrap) |
上面这个 url 获取的 html 代码却是完整的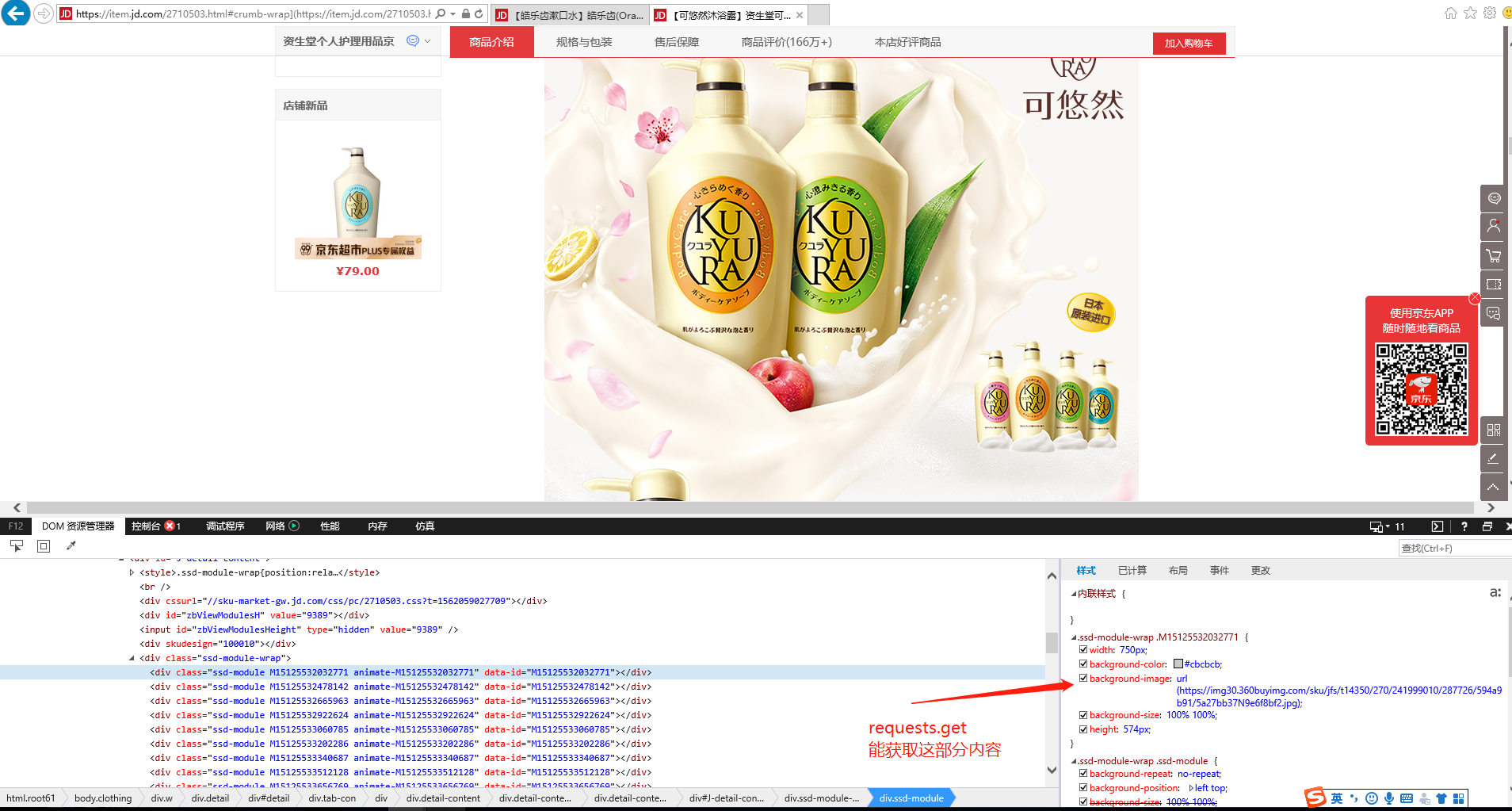

requests.get(url) 获取的只是网页初始显示的内容,当然网页具有反爬虫功能,你需要带上请求头和 cookie 才能获取所有内容
可能 cookie、参数不全
requests 获取的只是网页源代码