


【数据结构与算法】遗传算法(三)应用篇之数据科学问题介绍
1、特征选取
试想一下每当你参加一个数据科学比赛,你会用什么方法来挑选那些对你目标变量的预测来说很重要的特征呢?你经常会对模型中特征的重要性进行一番判断,然后手动设定一个阈值,选择出其重要性高于这个阈值的特征。
那么,有没有什么方法可以更好地处理这个问题呢?其实处理特征选取任务最先进的算法之一就是遗传算法。
我们前面处理背包问题的方法可以完全应用到这里。现在,我们还是先从建立「染色体」总体开始,这里的染色体依旧是二进制数串,「1」表示模型包含了该特征,「0」表示模型排除了该特征。
不过,有一个不同之处,即我们的适应度函数需要改变一下。这里的适应度函数应该是这次比赛的的精度的标准。也就是说,如果染色体的预测值越精准,那么就可以说它的适应度更高。
下面我不会马上讲解这个问题的解决过程,而是先看一个数据科学问题,并用 TPOT 库去实现它。
2、大型超市销售问题
2.1 问题概述
The data scientists at BigMart have collected 2013 sales data for 1559 products across 10 stores in different cities. Also, certain attributes of each product and store have been defined. The aim is to build a predictive model and find out the sales of each product at a particular store.
Using this model, BigMart will try to understand the properties of products and stores which play a key role in increasing sales.
Please note that the data may have missing values as some stores might not report all the data due to technical glitches. Hence, it will be required to treat them accordingly.
译文:
来自BigMart的数据科学家已经收集了不同城市10家商店的1559种产品在2013年的销售数据。此外,还定义了每个产品和商店的某些属性。这个比赛的目的是构建一个预测模型来找出每个产品在特定商店的销售情况。
有了这个模型,BigMart将尝试了解在增加销售方面起关键作用的产品和商店的属性。
请注意,由于技术问题,某些商店可能无法报告所有数据,因此数据可能包含缺失值。所以,需要进行数据预处理。
2.2 数据集
我们有 8523 个训练集和 5681 个测试集,训练集同时包含输入变量和输出变量。需要根据训练集来预测测试集的销售额。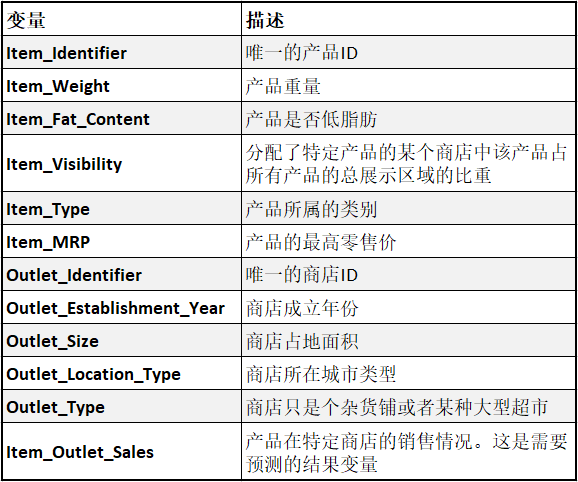
2.3 评估指标
您的模型性能将根据您对测试数据(test.csv)的销售预测进行评估,该测试数据包含与列车类似的数据点,但要预测的销售除外。您的提交需要采用“SampleSubmission.csv”中显示的格式。
我们最终得到了测试数据集的实际销售额,您的预测将用于评估。我们将使用均方根误差值来判断您的响应。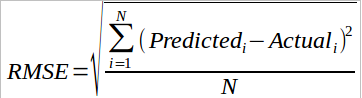
其中,
N:观察总数
Predicted:用户输入的响应
Actual:销售的实际值
另请注意,测试数据进一步分为公共(25%)和私有(75%)数据。您的初始回复将在公共数据上进行检查和评分。但是,最终排名将基于私人数据集的得分。
数据集的下载需要报名参赛才能获取,这边直接提供:
0f34cc05eb4349c7a36f21431e68bb77_.zip
