
wangwei


机器学习, 数据采集, 数据分析, web网站,IS-RPA,APP
python基础 RPA XML 数据提取 • 1 回帖 • 1K 浏览 • 2019-08-23 14:03:12
机器学习, 数据采集, 数据分析, web网站,IS-RPA,APP
python基础 RPA XML 数据提取 • 1 回帖 • 1K 浏览 • 2019-08-23 14:03:12
python 对 XML 的解析 -1(在 RPA 业务中,有时会遇到 XML 的数据格式,下面来看看怎么提取数据)
python对XML的解析-1(在RPA业务中,有时会遇到XML的数据格式,下面来看看怎么提取数据)
举例数据
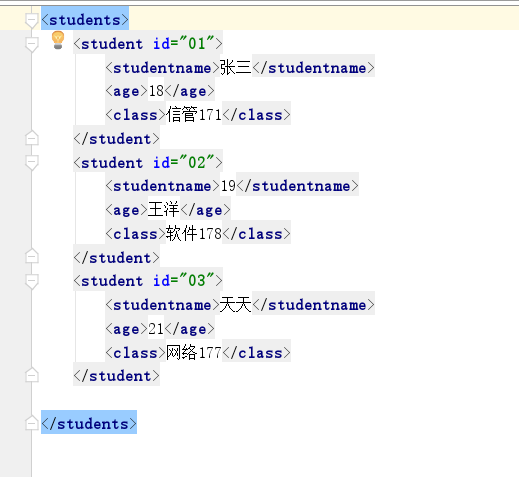
代码
#!/usr/bin/env Python3
# -*- coding: utf-8 -*-
# @Software: PyCharm
# @virtualenv:workon
# @contact: contact information
# @Desc:python对XML的解析
__author__ = '未昔/AngelFate'
__date__ = '2019/8/23 12:27'
#引入parse的包
from xml.dom.minidom import parse
doc=parse("E:\python\Study\小经验+艺赛旗\data\student.xml") #先把xml文件加载进来
root=doc.documentElement #获取元素的根节点
students=root.getElementsByTagName('student') #找到子节点,得到的是一个数组
for student in students: #把所有的子节点进行遍历
print("===student====")
if student.hasAttribute('id'): #如果有ID属性,则输出
print('学生的ID是:%s'% student.getAttribute('id'))
studentname=student.getElementsByTagName("studentname")[0] #根据标签名找到,并且输出第一个元素
print("姓名是:%s"%studentname.childNodes[0].data) #输出标签名的子节点的第一个值,并转为data类型
age=student.getElementsByTagName("age")[0]
print("年龄是:%s"%age.childNodes[0].data)
class_=student.getElementsByTagName("class")[0]
print("班级是:%s"%class_.childNodes[0].data)
结果
D:\import\python3.7\python.exe E:/python/Study/小经验/python对XML的解析/python对XML的解析.py
===student====
学生的ID是:01
姓名是:张三
年龄是:18
班级是:信管171
===student====
学生的ID是:02
姓名是:19
年龄是:王洋
班级是:软件178
===student====
学生的ID是:03
姓名是:天天
年龄是:21
班级是:网络177
Process finished with exit code 0

赞