


如何在数据量不同的 TXT 文本中拿到所需的数据
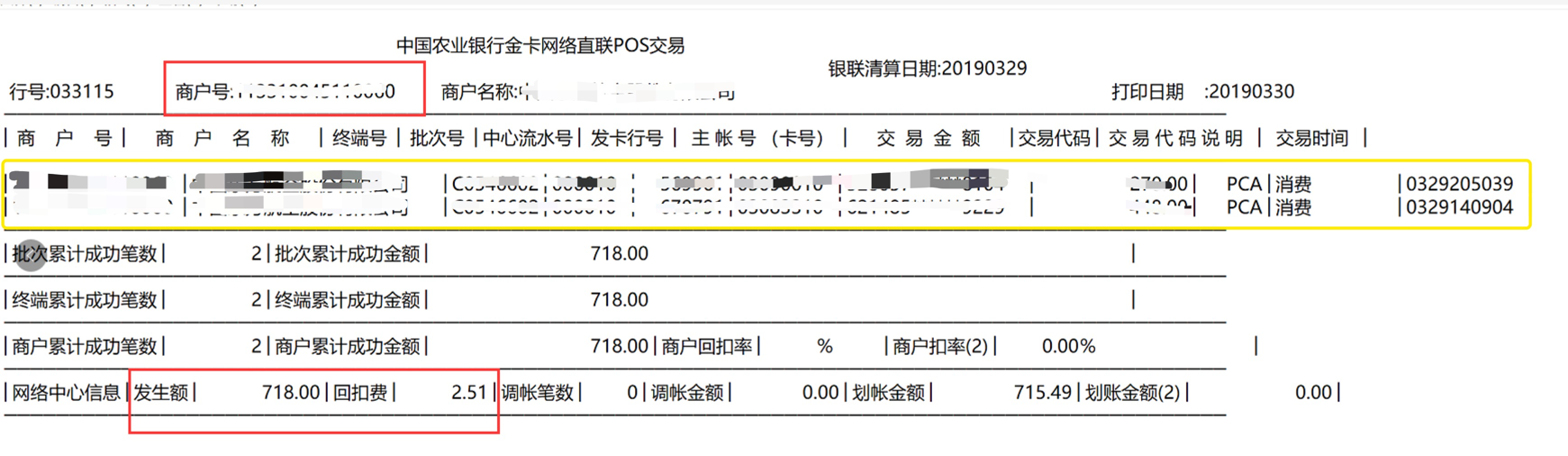
如图,需要拿到红色框中的三个数据,中间黄色框的数据量不定。刚拿到需求的时候,头痛,没思路,无从下手。无法通过切片去获得,因为不知道中间黄色区域的数据量有多少。
后面想到一个比较方便的方法,代码如下
date = []
with open('C:/file/test/test1/201905/20190330.txt',encoding='gbk',errors='ignore') as f:
words = f.readlines()
for i,rows in enumerate(words):
ret3 = re.findall(r'[^\.\d](\d+\.\d+|\d+)[^\.\d]', rows)
if ret3 == []:
pass
else:
date.append(ret3)
print(date)
sh_nu = date[1][1] # 商户号
fs_nu = date[-1][0] # 发生额
hc_nu = date[-1][1] # 回扣费
print(sh_nu,fs_nu,hc_nu)
解决思路:
通过分析文本中所需要数据的规律可以得到,需要的数据总会在文本的第三行和最后一行,它不会随着黄色区域数据量的变
化而变化,而且,所需的数据都是数字。这样我们通过正则表达式,匹配所有数字,加入列表。要的数据总会在第二个列表和
最后一个列表中,这样就可以快速的拿到所需的数据了。测试了黄色区域数据量较大的文本,也是可以轻松拿到的。
心得:
可能其他项目很少会遇到同样的问题。但是在拿到需求时,如果一眼看上去,挺难的,挺复杂的。我们可以先去找到规律,
分析一下。想好思路,这样开发起来就容易了。

👍
赞一个👍