


设计器执行 print() 语句提示编码错误的原因及解决办法
8.0 已经解决了这个问题。
—————
我们在设计器中打印一个含有中文的字符串时,经常会碰到 UnicodeEncodeError 错误,提示信息如下图所示:
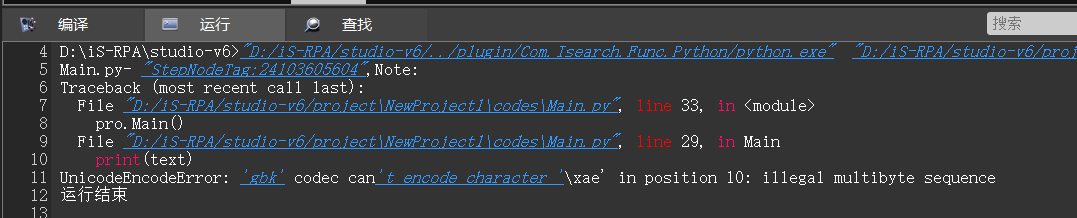
首先要明确一点,python3 对文本以及二进制数据做了比较清晰的区分。在代码中赋值给变量的文本总是 Unicode,由 str 类型进行表示,而二进制数据使用 bytes 进行表示。
字符串在 Python3 内部 (源代码中直接赋值的文本) 表示统一用 unicode 编码,python3 中写字符串用下面两种方式是一样的,结果都是 unicode 编码, 也就是说在默认情况下,被引号框起来的字符串,都是使用 Unicode 编码的。
a = '我是a'
b = u'我是b' # python2中的写法,在python3中跟不加u前缀是一样的
非 Unicode 编码格式的文本来源:从网络抓取的网页 / 硬盘文件等来源的字符串可能是比如 UTF-8、GBK,这些编码方式,得到这些数据时一般都是字节流,需要根据文件的编码方式选择对应的解码方式。
容易产生疑惑的地方
- python3 默认编码为 utf-8,赋值字符串时默认编码为 unicode。似乎不太一样?
其实这两个不冲突,默认编码 utf-8 是编码解码字符串时没有传指定编解码参数时使用的默认编码,而 unicode 是源代码里赋值给变量字符串时使用的编码,直接放入内存,大概类似于内存编码
Python 涉及到编码的地方
.py 文件源代码的编码
写源代码时使用的编码是什么,比如中文 windows 记事本默认为 gb2312
编辑器使用哪种编码显示源代码
比如用记事本写源代码再用 pycharm 打开源代码可能就会乱码,因为 pycharm 默认是用 utf-8 显示的
运行界面显示文本的编码
一个脚本在 pycharm 下运行正常, 但到 cmd 下运行就出问题的情况
当使用 print 向运行界面打印信息时,是把这个字符串用默认编码转化成对应的字节给运行界面显示的, 如果你给的字符串编码是 unicode,那么系统会自动根据环境转成对应的 gbk 或 utf-8 去显示。但是如果你给的是 utf-8 然后丢给 cmd 显示,cmd 默认是 gbk 的编码字符,这个时候 print 就会报错。
明确了以上内容,我们可以分别输出一下 pycharm 以及设计器中 print 语句默认的输出编码格式:
import sys
print(sys.stdout.encoding)
在 pycharm 中输出为 utf-8,在设计器中输出为 cp936
cp936 其实就是 GBK,IBM 在发明 Code Page 的时候将 GBK 放在第 936 页,所以叫 cp936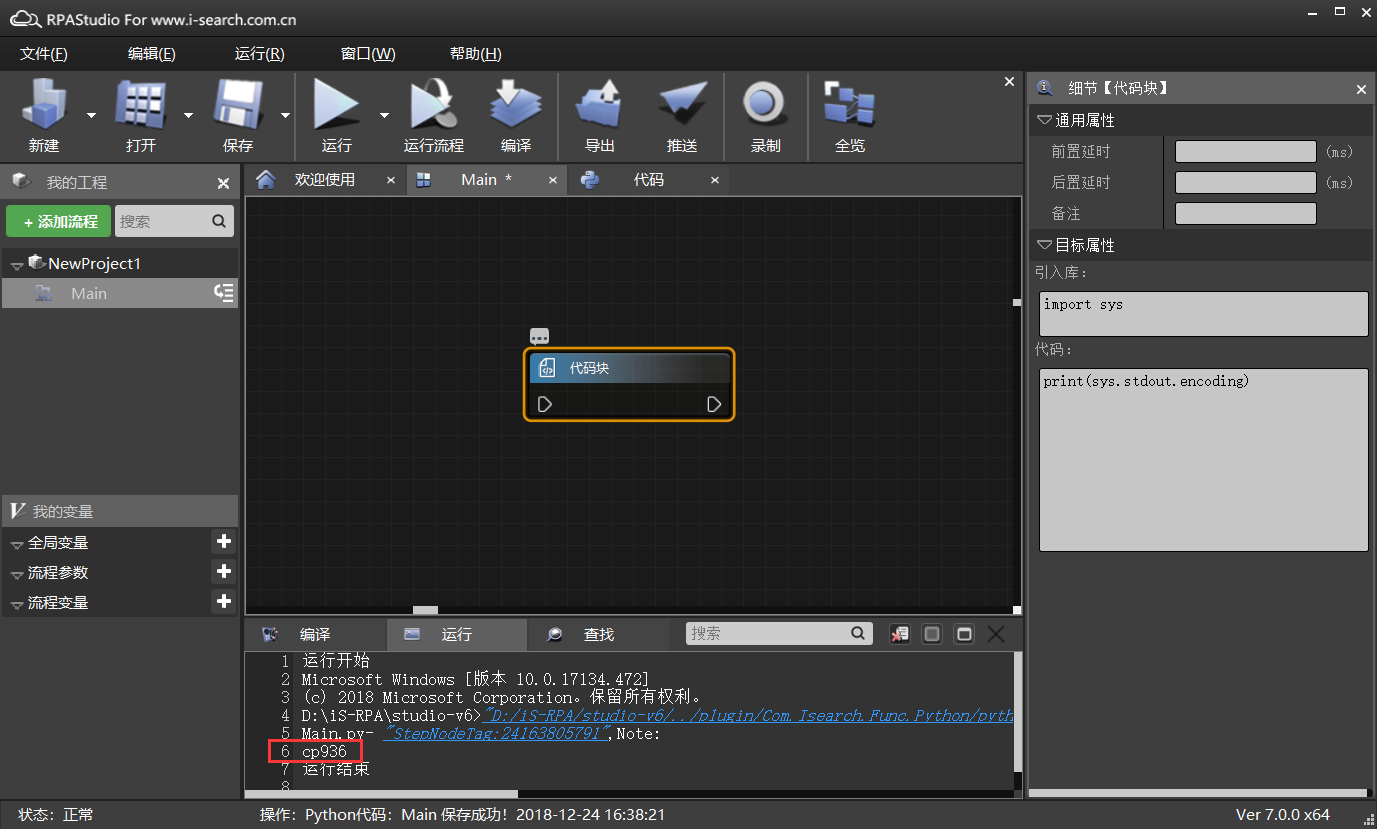
我们可以打印一下系统默认编码,发现设计器输出栏的编码格式与系统默认编码一致:
>>> import locale
>>> locale.getdefaultlocale() # 系统当前编码
('zh_CN', 'cp936')
那么我们只需要将这个默认输出编码格式改一下,就可以解决问题
在 print 语句之前加入如下代码:
import sys
sys.stdout = open(sys.stdout.fileno(), mode='w', encoding='gb18030', buffering=1)
就可以在设计器中正常打印中文了!
gb18030 的含义参考https://blog.csdn.net/dataastron/article/details/79148574
