

获取网页表格异常情况分析处理
首先各位同学如果想获取网页中的表格,请先熟读以下两篇帖子,了解基本原理以及方法。
详:http://support.i-search.com.cn/article/1538019514108
详:http://support.i-search.com.cn/article/1535445990145
从上面的帖子中可以看到想要获取网页中的表格,我们首先要获取到网页中的 TABLE:nth-of-type(1) 标签, 但是近期在处理的一个网页表格中,我们无法获取 table 标签。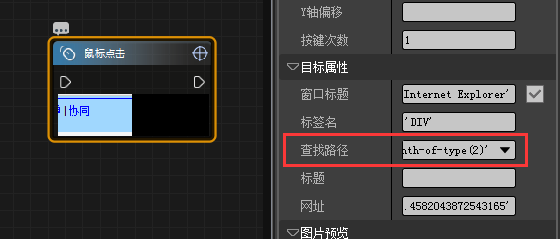
‘body > DIV:nth-of-type(1) > DIV:nth-of-type(2) > DIV:nth-of-type(1) > DIV:nth-of-type(5) > DIV:nth-of-type(1) > DIV:nth-of-type(2)’
同样我们尝试之前帖子的方法获取网页表格信息,读取了一个 TD 格式的表格,随后使用 pandas 去获取表格信息并且打印发现始终报错
‘gbk’ codec can’t encode character ‘\xa0’ in position 3555: illegal multibyte sequence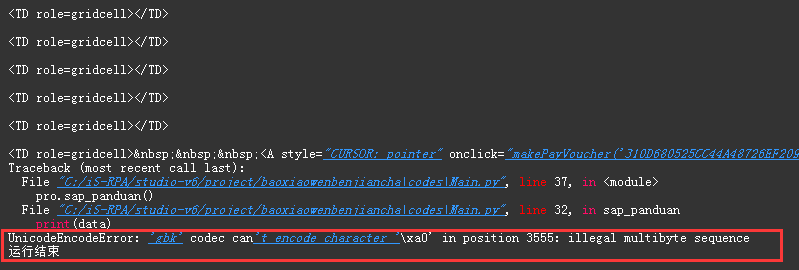
刚开始以为是表格获取的有问题,所以又通过设计器封装的 getTableHtml 的方法,如下:
def getTableHtml(param=None):
param='{"activite":"getText","target":{"selector":".k-grid-content","tag":"TABLE","title":"交易明细"}}'
result = getHtml(param) #其中k-grid-content 为表格的类名,可通过浏览器开发者工具获取得到
return result.obj
发现还是同样的情况,依旧报
‘gbk’ codec can’t encode character ‘\xa0’ in position 3555: illegal multibyte sequence
所以我们百度了多种方法尝试将’\xa0’去除掉,但是始终无法获取到表格的 dataframe
后来在论坛上找到了http://support.i-search.com.cn/article/1530262694765 这篇文章,通过 5.0 设计器,尝试了以下,发现同样的 table 表格,居然可以读取出来。并且在 7.0 设计器自带的 python 编译器也能正常获取 dataframe。于是判断是否是表格格式有异常导致设计器编译器无法读取呢,随后借助以上帖子的方法,先将读取的表格前后加上’Table’标签,将读取的表格格式先进行了转换,然后再次读取转换后的 list,发现可以正常获取表格数据了,如下代码:
import pandas as pd
import numpy as np
import os
from ubpa.base_ie import *;
lv_data = "table" + lv_data + “table” #table 要加 <>,如截图
df = pd.read_html(lv_data)
df_list = np.array(df[0]).tolist()
print(df_list)
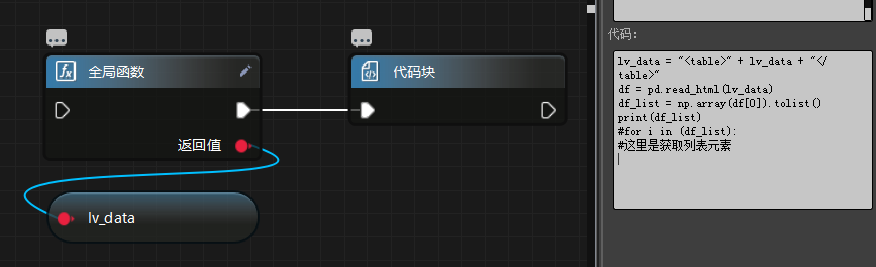
其中全局函数为上面 getTableHtml。
运行后就获取到我们想要的结果:
备注:这次的表格获取的情况比较特殊,大部分的网页表格都可以通过开头提到的两篇帖子的方法获取到,所以建议大家好好学习一下,很多场景会用的到。
另外要感谢一下研发部谭彬彬的协助及方案。
