
内置 OCR 识别引擎 (Tesseract)
随着 OCR 场景的增多,在某些用户环境下不能够使用在线的 OCR 识别;现在介绍一种内置的 OCR 识别引擎;
针对一些简单的验证码,或者一些简单的图片识别还算准备。
后续我们也讲研究 tensorflow 使用机器学习来形成自身的 OCR 机制,敬请期待 😄
具体使用方式:
* 下载安装引擎包 Com.Isearch.Tesseract.zip
;将其解压到 plugin 目录下
* 下载更新pytesseract.py 覆盖 plugin\Com.Isearch.Func.Python\Lib\site-packages\pytesseract\ 目录
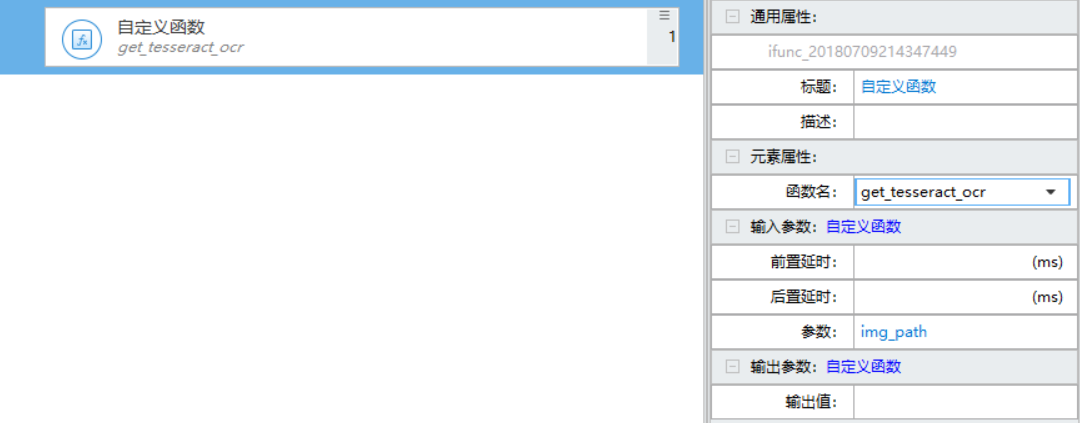
* 自定义函数 get_tesseract_ocr
from PIL import Image
import pytesseract
def get_tesseract_ocr(img_path,lang=None):
txt = None
try:
image = Image.open(img_path)
txt = pytesseract.image_to_string(image,lang=lang)
if txt != None:
txt = txt.replace(' ','')
print(txt)
except Exception as e:
raise e
finally:
return txt
lang=eng ,lang=chi_sim, lang=eng+chi_sim
- 调用方式(如下图)

下载了但是 plugin 下没有 Com.Isearch.Func.Python 这层目录咋整
下载解决了,但是我 plugin 下面没有 Com.Isearch.Func.Python 目录咋整
引擎包下载不了啊咋回事
写的很好,很完整