

通过设计器对数据表格的处理
在 RPA5.0 的版本当中,增加了一个非常强大的功能,那就是对数据表格的处理,就是说可以通过读取 Excel 文件,将 Excel 文件中所有的记录读取出来,在通过条件过滤、排序、计算、合并等方法将你需要的数据筛选出来,再进行使用,比如将数据一行行的插入系统中还是填入别的 Excel 表格里等。设计器说明书中有明确的写到使用方法,可是还是有不少人来问这个问题,显然没有仔细看说明书,那这里再提一下,希望关注。
这里的方法主要是运用了 Python 的 Pandas 库,对 DataFrame(数据集)进行处理。
-
既然要对数据进行处理,那么第一步肯定是要读取数据源咯,当然如果你已经通过其它方法获取了数据(DataFrame)就可以跳过这一步,在后面的步骤中直接引用即可。
程序-> 表格数据 -> 读取 Excel,引用了 Pandas 的 read_excel 方法,学习资料:read_excel
路径用来填写 Excel 文件的实际路径
sheet_name 用来指定 sheet 页,可以是 sheet 的全称,也可以是 index
header 用来设置表头位置(其它参数及详细说明请详细阅读《5.0 设计器说明书》)
变量名自己设定,读取出的所有数据集就存放在这个变量中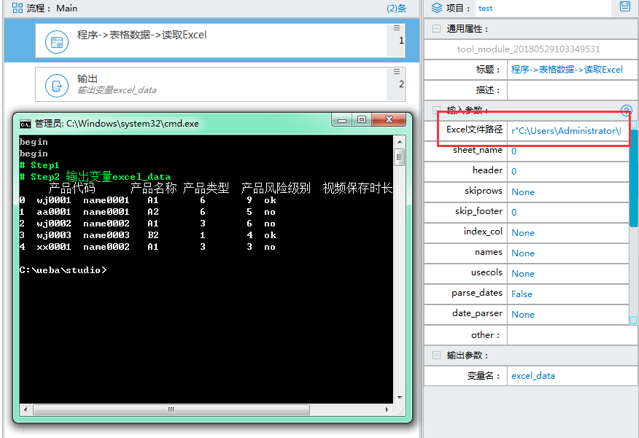
-
读取数据之后,就可以对数据集进行操作啦
程序-> 表格数据-> 过滤
在这里例子中,我想过滤出产品名称这一列中值为 A1 的行
首先在表格选项中引用上一步输出的数据集变量
在参数中输入列名,需要加单引号,后面选择条件,最后选择需要匹配的值就可以了,再存为变量进行输出,就这么简单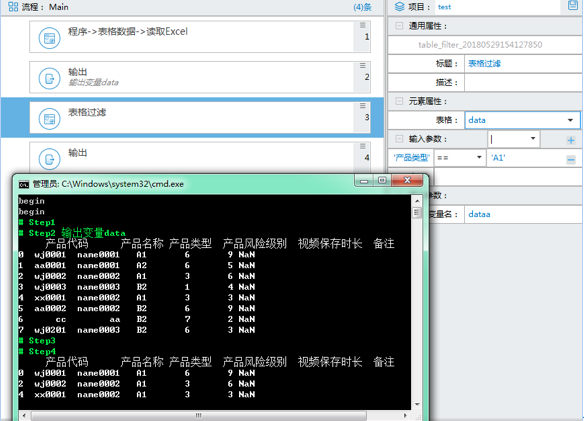
参数中可以增加多个条件,条件之间可以为“或”和“并”的关系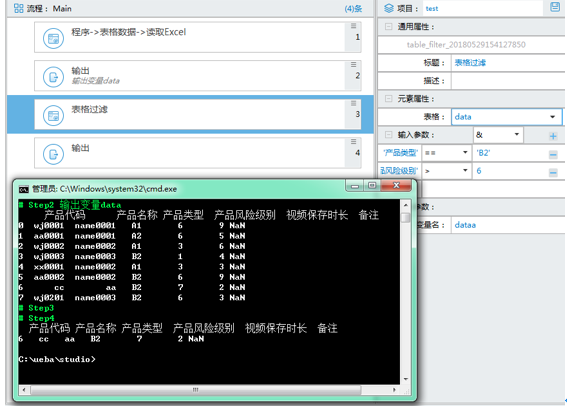
除了常规的=、<、> 的操作,还有 startswith(字符开头匹配)、notna(去空)等条件,详细请仔细阅读《5.0 设计器说明书》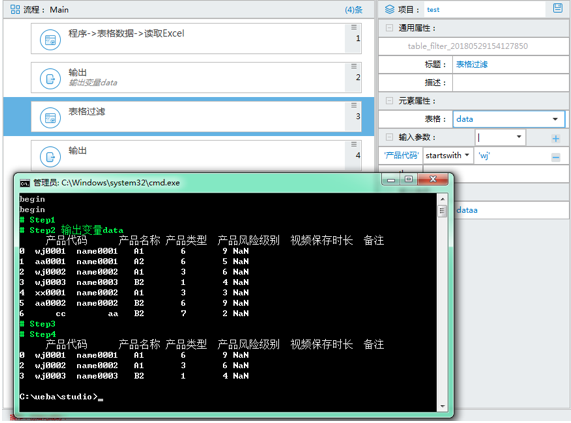
还支持了合并、排序、统计等功能。 -
过滤完的数据依然是存储在数据集中,如果需要一条条的调用,可通过 for 循环来实现,其中也包含了两种方法。
方法一:直接在 for 循环中使.iterrows() 方法
for index,row in 表格变量.iterrows()
在输出中打印 row 即可
通过定义变量,取得数组中的某一个值,如 row[0]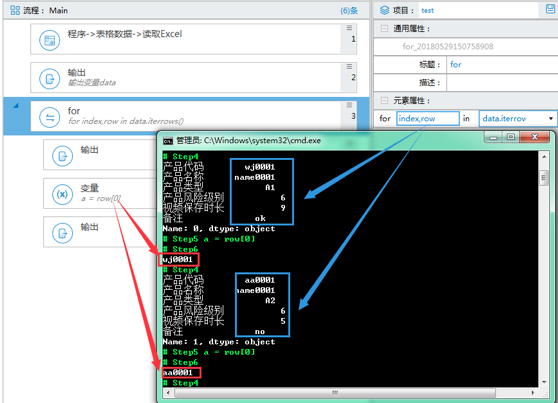
方法二:先使用.values.tolist() 方法转换为 list,再用 for 循环进行调用
如 data_list=data.values.tolist()
data 为读取 excel 输出的变量,data_list 为生成 list 后的变量,存放列表数据
for i in data_list
在输出中打印 i 即可
通过定义变量,取得数组中的某一个值,如 i[0]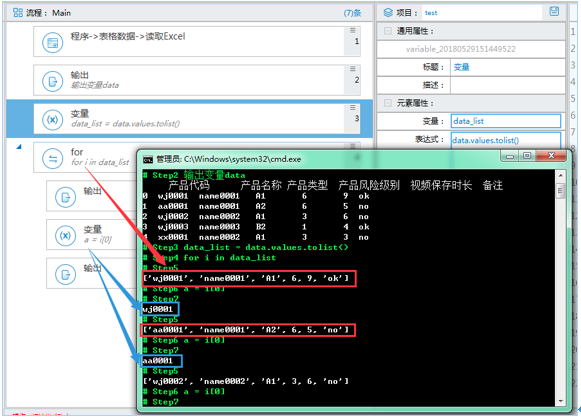
大致的说明就到这,更多详细的请仔细阅读《5.0 设计器说明书》,更多的去操作和实践。
以上功能在 6.0 种也同样保留,使用方式一致。

点赞,大家对表格数据多试多用,异常强大的数据处理能力 👍