

Table 表单内容获取
用户场景中,可能会经常遇见如下表格类型,表格内容会变化,需要取里面某行或某格内容。
下面介绍如何获取表格内的内容,以 CSM 产品列表为例,获取最后一行的产品代码,
界面如下。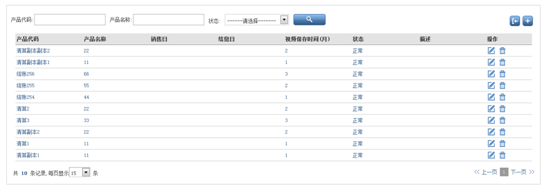
需要用到两个函数:
下面是使用教程:
-
设计器中选择【浏览器】的“单击元素”,选中外层的 table 框
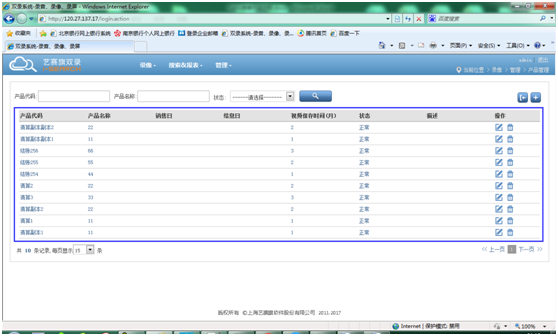
-
选择【自定义函数】,将函数内容 copy 至自定义函数编辑器内并保存ifun.rar
-
编译后,将【单击元素】步骤对应代码中的 selector 内容复制下来,这个例子中如 #boxTable
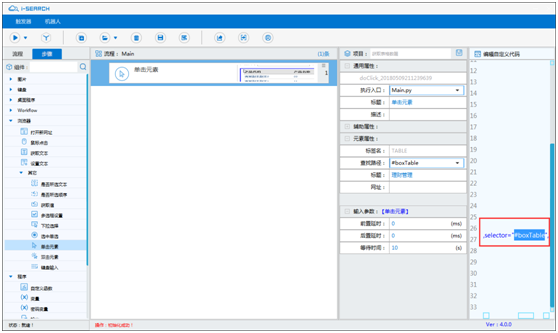
-
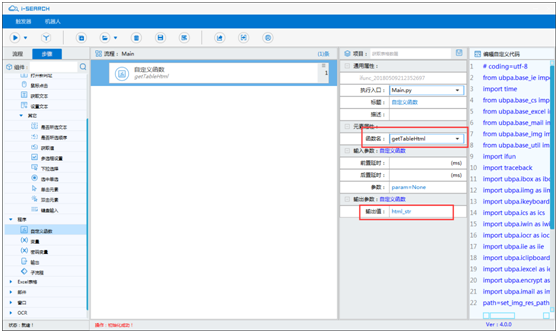
打开【自定义函数】编辑器,将刚刚复制的内容,黏贴到第一个函数 getTableHtml 以下位置中,注意双引号
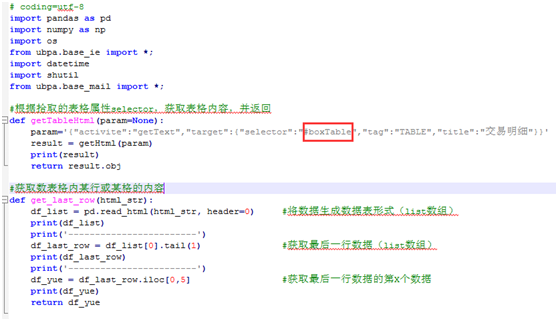
-
获取完页面 Tabke 表格的 selector 元素值后,可删除【单击元素】步骤,加入【自定义函数】,并选择 getTableHtml 函数,输出值输出 html_str
-
编译运行第一步,调试框里已经输出了表格内的内容,只是显示不太直观,我们可以使用 python 编译器来直观的观察该数据表格。之前需要先把该内容复制到一个 txt 文件中。
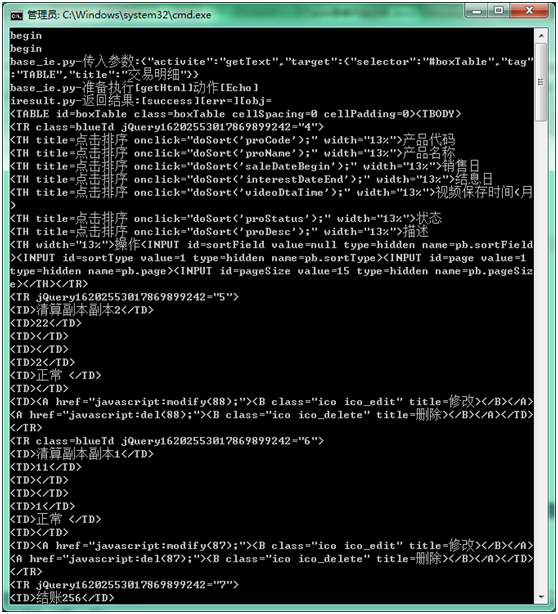
-
内容中以表格内容为开始结束,复制中间该段表格代码
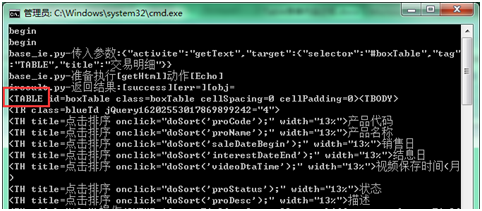
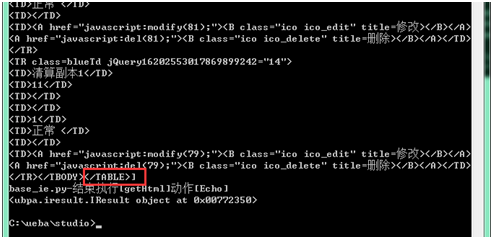
-
复制的文本 copy 至记事本中
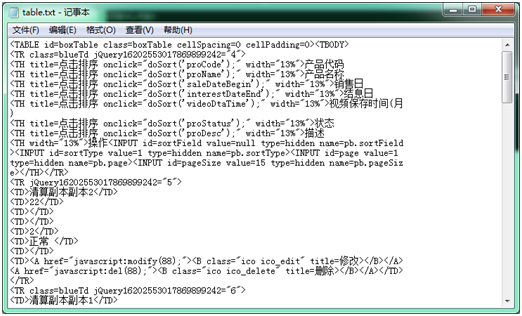
-
打开自带的 idle 编译器,右键管理员身份运行 C:\ueba\plugin\Com.Isearch.Func.Python\idle.bat
-
首先导入 pandas 库,定义 df_lista 变量的内容为文本中的内容,打印 df_lista,图中可看出返回的是一个 list 列表,这样看比之前直观多了

-
使用 df 的 tail 方法获取最后一行,并赋值给 df_last_row 变量
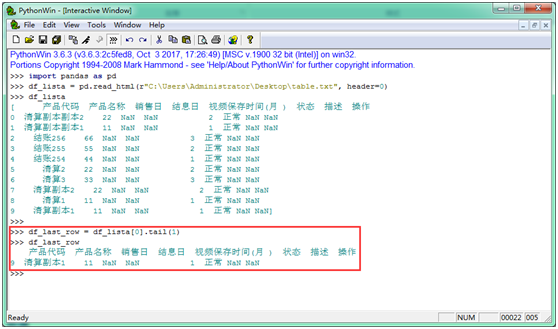
-
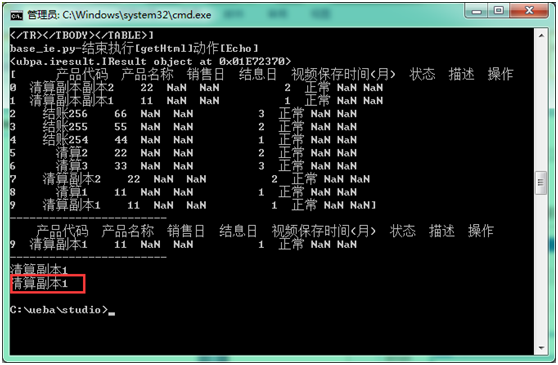
使用 iloc[0,0] 方法,获得 index 为 0 的行,index 为 0 的列内容,如下获得内容为清算副本 1,如 iloc[0,1],则获得内容为 11
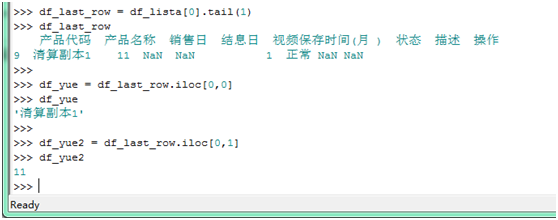
-
在【自定义函数】中修改相关代码,根据 python 编辑器中运行测试结果修改
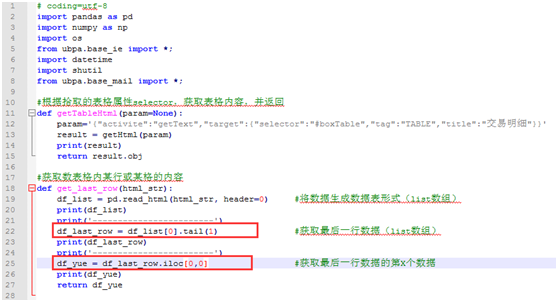
-
【自定义函数】调用 get_last_row 函数,将获取的最后一行记录的产品代码输出到 pro_id 变量中。
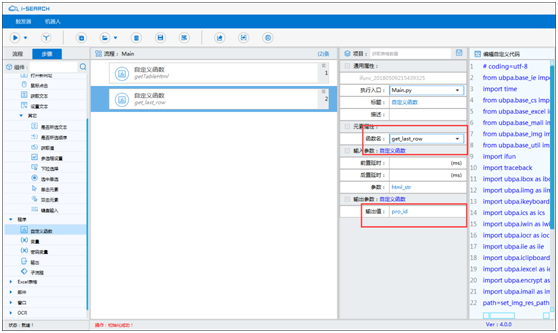
-
输出打印该变量内容,检验获取内容是否正确。
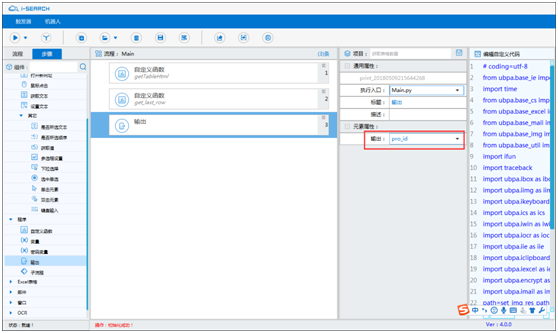
-
打印内容,该变量就可供后续步骤进行调用
工程及函数:获取表格数据.rar

无法确定一个标签具体位置;原因:标签 ID 属性随时变更;
为获取到想要信息内容,只能先将表格内数据全部取出;
获取方式和方法:
A、 导入后台代码模块;
B、 自定义函数
C、 修改 selector 指定参数
D、返回的结果值为 HTML 代码
注释:此实现方法和调用函数虽然看着不同,但和主贴读取 HTML 文件的原理是一样的,这个只是在写参数时更方便一些;
def get_last_row(html_str):
#html_str = html_str.replace(‘’, ‘‘).replace(’’, ‘‘)
html_str = html_str.replace(’’, ‘‘).replace(’’, '')
print(html_str)
学习,不过还没太明白。。。先自己研究下
百度上一些资料先存着 https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
今天在支持江峰时,发现 pd.read_html 有一个 bug,就是他只会读取 tbody 的第一个部分即 tbody[0],为临时解决这个问题,查找后完整解决方案如下:
得到的结果是:
也可以简单的去除一下 tbody 的标记:
当然前一种方法较为规范,很多多 tbody 标记后面还有具体的属性(attribute),第一种方法去除的比较干净。
另外需要注意的是,th 表示 table head,这种情况一般不需要指定 header=0
是啊,设计器手册里都写的挺详细了,都配有执行的结果截图,大家平时要先多看手册
从 5.0 开始,不需要太多编程,也可以处理 dataframe 类型的数据了
这些功能可以帮助进行筛选和数据处理