读取Excel
读取Excel
描述:读取目标Excel文件
属性说明
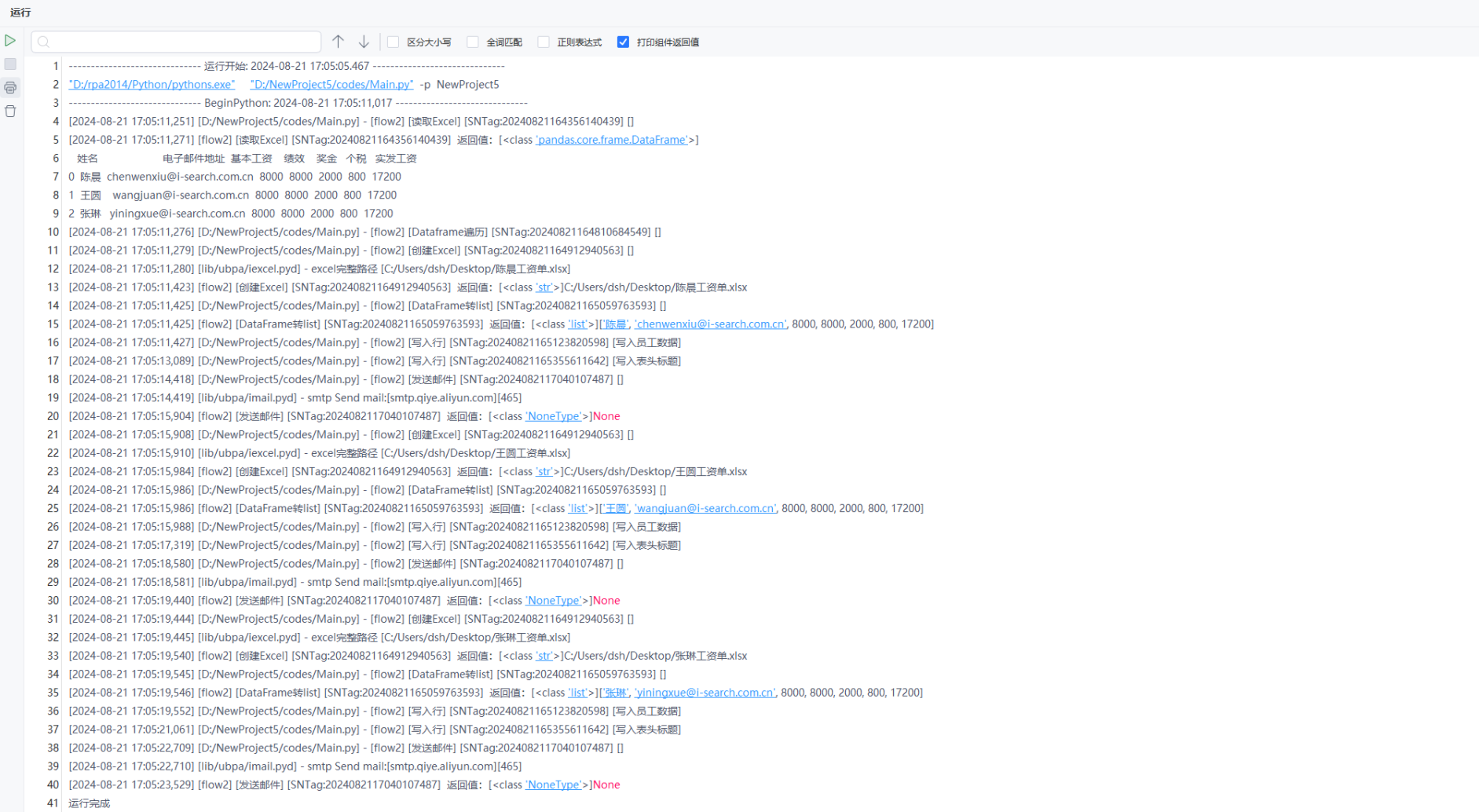
通用属性
- 前置延时- 指可设置组件功能执行之前等待的时间,单位为“毫秒”
- 后置延时- 指可设置组件功能执行后等待的时间,单位为“毫秒”
- 备注- 指对组件进行备注说明,以便于理解和快速定位
目标属性
- 文件路径- 传入需要读取的目标Excel文件的路径,输入为字符串;可点击右侧的文件夹
 图标进行选择
图标进行选择注意
- 输入的是Excel文件的绝对路径
- 手动输入时要确保文件存在,如遇到斜杠转译,可以在路径字符串前添加一个“r”,如*
r'C:/test/data1.xlsx'* - 参数也可传入变量进行操作
- 工作表- 即表格文件的Sheet页,选定读取的目标工作表
注意
- 可输入工作表的索引值,例如
0,表示表格文件的第一个Sheet页;输入2,则表示第三个工作表。输入的数字需要有对应的工作表,否则会抛出异常 - 也可传入工作表名称的字符串,如
'产品详情',需要注意区分大小写以及空格,必须保证完全一致 - 如果需要读取所有的工作表,则可以输入
None;此时返回的便是值为Dataframe的有序字典 - 输入工作表下标或名称组成的列表,读取列表内元素对应的工作表;例如输入
[0,2],便是读取表格第一、第三个工作表
- 可输入工作表的索引值,例如
- Header- 指定作为表头的行,输入为整型数据或None
注意
- 默认为0,表示以读取的第一行作为表头,表头以下数据为数据。例如,若此处输入1,则表头为所读取表格的第二行,第二行以下部分为读取的数据:
- 若表格数据不含表头,则可设置为
None,默认列的下标作为表头
- Skiprows- 从所读取表格的第一行开始,设置省略跳过的行数。默认为None,也就是不跳过行,输入int整型,跳过该整数行;例如输入2,跳过两行,即从表格第三行开始读取
- Skip_footer- 从末行开始,跳过省略表格的行数。默认为0,不省略末尾的行,输入int整型,从末尾开始跳过该整数行;例如输入2,则可以省略最后两行
- Converters- 用以设置表格中指定列的数据类型,输入为字典:例如“converters”参数输入{u'视频保存时长':int},定义”视频保存时长”列的数据类型为整型
- Index_col- 指定列为索引列,默认为None,即不进行设置;也可输入工作表中列的下标,或列名的字符串,其对应类型为int整型和字符串
注意
- 默认为0,表示以读取的第一行作为表头,表头以下数据为数据。例如,若此处输入1,则表头为所读取表格的第二行,第二行以下部分为读取的数据
- 若表格数据不含表头,则可设置为
None,默认列的下标作为表头
- Names- 参数设置表格中每列的列名
注意
- 默认为None,即不设置,此时默认“header”参数设置的表头为列名,如果“header”参数也默认为为None,则以列的下标为列名
- 传入一个有序集合,如列表或元组等,此处输入列表
[1,2,'三','四','5',6],有序集合的长度要与读取到的表格的数据列数必须是一致,否则报错,提示长度不匹配
- Usecols- 设置获取表格的列数,默认为None,获取所有列数。
注意
- 输入列的下标组成的有序集合如列表或元组,此时只读取列的下标对应的列。例如输入元组(0,1,3),则获取第一列,第二列,以及第四列
- 还可以输入列字母组成的字符串,以逗号,分隔,冒号:表示取范围。例如,输入字符串'A,C:E'获取的是A列,以及C到E列
- Parse_dates- 选择是否将数据解析为日期格式,默认为false,即不会将数据解析为字符串,可以调整为true,即将数据解析为日期格式
- Date_parser: 自定义日期解析函数,若解析为日期时,即会使用设置的日期解析格式函数
- Na_values- 设置某些值作为缺失值(NaN)。例如,当设置为None时, 那么 pandas 在读取数据时,如果遇到 'NA',就会将其视为缺失值
- Thousands- 用于设置千位分隔符,例如,你可以设置 thousands设置为
',',那么 pandas 在读取数据时,就会将,视为千位分隔符 - Convert_float- 若设置为 True,会尝试将所有数据转换为浮点数类型。设置为false时,则不会进行操作
- Dtype- 这个参数用于定义数据的类型。例如,你可以将dtype设置为
{'column1': float, 'column2': int},那么组件在读取数据时,就会将 'column1' 列的数据转换为浮点数类型,将 'column2' 列的数据转换为整数类型 - True_values- 这个参数用于定义表示布尔真值的字符串
- False_values- 这个参数用于定义表示布尔假值的字符串
- Engine- 这个参数用于定义用于解析文件的引擎。可选的值有 'xlrd', 'openpyxl', 'odf', 'pyxlsb'。默认值是 'xlrd'
- Squeeze- 默认为false,即无论数据多少列都返回一个dataframe数据,这个参数如果设为 True,当数据只包含一列时,返回一个 Series
返回值
- 输出至变量- 运行成功后组件会返回读取到的dataframe数据集
使用示例
执行逻辑
场景
以“人力资源管理-工资单生成”为例,展示如何使用RPA读取Excel文件,并在实际业务中自动化生成和发送工资单。
假设一家公司的HR部门每个月需要生成并发送员工的工资单。HR部门希望通过RPA自动化这个流程:可以从Excel文件中读取工资信息,生成个人工资单,并通过电子邮件发送给每位员工。
前置条件
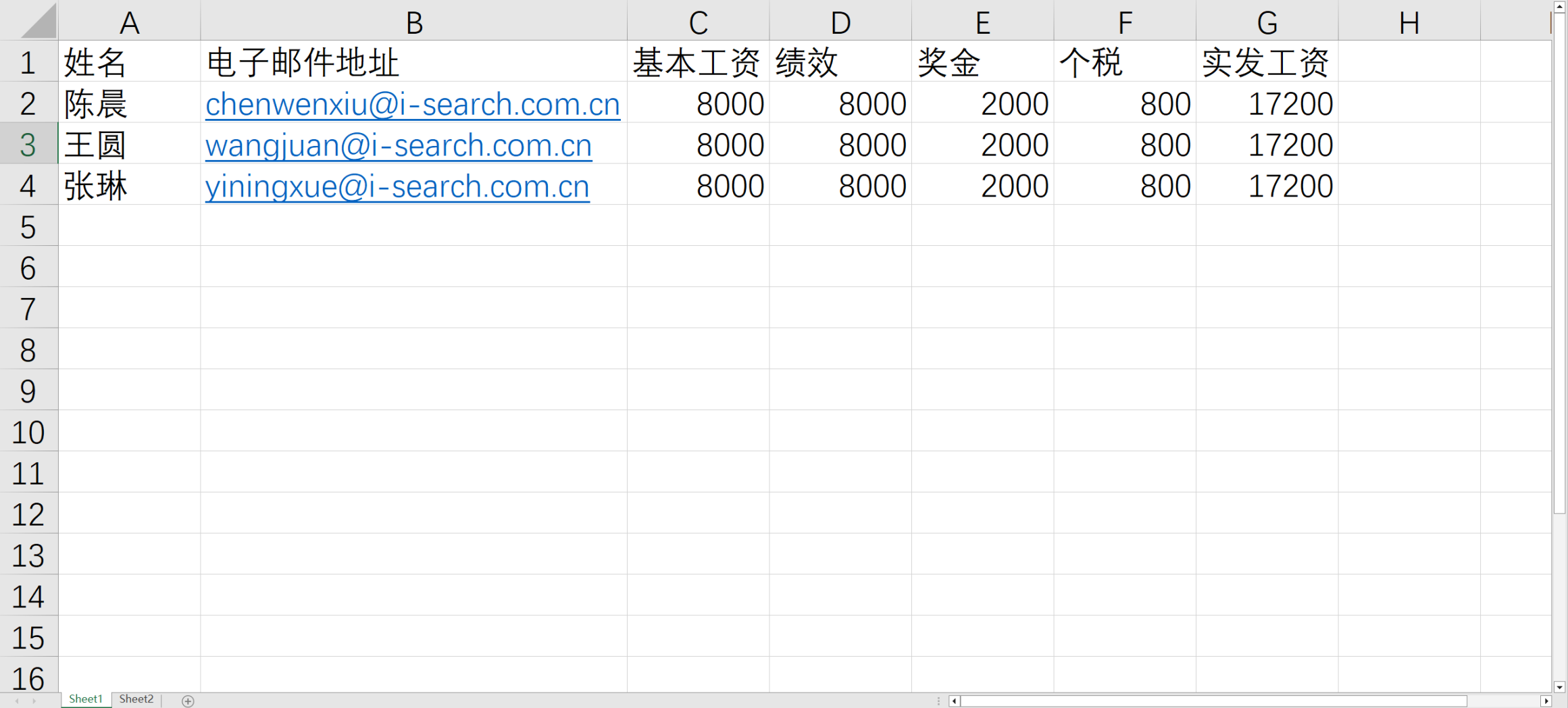
准备一个名为“工资信息.xlsx”的表格,以3个员工的工资信息为示例,工资信息包含姓名、电子邮件地址以及基础工资构成部分。
步骤
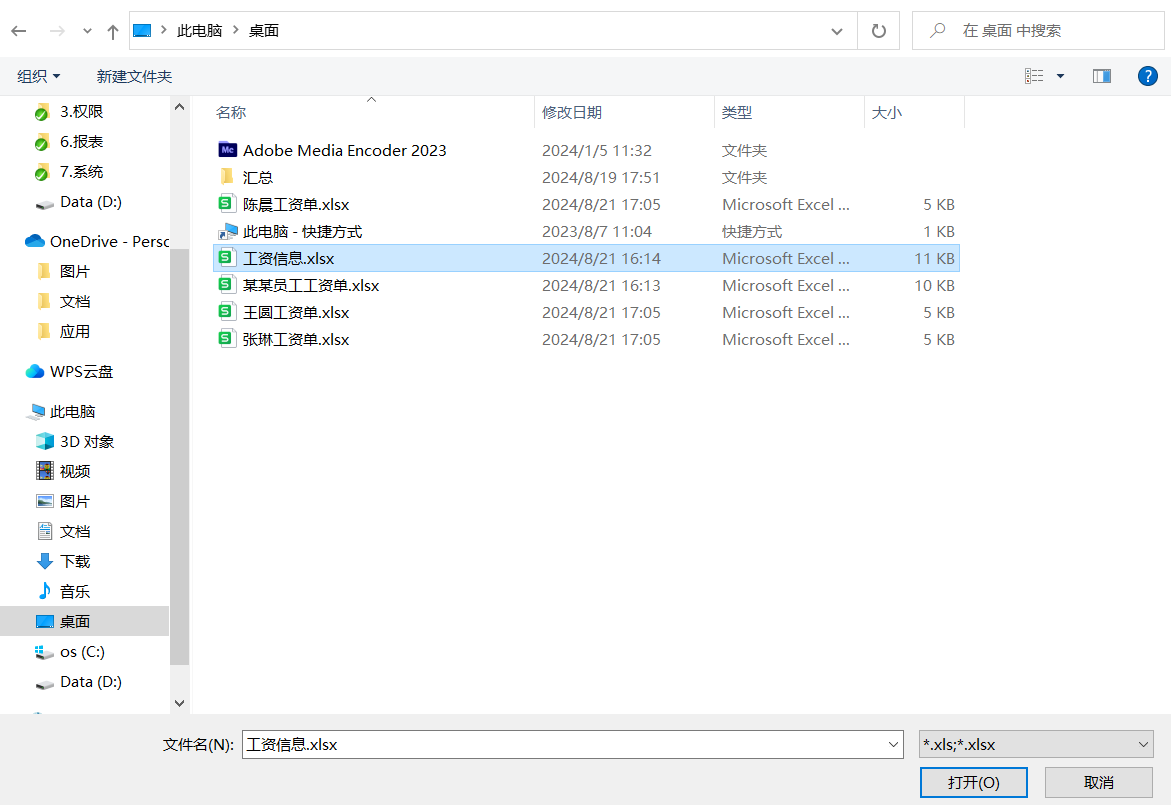
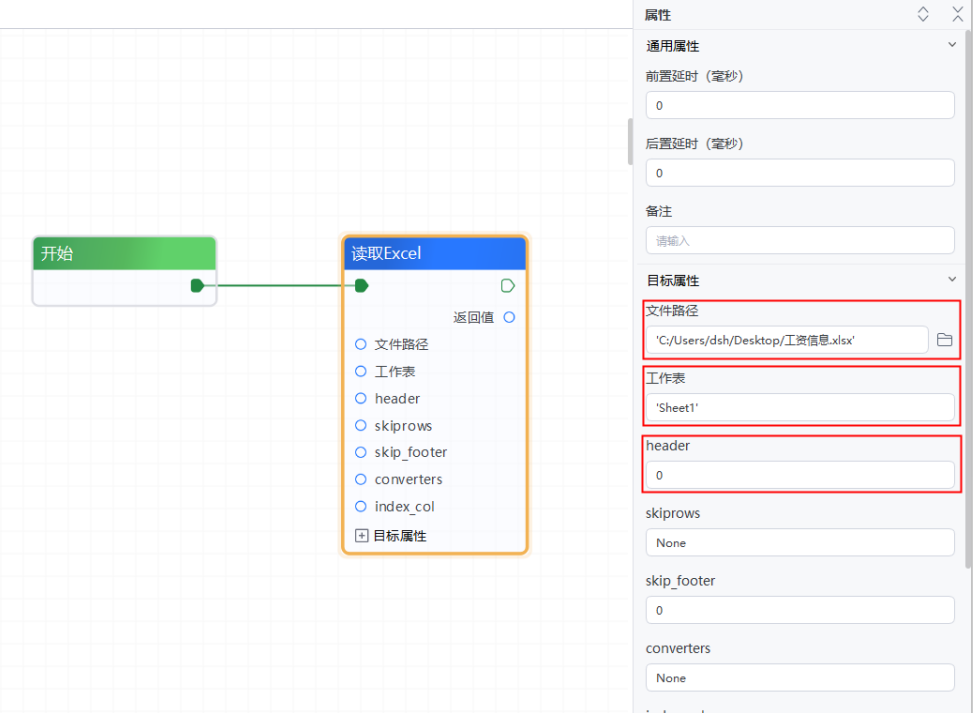
1、新建一个子流程--->拖动开始节点,松手后在弹出的组件弹窗中搜索【读取Excel】组件,选中添加--->在属性面板的“文件路径”处点击图标,选择“工资信息.xlsx”表格--->“工作表”填入对应的sheet页名称:'Sheet1'--->“header”填入:0(即首行作为标头),其他属性保持默认值
Custom_df001
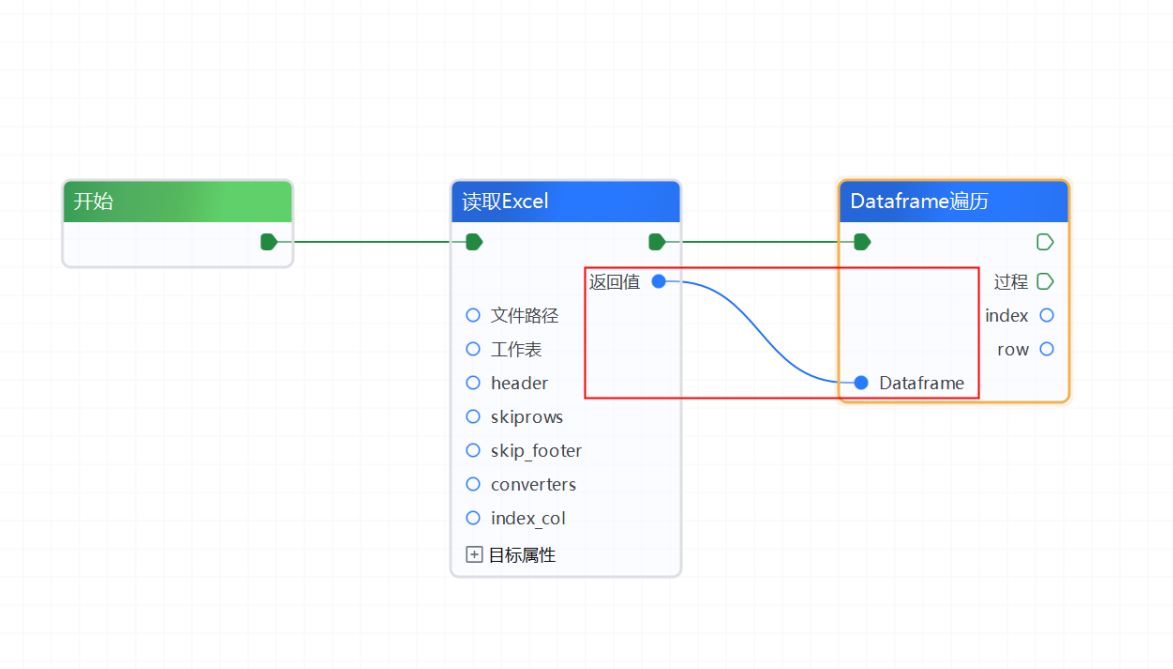
2、添加【Dataframe遍历】组件,将【读取Excel】组件的“返回值”连接到【Dataframe遍历】的“Dataframe”处
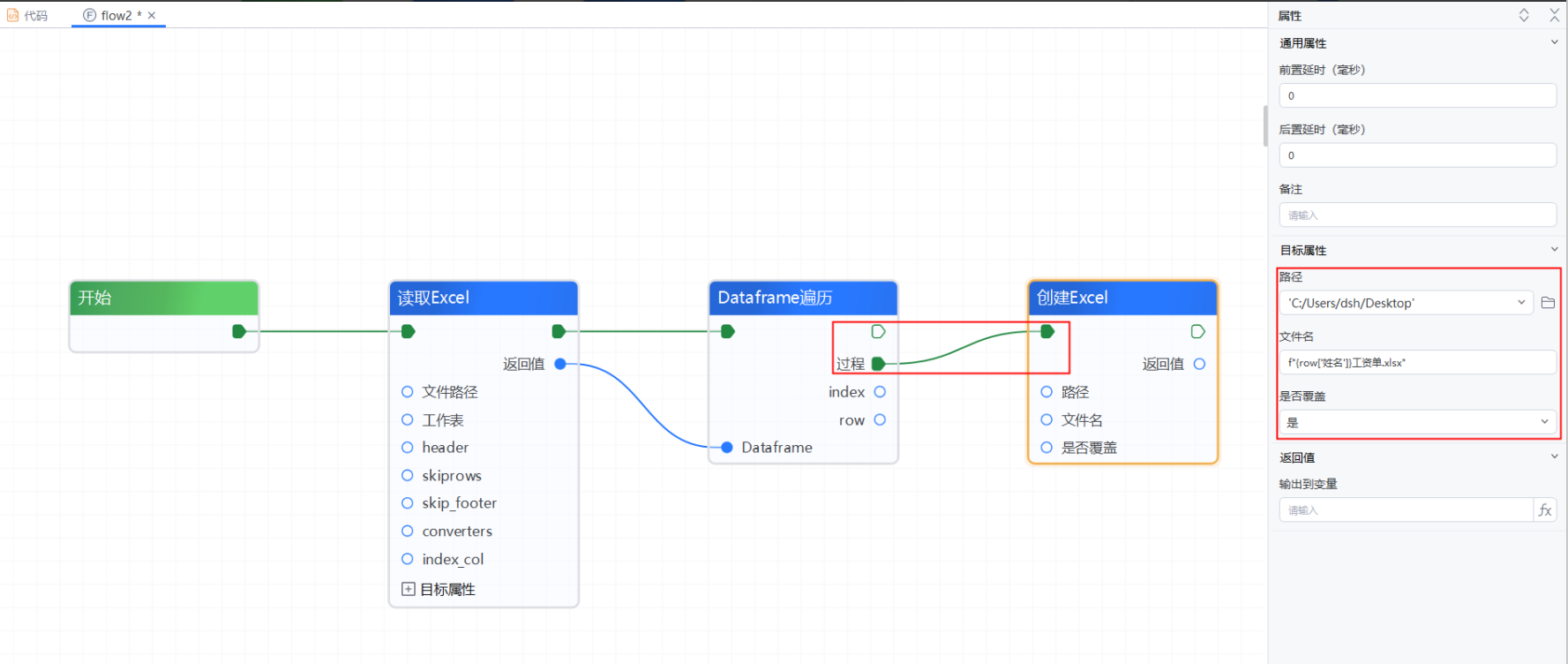
3、添加【创建Excel】组件,并与【Dataframe遍历】的“过程”节点相连--->在属性面板的“路径”处点击图标选择新表格的保存路径,这里选择的是保存到桌面上--->“文件名”输入:f"{row['姓名']}工资单.xlsx"--->“是否覆盖”选择:是
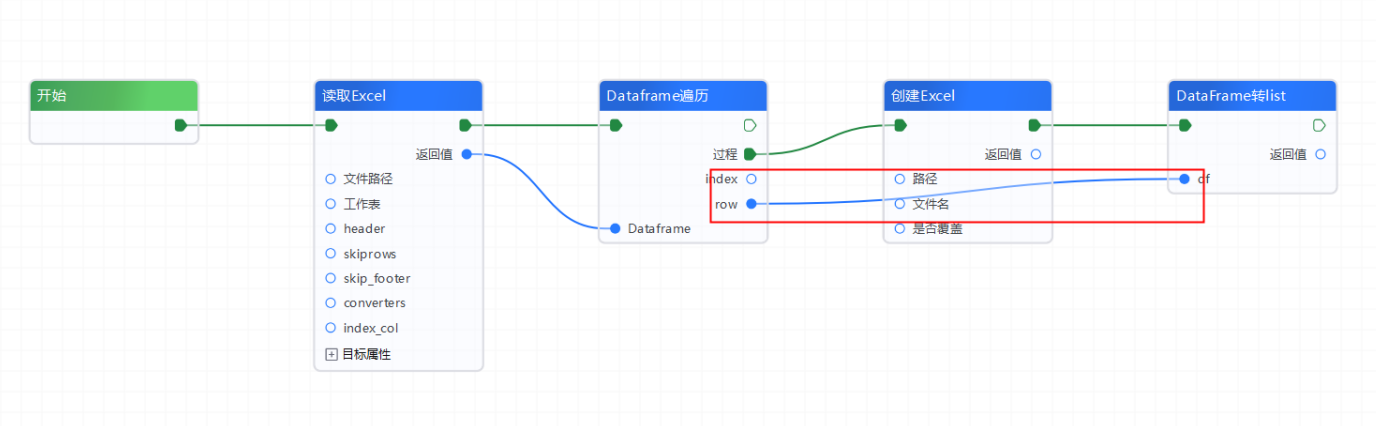
4、添加【DataFrame转list】组件,并将【Dataframe遍历】的“row”连接到【DataFrame转list】的“df”上
5、添加【写入行】组件,将【创建Excel】组件的“返回值”连接到【写入行】的“文件”处--->再将【DataFrame转list】的“返回值”连接到【写入行】的“输入值”处--->“工作表”保持默认值:0;“单元格”输入:'A2';“打开方式”选择:file--->“备注”输入:写入员工数据
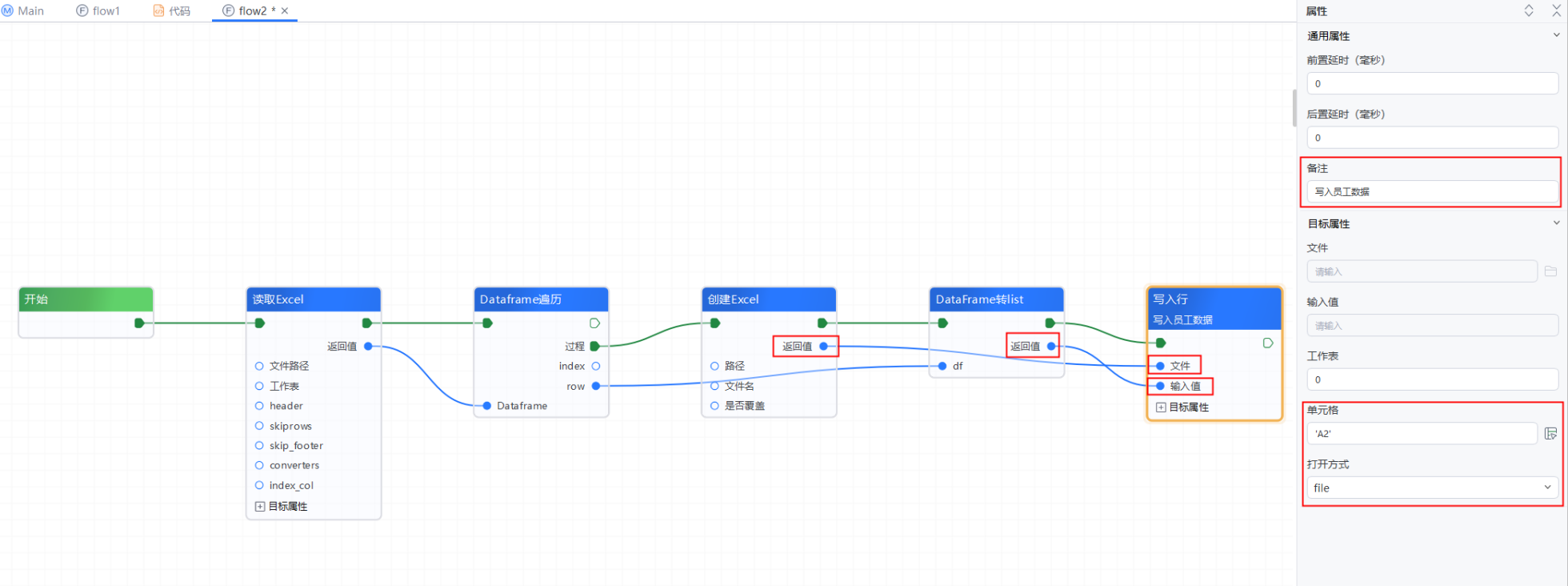
6、添加一个流程参数:pv_1,将【读取Excel】组件的“返回值”连接到pv_1上进行赋值--->再添加一个【写入行】组件,将创建【Excel】的“返回值”连接到【写入行】的“文件”处--->在【写入行】属性面板的“输入值”处输入:pv_1.columns.tolist();“工作表”保持默认值:0;“单元格”输入:'A1';“打开方式”选择:file--->“备注”输入:写入表头标题
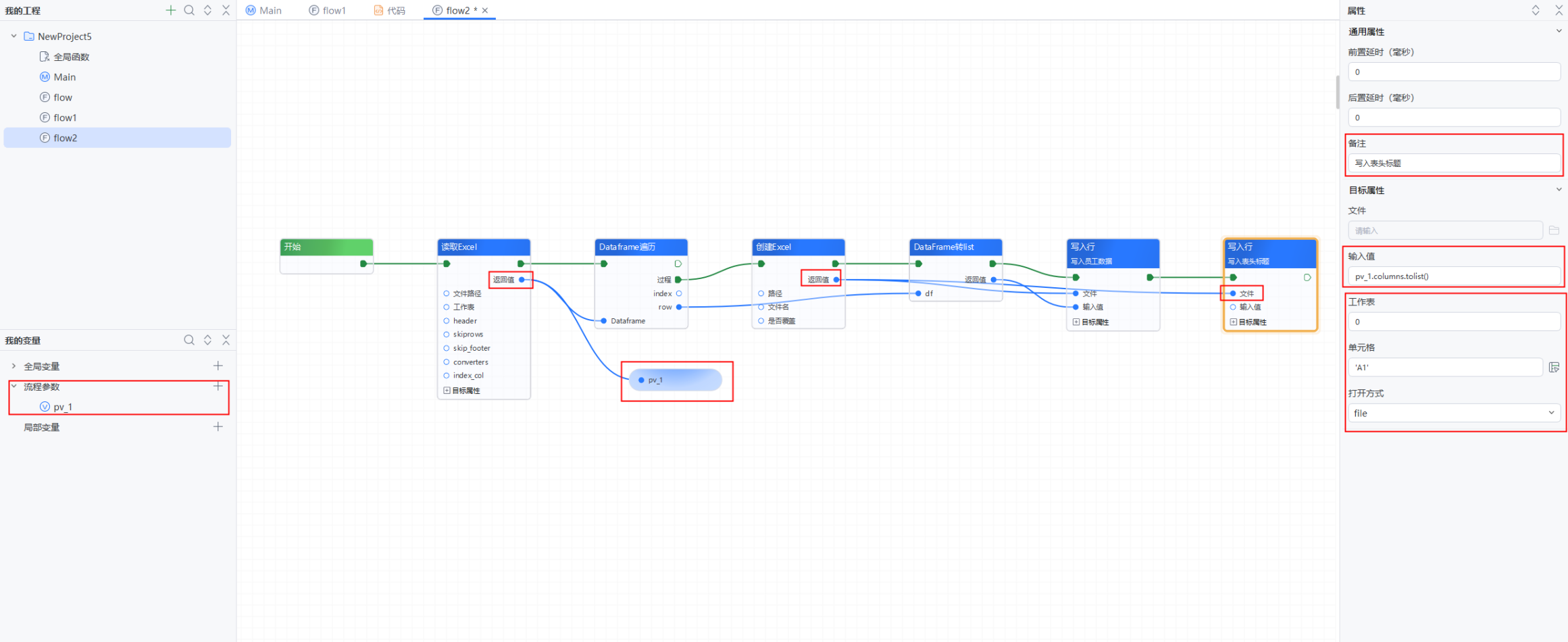
7、添加【发送邮件】组件,将【创建Excel】的“返回值”连接到“附件”处--->“发件人、密码、服务器、端口、ssl”根据自己的邮箱进行设置(具体设置方法可到【发送邮件】组件文档中查看)--->“收件人”处输入:row['电子邮件地址'],即员工的邮箱地址--->“标题”输入:f"工资单-{row['姓名']}",即以“工资单-员工姓名”作为邮件标题--->“正文”处输入:'本月工资单请查收,如有疑问请咨询人事'
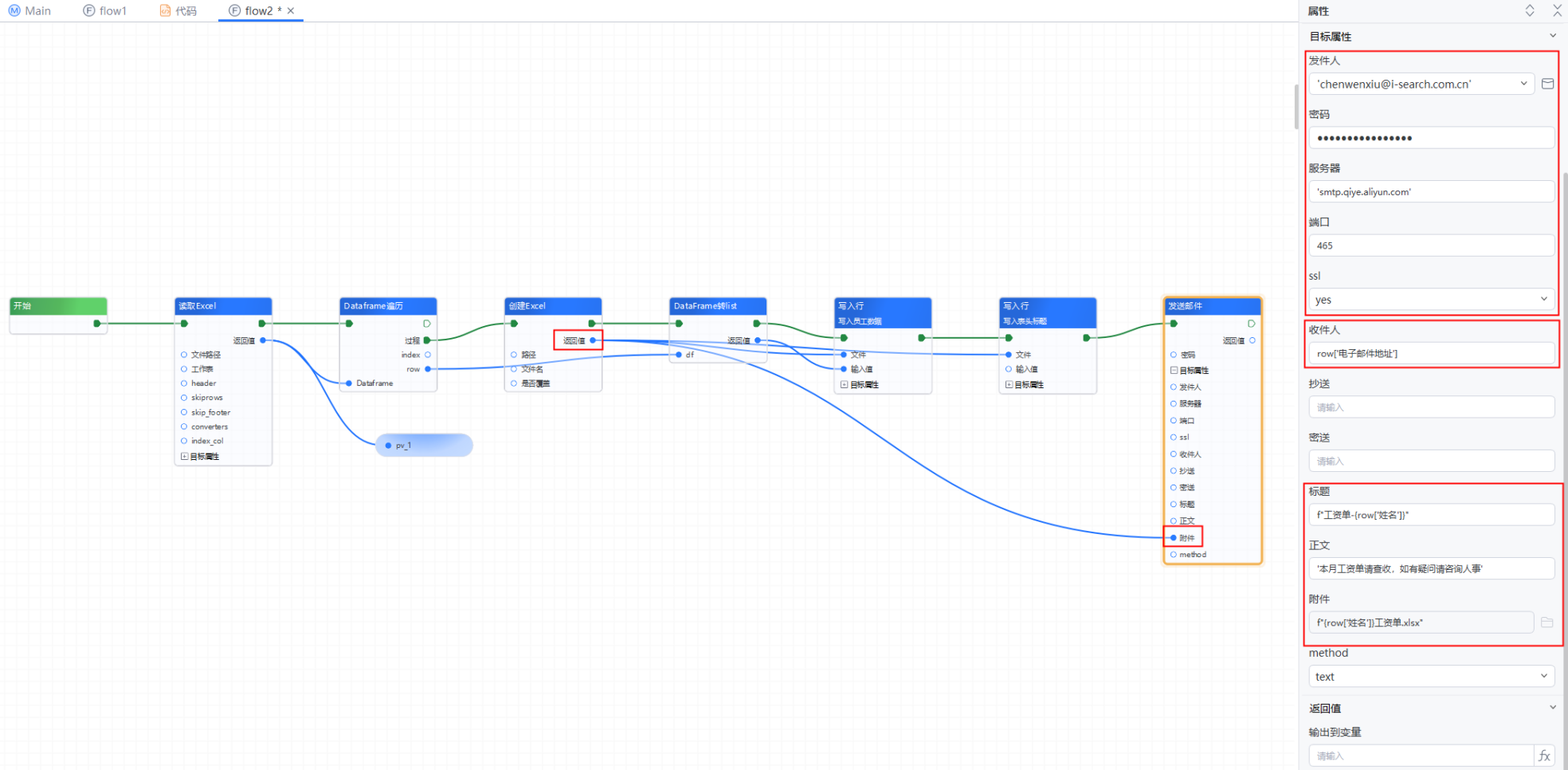
输出结果
运行流程,系统将自动读取《工资信息》表中的所有员工的工资内容分别写入到新表格中,生成员工的个人工资单,并将其作为附件发送给每个员工。