读取CSV
读取CSV
描述:读取CSV文件中的数据,并将读取到的内容进行返回DataFrame数据

注意:
组件使用的是pandas库的read_csv()方法,返回的是一个DataFrame数据集
属性说明
通用属性
- 前置延时 - 组件功能执行之前等待的时间,单位为“毫秒”
- 后置延时 - 组件功能执行后等待的时间,单位为“毫秒”
- 备注- 组件备注说明,以便于理解和快速定位
目标属性
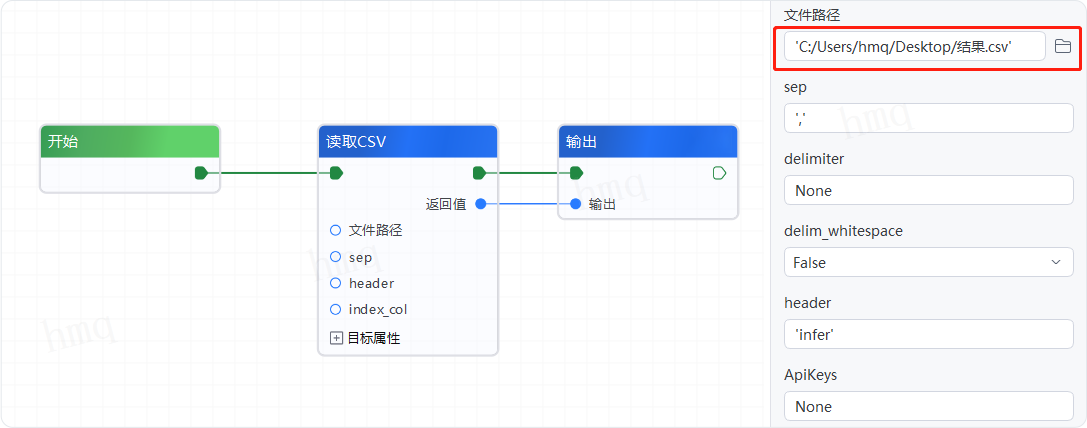
- 文件路径 - 填写读取的CSV文件的路径,输入为字符串,也可点击右侧的文件夹图标进行选择
- Sep - 填写文件的分隔符,输入为字符串,默认为','
- Delimiter - 备选分隔符,输入字符串,默认为None,如果指定该参数,则sep参数失效
- Delim_whitespace - 指定空格是否作为分隔符使用,等效于设定sep='\s+',默认为False,即不设置空格为分隔符,如果这个参数设定为Ture,那么'delimiter'参数失效
- Header - 指定行作为表头,默认为'infer',csv表格第一行作为表头,没有表头则可设置为None,也可输入整型数字或整型数字组成的列表
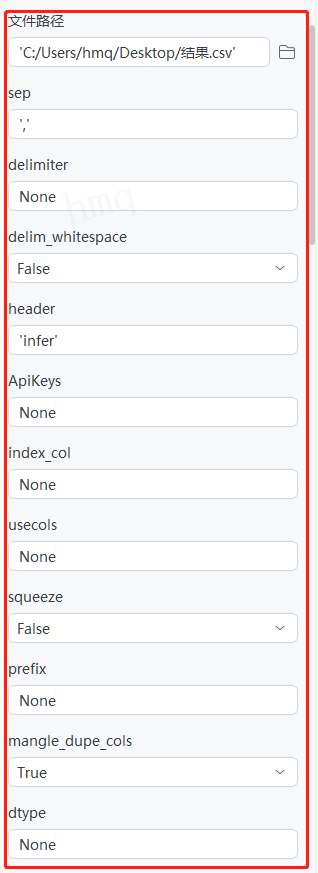
- Apikeys - 用以设置结果表格的列名,默认为None,不设置列名
- Index_col - 指定列为行索引,默认为None,即不设置行索引
- Usecols - 设置获取表格的指定列,返回指定列组成的DataFrame数据集,默认为None,获取所有列,即整个表格
- Squeeze - 默认为False,文件只包含一列的情况下返回值依旧为Dataframe类型数据,设置为True,返回一个Series类型的数据
- Prefix - 在没有列名(header=None)时,给列下标组成的列名添加前缀,默认为None,不添加前缀
- Mangle_dupe_cols - 出现重复的列名时,自动给重复的列名添加后缀,将相同的列名【…X…X…】修改为【…X…X.n…】,默认为True,且不支持False
- Dtype - 设置列的数据类型
- Engine - 设置使用的分析引擎语言,默认为'python',也可以使用'C',C引擎快但是Python引擎功能更加完备
- Converters - 可以在读取的时候对列数据进行变换
- Skipinitialspace - 设置是否忽略分隔符后的空格,默认为False,不忽略,True即忽略
- Skiprows - 设置需要跳过忽略的行数,默认为None,不跳过任何行
- Skipfooter - 从文件尾部开始跳过忽略,默认为0,忽略 0 行;输入整型数字,忽略该整数行数据
- Nrows - 设置读取数据的行数(不包括表头),默认为None,读取所有行,或输入整型数字,读取该整数行数据
- Na_values - 替换表格中指定数据为空值(NA/NaN),默认为None,不替换,输入字符串,将值与之相同的数据替换为NA/NaN
- Keep_default_na - 设置对于表格中空值进行解析的方式,结果根据传入'na_values'参数而定
- Na_filter - 是否检查丢失值(空字符串或者空值),对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度
- Encoding - 填写文件编码格式,输入为字符串,例如'utf-8'、'ANSI'
- 还有很多不太常用的参数,可以查找资料参考pandas库的read_csv方法去进行相关设置
返回值
- 输出到变量 - 返回读取到的CSV文件内容,其数据类型为Dataframe的数据集;可传入变量中保存以供后续组件调用,也可以直接传入其他组件中
使用示例
添加【读取CSV】组件,读取指定Excel表格数据---->目标属性'文件路径'输入被读取的csv文件路径及文件名称---->添加【输出】组件,将读取csv的返回值赋予到输出---->运行流程
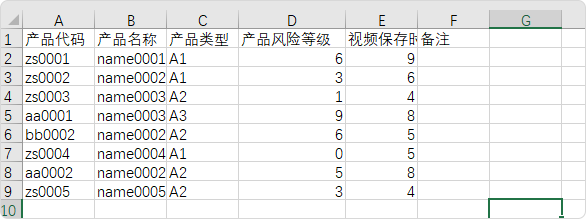
准备被读取的CSV文件,内容如下
情况1:【读取CSV】组件的目标属性全部为默认值---->运行流程
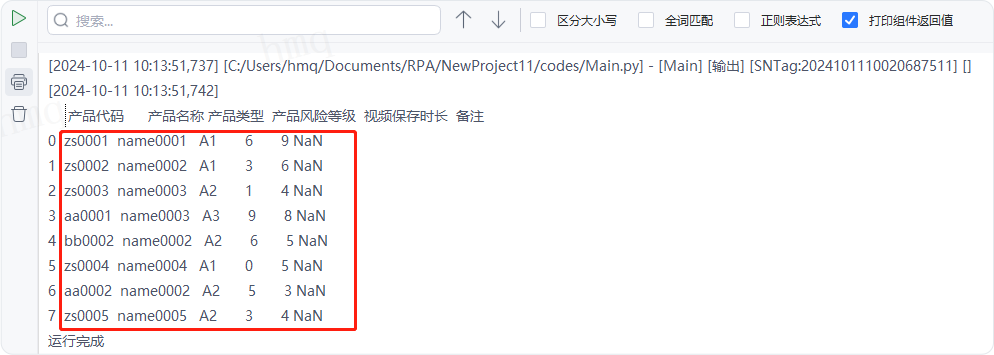
输出结果:运行流程后,系统自动读取csv文件,并输出结果到控制台
情况2:CSV文件是以纯文本形式存储的表格数据,由任意数目的记录组成,记录间以某种换行符分隔开,最常见的就是逗号或制表符。例如以下示例
目标属性''sep''默认为 ',' ---->''delimiter''默认为None---->''delim_whitespace''默认为False---->''header''设置为'infer',即设置数据第一行为表头---->运行流程
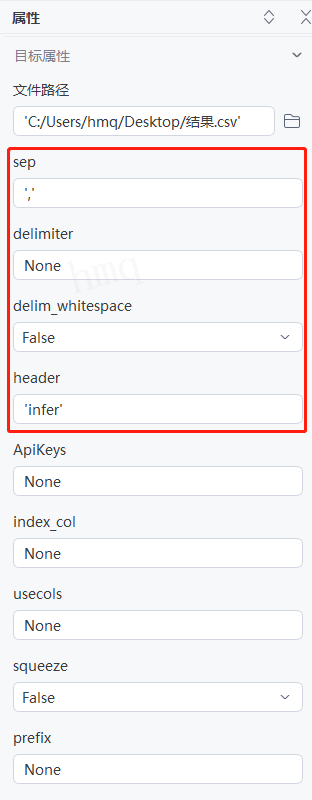
输出结果:运行流程后,系统自动读取csv文件,并输出对应数据到控制台,下图为输出与源文件对比图

情况3:目标属性''header''输入2,即指定行第三行为表头,前两行的数据不读----运行流程
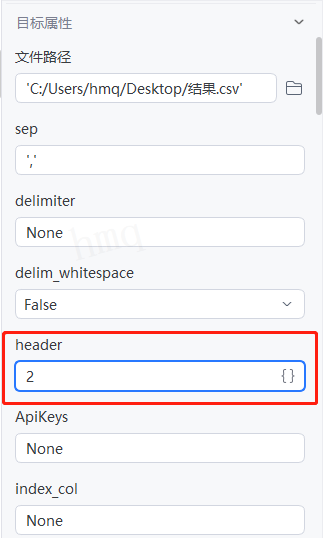
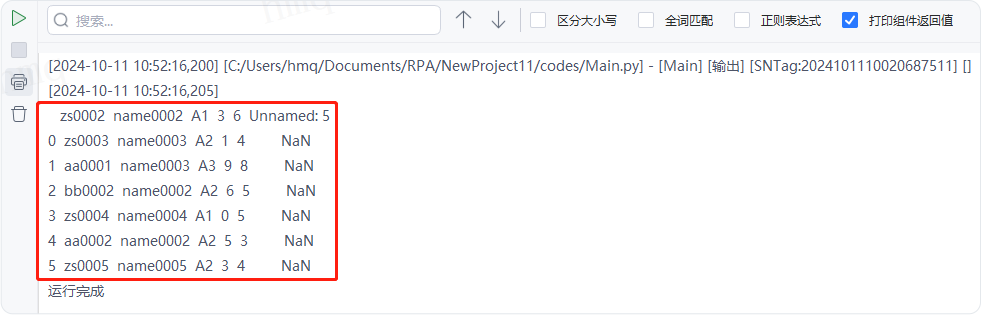
输出结果:运行流程后,系统自动读取csv文件,并输出对应数据到控制台,第三行为表头,前两行的数据没有读取
情况4:目标属性''header''输入整型数字的列表,即指定列表内元素对应的行作为表头,即每一列有多个列名,且介于表头行中间的行数据被忽略不读取---->运行流程
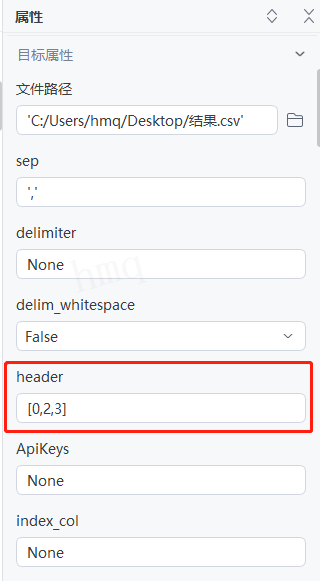
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,且将第一行、第三行、第四行作为表头,第二行数据没有读取。下图为结果与源文件对比图
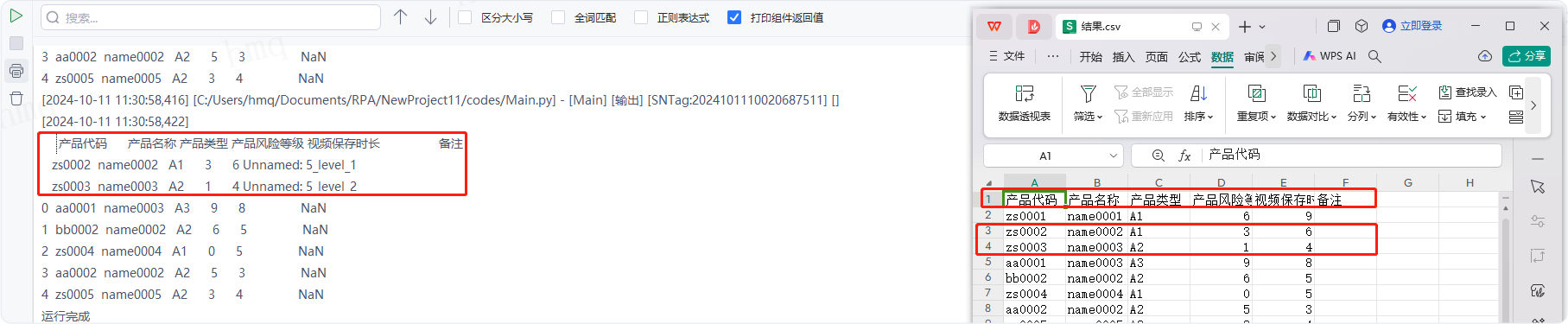
情况5:目标属性''Apikeys''输入类似数组的有序集合[列一、列二、列三、最后一列],即从最后列开始,数据内的元素倒序依次作为对应列的列名---->运行流程
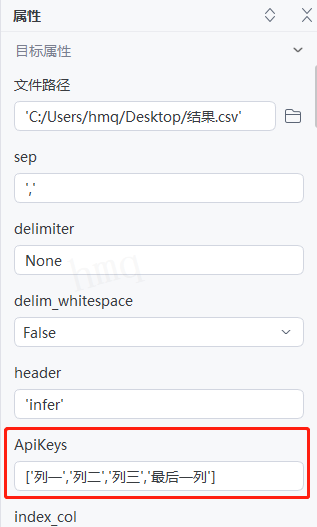
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,对应后四列列名为:列一、列二、列三、最后一列
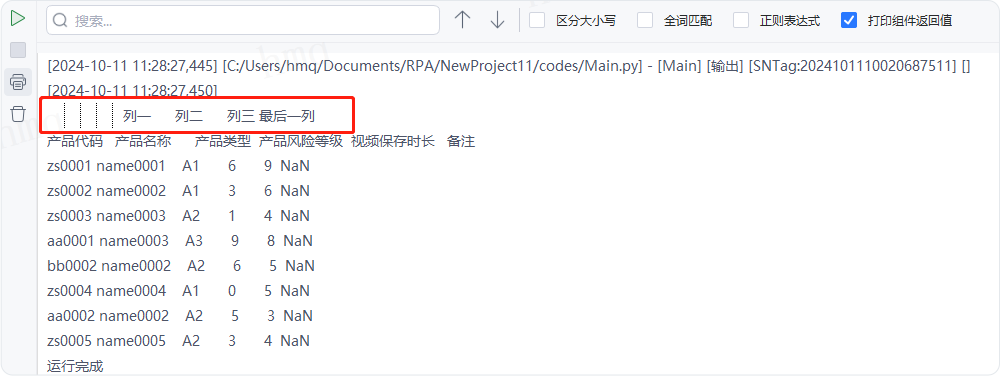
情况6:目标属性''index_col''输入列的整型数字下标或列名的字符串,即指定该列为索引列,例如输入'产品类型'---->运行流程
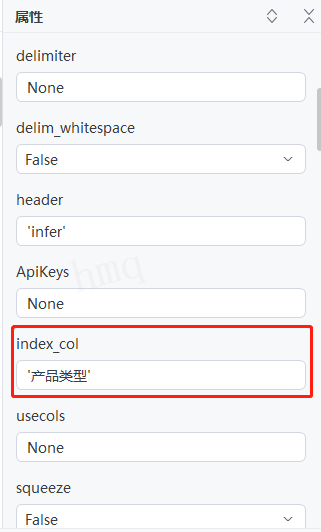
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,且指定''产品类型''为索引列
情况7:目标属性''index_col''输入列名或列下标为元素组成的序列(如列表、元组等),指定序列元素所对应的列作行索引,这样每行便有多个索引
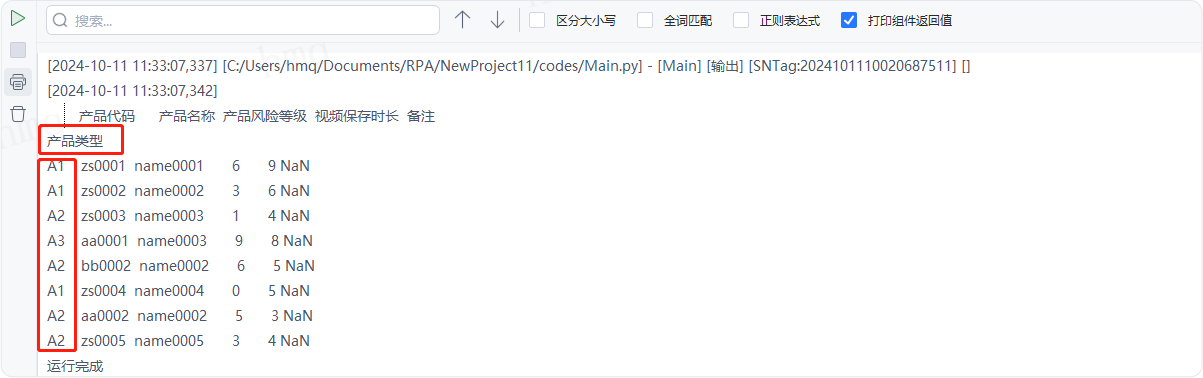
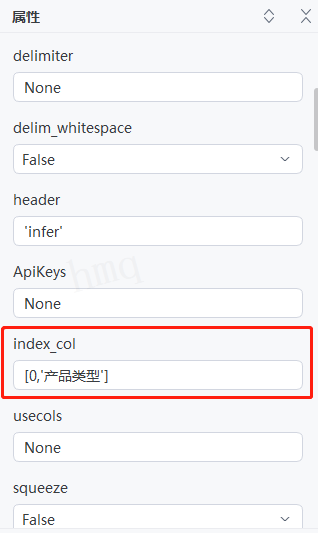
例如,输入[0,'类型'],设置第一列和''产品类型''列为索引---->运行流程
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,且设置第一列和''产品类型''列为索引
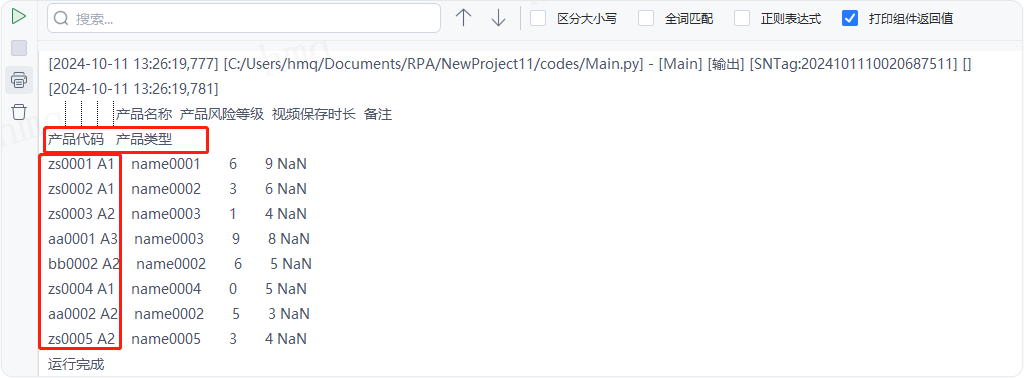
情况8:目标属性''usecols''输入列名或列下标为元素组成的可迭代序列(如列表、元组等),获取序列元素对应表格中的列,例如输入:[0,2,4]---->运行流程
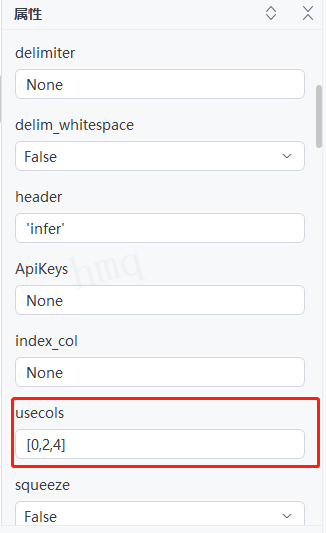
序列内的元素需统一,或均为列名,或均为列下标
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,读取了第一列、第三列、第五列数据
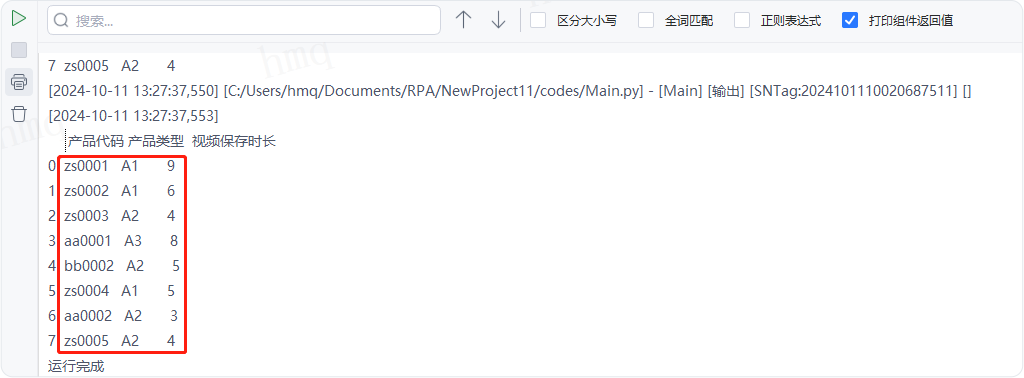
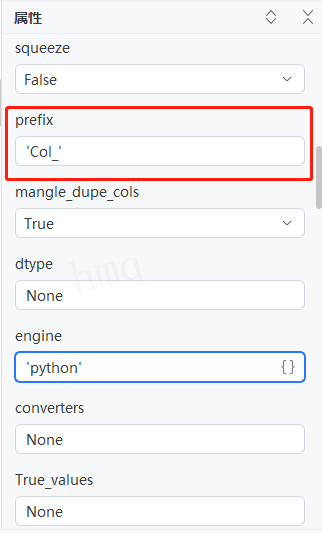
情况9:目标属性''prefix''输入字符串,在列下标前添加前缀作为列名(header=None),例如输入:'Col_' ---->运行流程
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,在列下标前添加前缀'Col_'作为列名
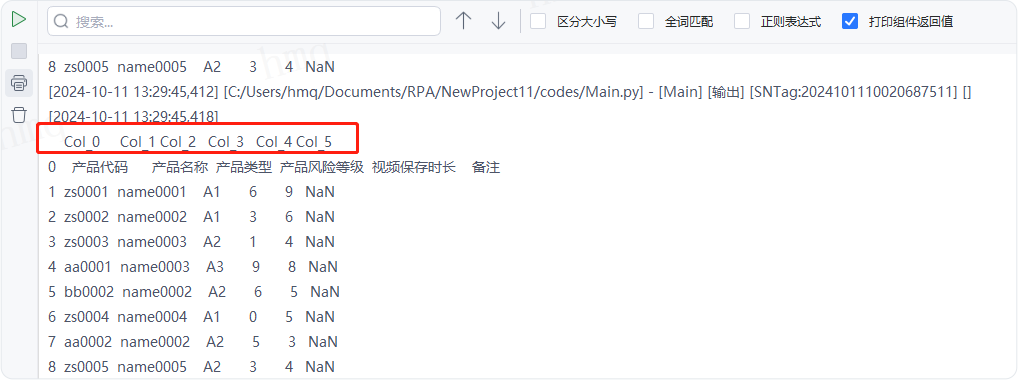
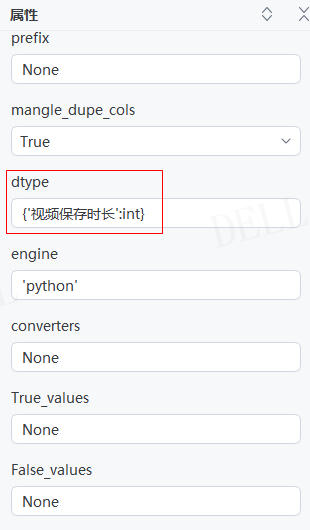
情况10:目标属性''dtype''输入列名为key,数据类型为value的字典,例如输入{'视频保存时长':int},即设置''视频保存时长''列为整型---->运行流程
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,下图为输出结果与源文件数据对比
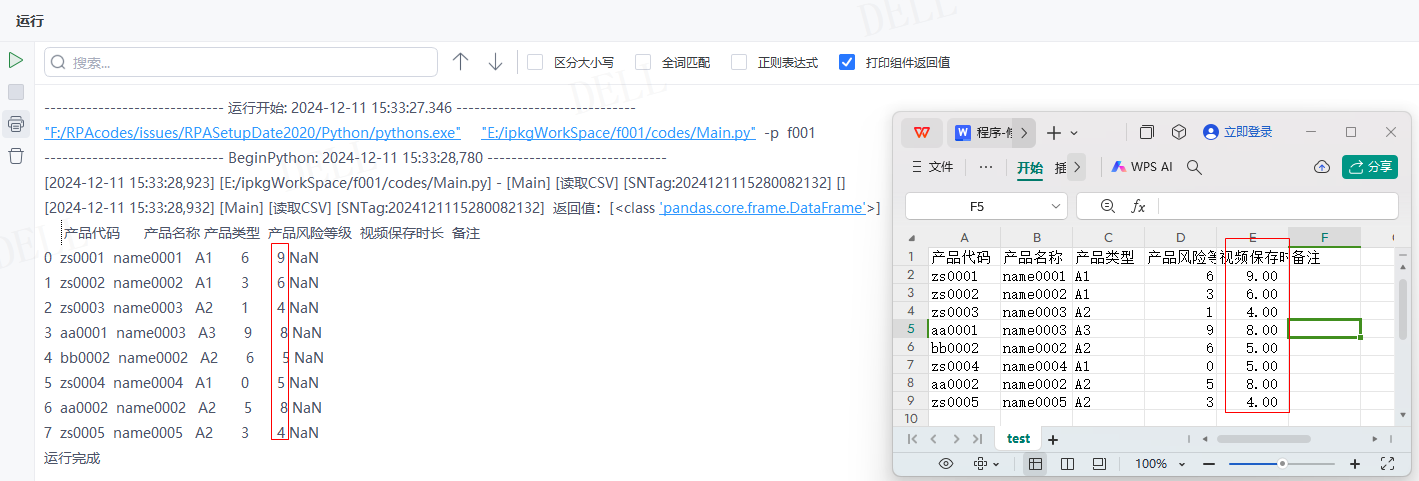
情况11:目标属性''converters''输入{"产品风险等级": lambda x: int(x) + 100},即对''产品风险等级''列的数值加100---->运行流程
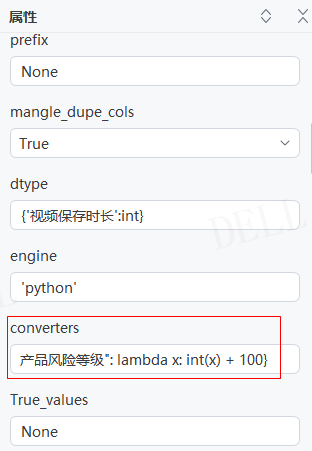
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,且已将''产品风险等级''列的数值加100
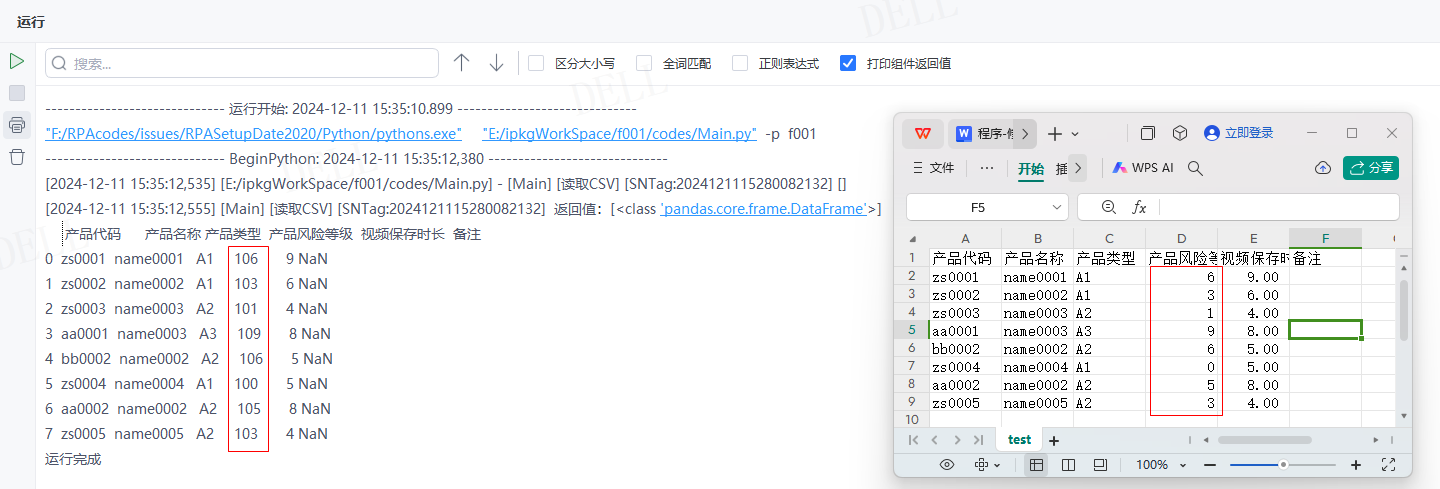
情况12:目标属性''skiprows''输入为2,即从文件起始行开始跳过2行数据---->运行流程
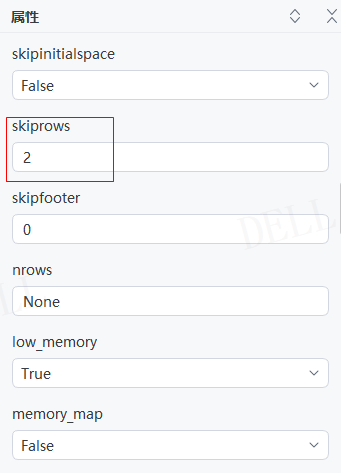
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,下图为结果与源文件数据对比
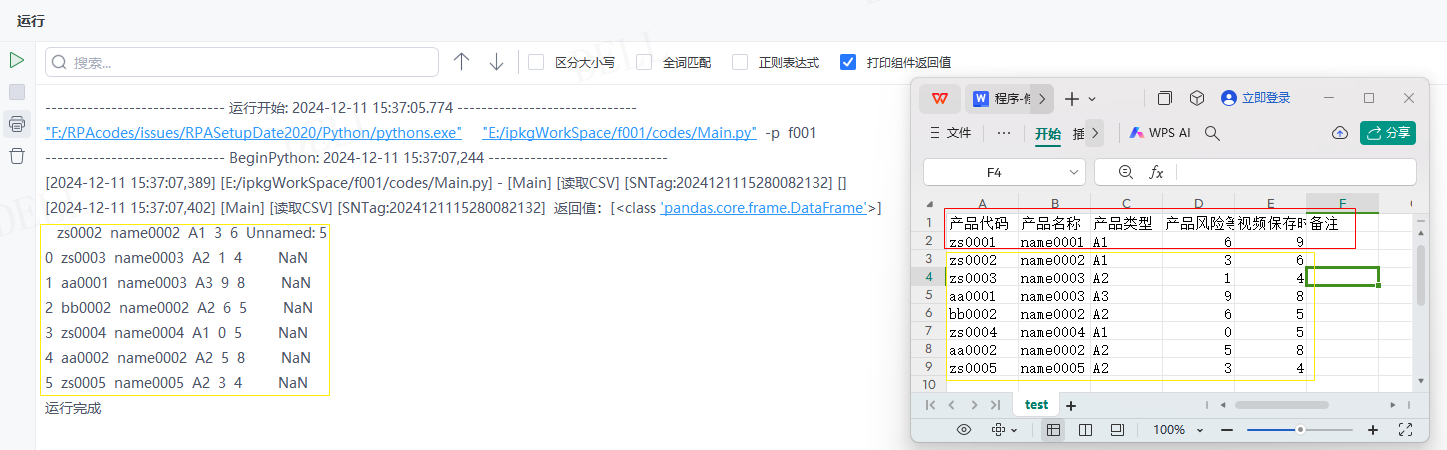
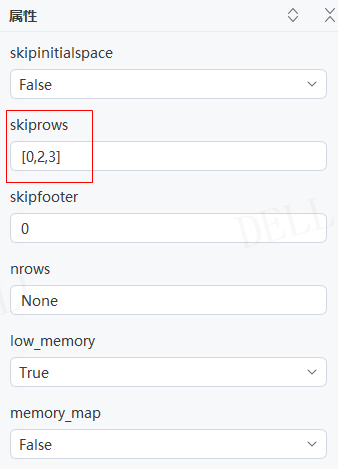
情况13:目标属性''skiprows''输入需要跳过的行数号(文件第一行从0开始)组成的有序序列,如列表、元组;例如输入:[0,2,3]---->运行流程
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,且没有读取第一行,第三行,第四行数据
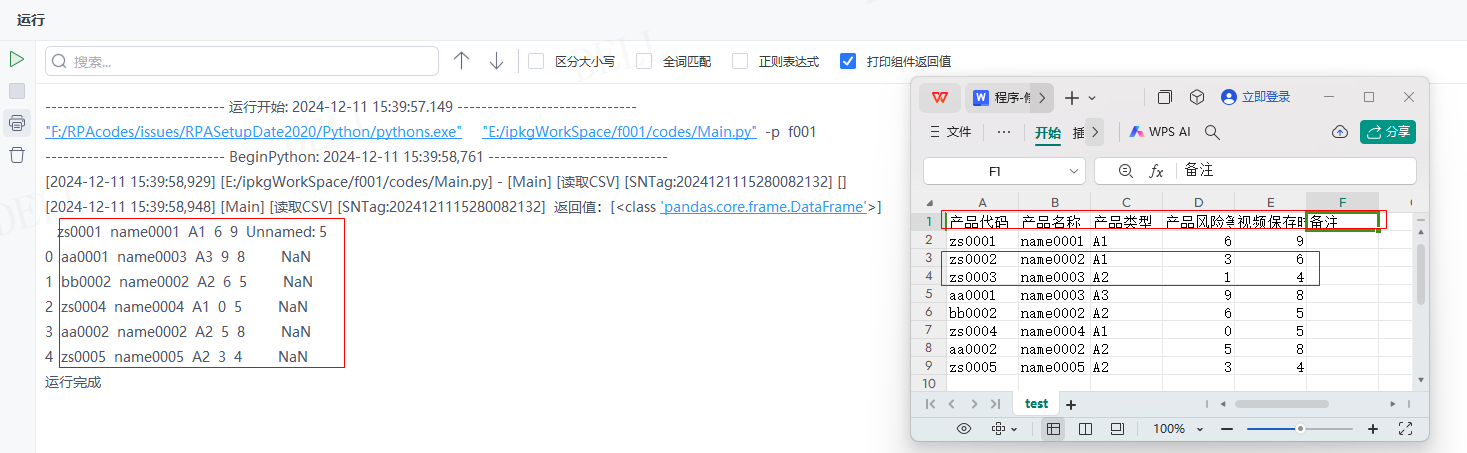
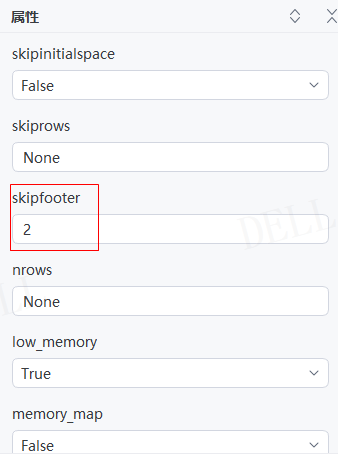
情况14:目标属性''skipfooter''参数输入2,即读取时忽略倒数两行数据---->运行流程
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,且已忽略倒数两行数据
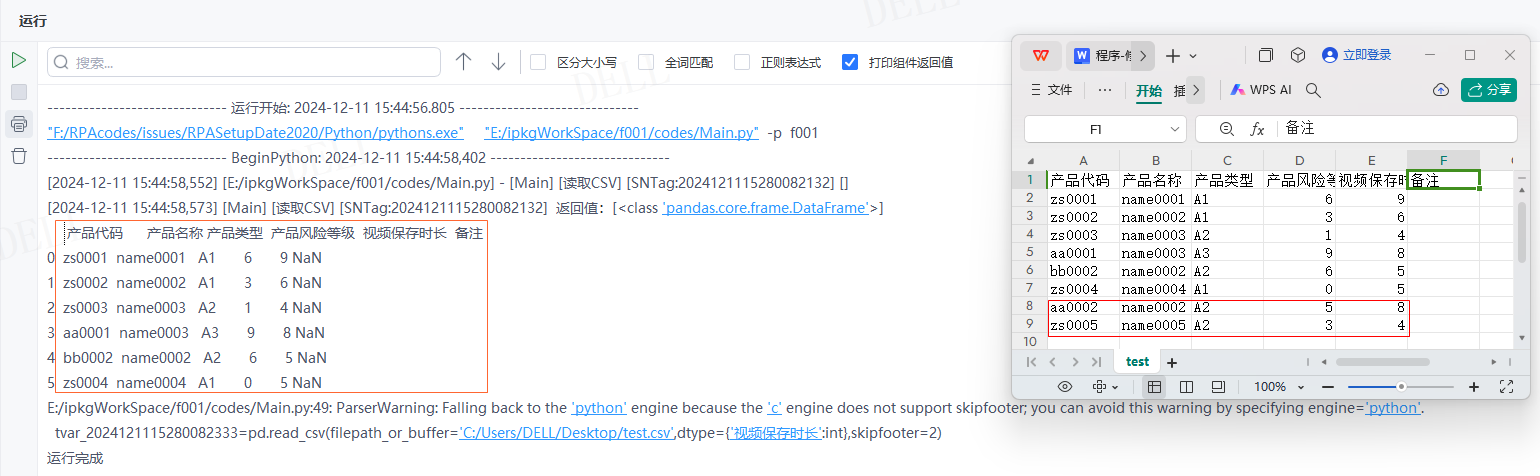
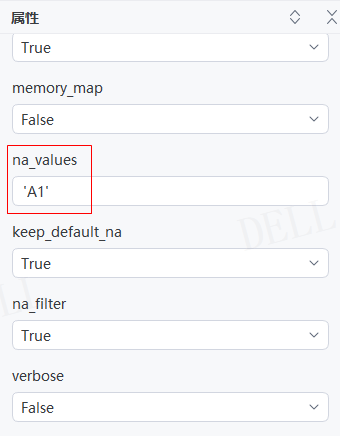
情况15:目标属性''na_values''输入字符串'A1',即将与之相同的数据替换为空值NaN---->运行流程
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,且已将A1替换为NaN
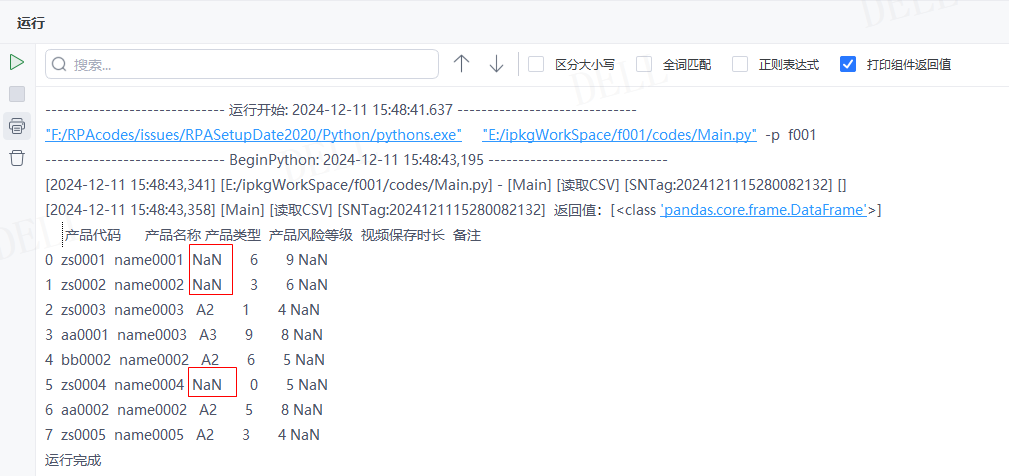
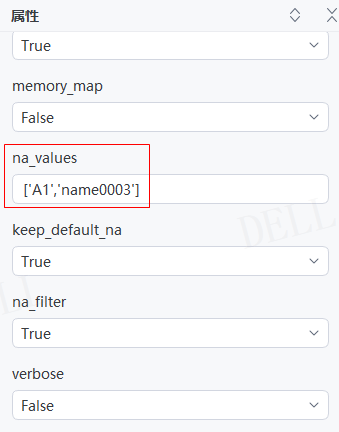
情况16:目标属性''na_values''输入列表元组等序列,将序列内的元素对应的数据都替换为NaN,例如输入:['A1','name0003']---->运行流程
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,且已将A1、name0003都替换成了NaN
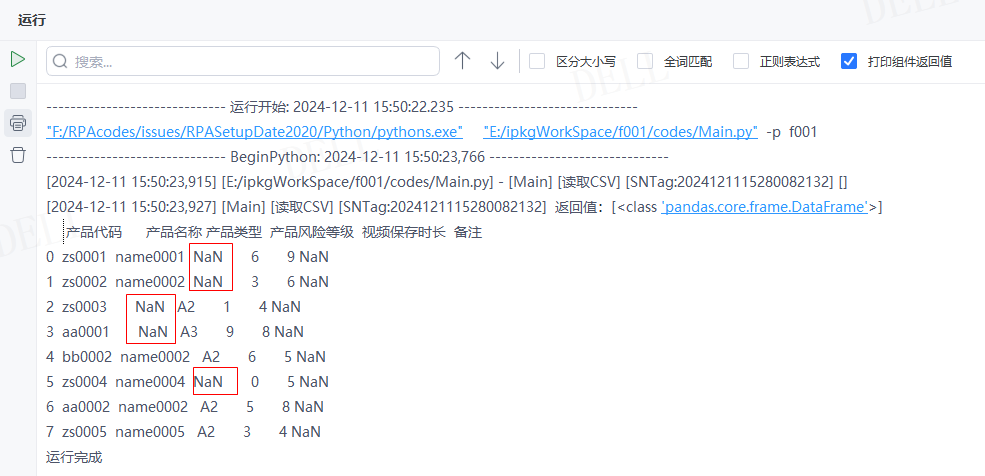
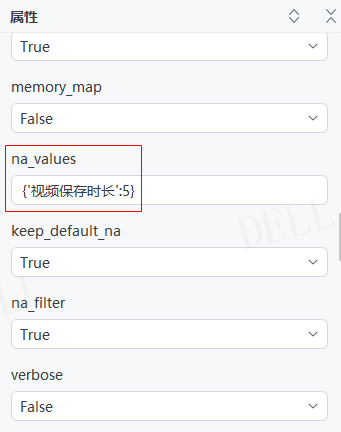
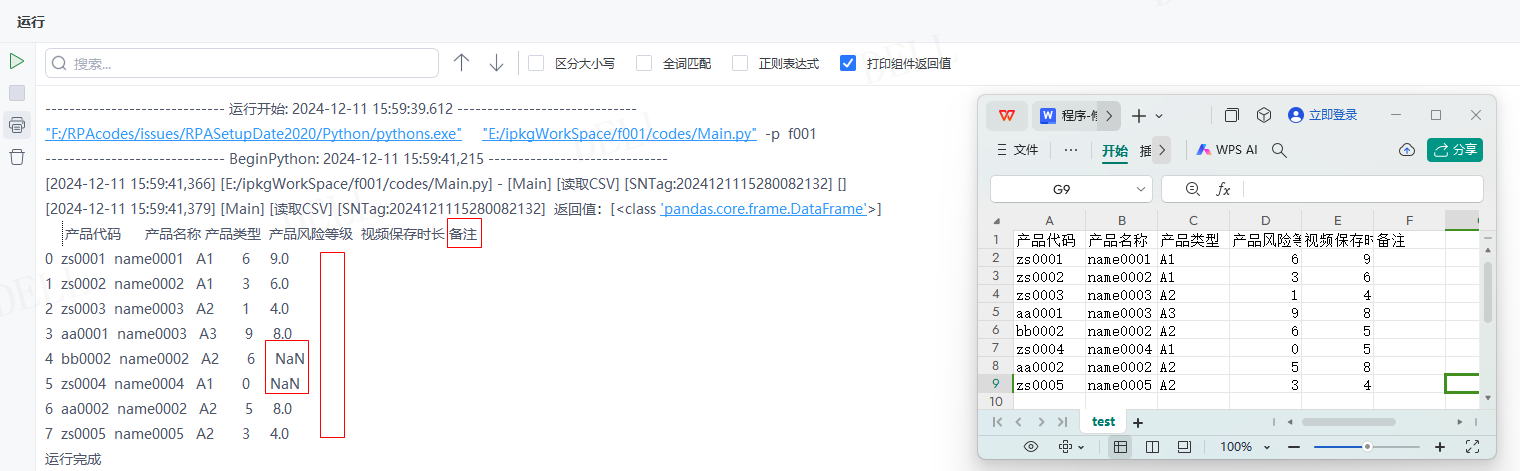
情况17:目标属性''na_values''输入字典{'视频保存时长':5},即将''视频保存时长''列值为5的数据替换为NaN---->运行流程
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,且已将''视频保存时长''列值为5替换成了NaN
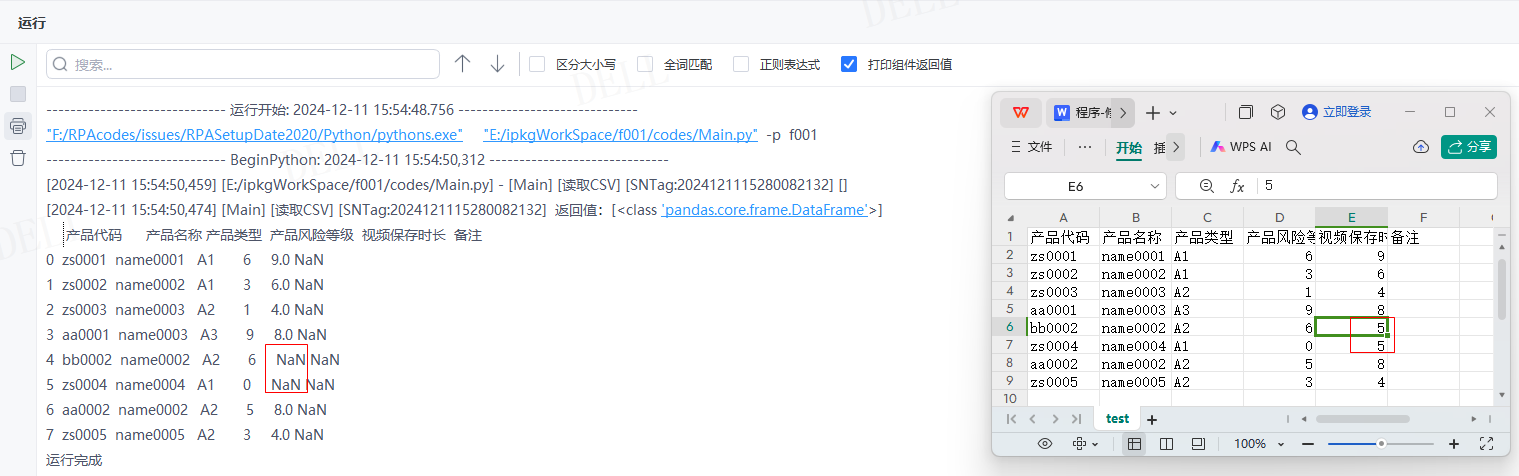
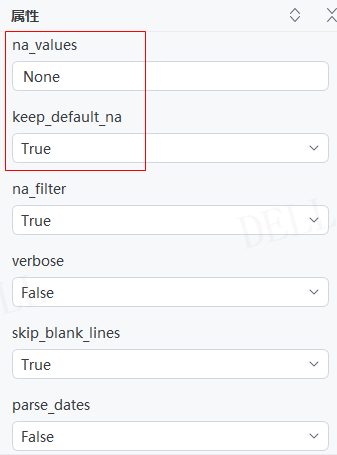
情况18:目标属性''na_values''默认为None---->目标属性''keep_default_na''默认为True,即将表格中的空值解析为NaN---->运行流程
输出结果:运行流程后,系统自动读取csv文件并输出对应数据到控制台,且已将表格中的空值解析为NaN
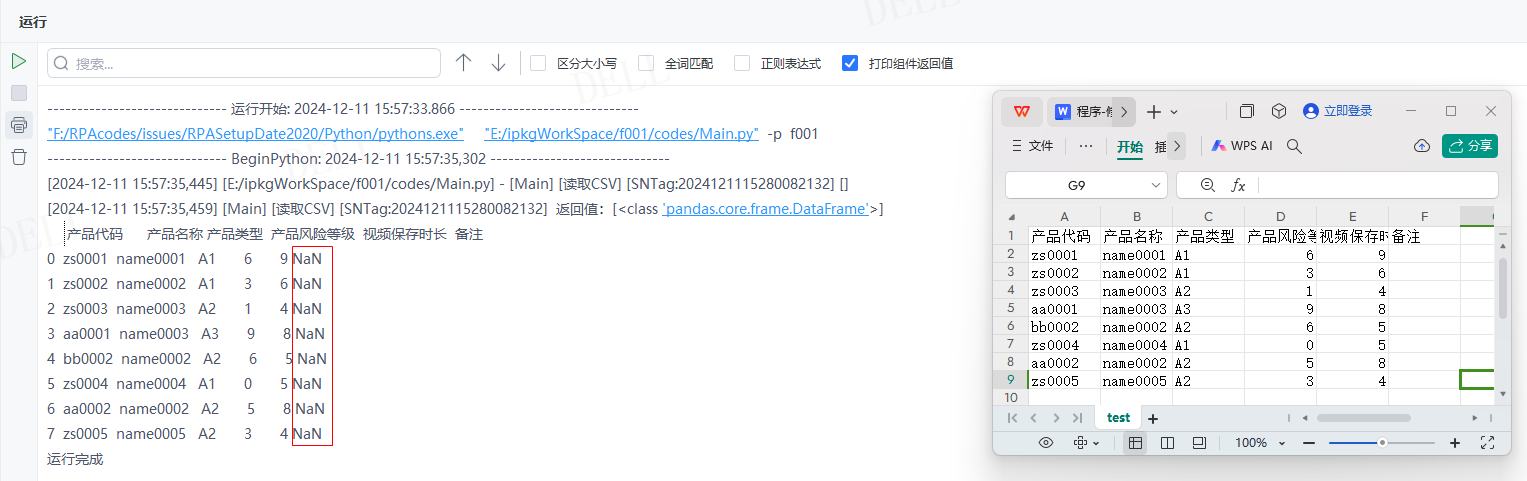
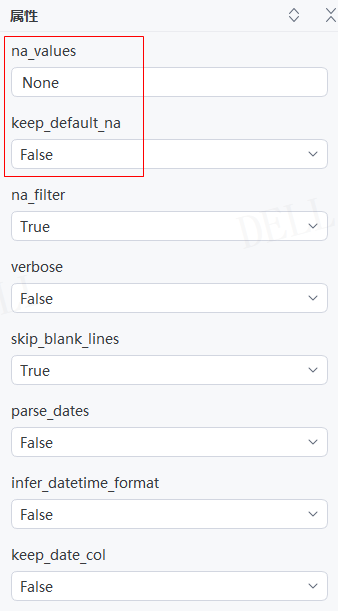
情况19:目标属性''na_values''默认为None---->目标属性''keep_default_na''参数设置为False,即表格中空值保持为空,不解析为NaN---->运行流程
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,且表格中空值保持为空,没有解析为NaN
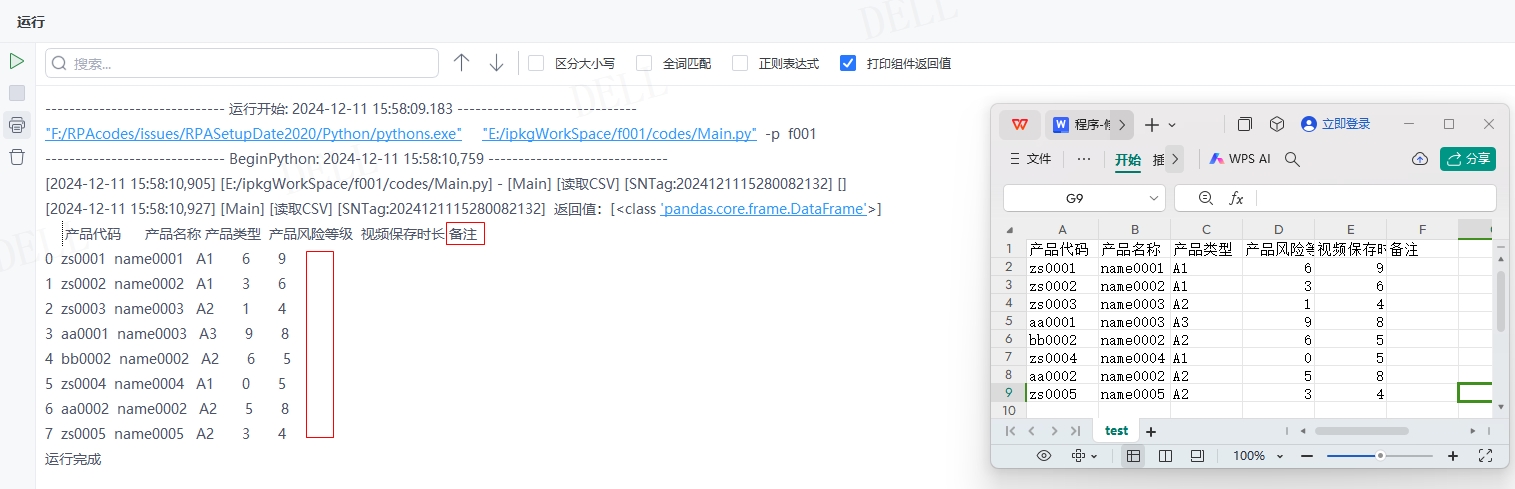
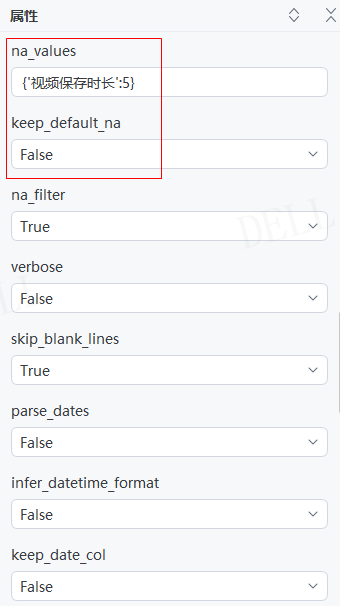
情况20:目标属性''na_values''输入字典{'视频保存时长':5}---->''keep_default_na''参数设置为False,即被替代的空值解析为NaN,原本空值依旧为空---->运行流程
输出结果:运行流程后,读取csv文件并输出对应数据到控制台,且已将'视频保存时长'列值为5替换成了NaN,原本空值依旧为空
如果将''na_filter''属性设置为False ,则将忽略''keep_default_na''和''na_values''属性