

怎么才能解决浏览器元素 XPath 变动导致流程执行失败?
场景
制作流程和流程跑起来后,突然不能点击到某个 Chrome 浏览器按钮了,重新拾取发现 html 页面上按钮的属性发生变化了,比如:html 页面 class 名称发生变化了、html 页面 id 后面带的一串数字变化了,之前还在第 3 层 div 来着。。。
版本
iSRPA 2022.1 版本已验证
实现
1、html 页面元素 id 经常变动的场景, 以一个组件的 html 页面元素属性表为例:"xpath": "//*[@id=\"HBoxLayout72\"]/div[1]/div[10]/div[1]/div[1]/div[1]/span[1]"
改为 contains 包含这个 id 的公共部分(HBoxLayout):"xpath": "//*[contains(@id,'HBoxLayout')]/div[1]/div[10]/div[1]/div[1]/div[1]/span[1]"
或者改为这个 id 以公共部分 starts-with 开头(HBoxLayout):"xpath": "//*[starts-with(@id,'HBoxLayout')]/div[1]/div[10]/div[1]/div[1]/div[1]/span[1]"
需要将属性表其他属性删除,只保留 xpath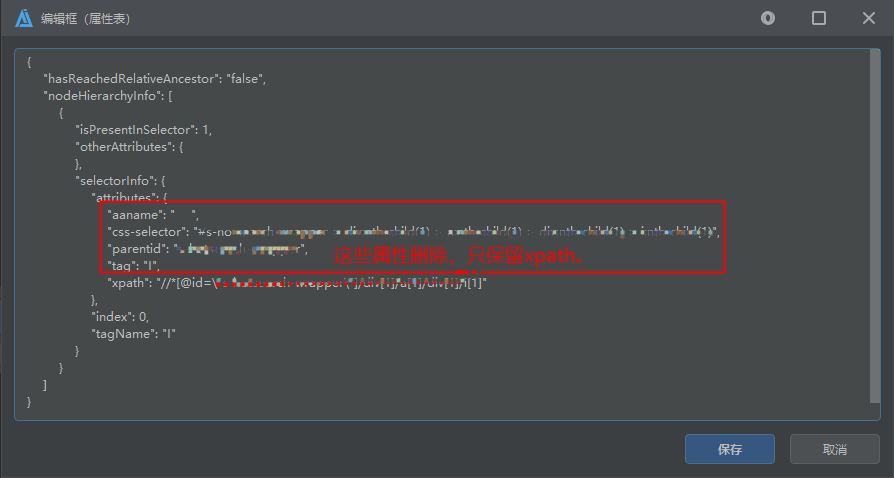
如果 xpath 开头使用星号//*[]不能成功,可以改成该 html 页面元素所在标记,例如//div[]
2、html 页面元素的 class 名称变了,参考第 1 点,处理思路:找以什么开头,以什么结尾,中间包含什么固定名称等;
3、html 页面标签层级发生变动,原本在第 3 位,现在跑到第 4 位,可以采用倒数第几个,或者在哪个确定的元素之后还是之前等思路;
注意
这样就能彻底解决吗?答案是 NO,应该要看原页面的开发者“心情”(开个玩笑),由于页面开发的动态性,会需要使用随机或者一定机制的 id 命名,以及 html 页面结构的调整,这是不可避免的。
当出现 xpath 变动时,我们只好修改,只要不是改动很大都是可以用此方法解决的。(比如整个页面元素的命名规则发生变化,页面整体升级改版等)
其他
如果需要知道原理的,这需要一点点的 html 页面 xpath 定位的知识,请看这里:
《 https://developer.mozilla.org/en-US/docs/Web/XPath/Functions 》
《 https://www.cnblogs.com/unknows/p/7684331.html 》

点赞,就是要摸索变化规律,按规律写 xpath,实际上,程序生成的 DOM,肯定有规律,只是有时规律比较复杂
其实我比较喜欢 CSS-Selecotor