

关于银行外汇平台登录包含数字验证码不用 OCR 组件的实现过程
本文主要是个人在项目实施过程中遇到的问题,以及发掘的解决办法,仅供参考
在银行实施过程中,电脑是不可以连外网的,而登陆外汇管理平台有一个 4 位数字验证码的过程,而通过学习我们知道要通过验证码组件,输入 APIkey 和 Scretkey 以及对应的验证码接口数字即可,而在没有没有外网的情况下,这种操作是实现不了的。
通过查询资料用的是导入 python 的包来实现验证码的识别,具体实现的流程图如下: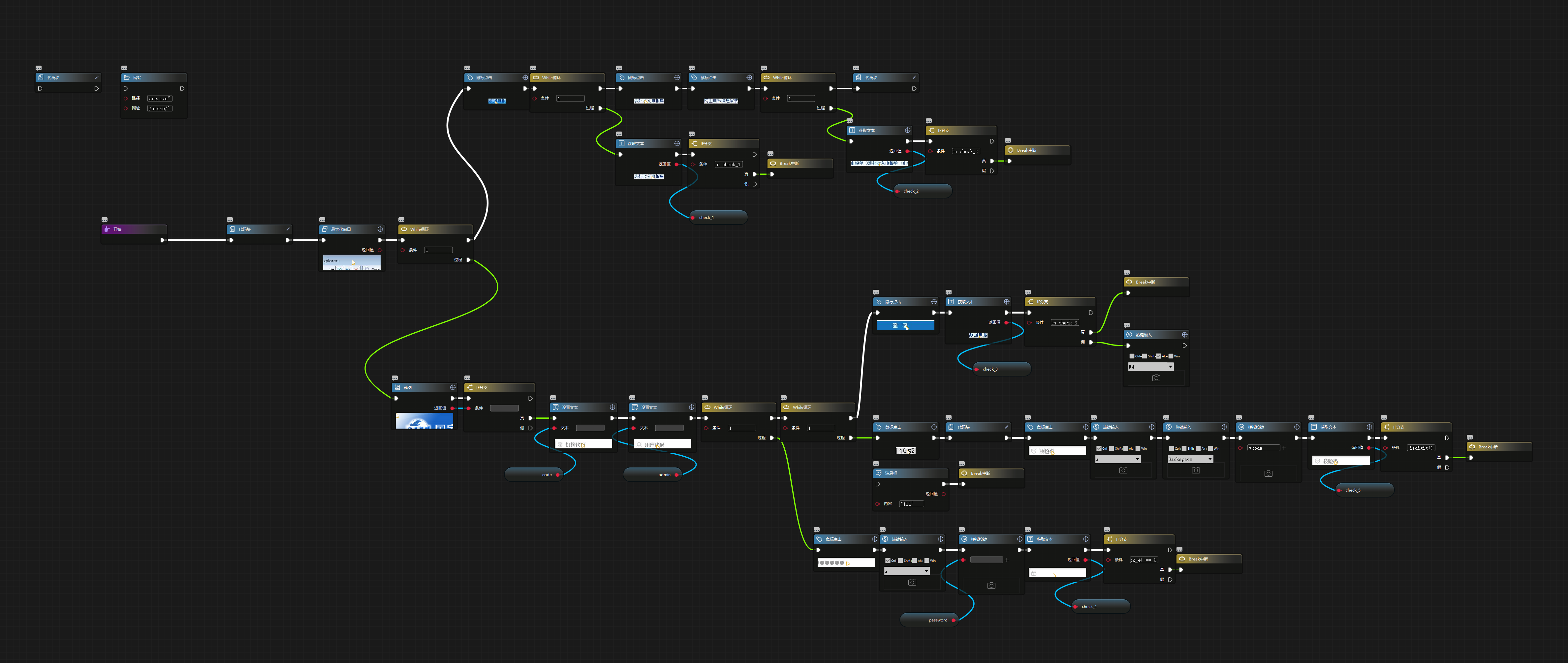
而实现验证码识别的关键部分就在第二个 while 后连接的代码块,代码块内容如下:
import os
import pytesseract
from PIL import Image
from PIL import ImageGrab
import time
vcode = " "
time.sleep(1)
s = os.path.exists(r"D:\ 浦发对外 \ocr_picture.jpg")
if s:
os.remove(r"D:\ 浦发对外 \ocr_picture.jpg")
bbox = (1075,453,1135,473)
#bbox = (994,464,1054,485)
im = ImageGrab.grab(bbox)
im.save(r’D:\ 浦发对外 \ocr_picture.jpg’)
time.sleep(1)
#resseract_cmd = ‘D:/iS-RPA/plugin/Com.Isearch.Func.Python/Tools/Tesseract-OCR/tesseract.exe’
open image
image = Image.open(r’D:\ 浦发对外 \ocr_picture.jpg’)
vcode = pytesseract.image_to_string(image)
vcode = vcode.replace("“,”")
print(vcode)
以上如有不明之处可在下方回帖,仅供参考。

请问这个路径是截图组件截图的图片吗?
r’D:\ 浦发对外 \ocr_picture.jpg’
就是单次识别的成功率比较低,但是多次的话成功率就可以,所以就多弄循环,就肯定能过,就是登录的时候要费点时间
就是识别率没那么准确,但是是可以用的,就需要做好循环这块,大概一般识别 10 次左右就能通过,运气好的时候三四次就可以
识别效果怎么样
666
pytesseract 通用库只能识别个数字验证码,而且不能太乱七八糟的。
感觉很厉害的样子
离线 OCR 识别我在银行也遇到过,方法差不多不过识别率很低,基本为零。不知道你那识别率怎么样?有相关经验可以分享一下,谢谢