

用获取到的文本,命名文件时,出现的怪问题
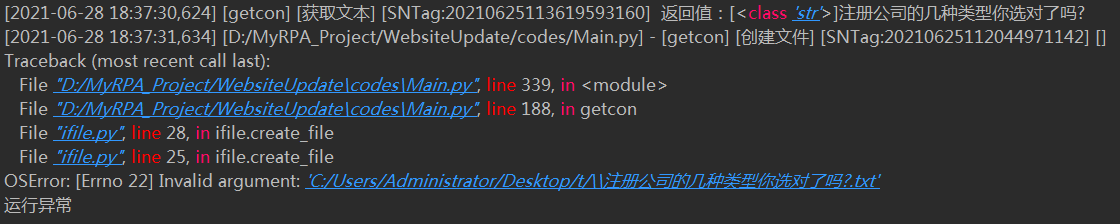
明明获取到的文本就是普通的 str:“注册公司的几种类型你选对了吗?”
可是写入 txt 的标题时,怎么就多出了两个“\”,导致异常?
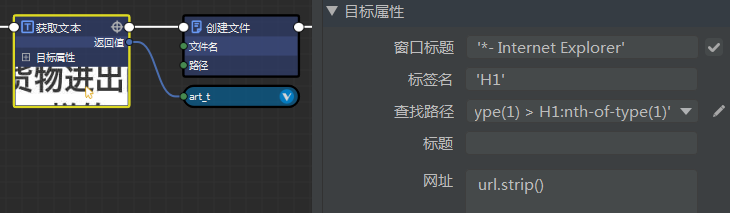
获取文本感觉上是没什么问题的,就是抓取页面中的 H1,获得一个标题。
再用这个标题用做文件名。

请问,我这是哪里出错了,是不是还要对 art_t再用正则过滤一下?应该怎么写呢?
问题处理
最核心的问题是,新建文件不能使用的特殊字符:

文件名,是不能出现这些特殊字符的,因此要过滤。如果没猜错的话,这些都是半角的。
# 在python环境里测试一下
import re
string = '/我是<一个文件>的*文|件|名?'
rstr = r'[\/\\\:\*\?\"\<\>\|]' # 每个字符都给他转义一下,其中反斜杠比较特殊一点
sub_str = re.sub(rstr, '', string)
print(sub_str)
# 我是一个文件的文件名
反思
报出异常是这个样子的:
‘Invalid argument’ 字面意思是无效参数。 在文件名处还多了两个 ‘反斜杠’,很容易被误导。你能第一时间想到是半角’?’出了问题么?
可是,你们看:

这里也有个问号,怎么就能用做文件名了呢? 因为这个问号是 ‘全角’字符。

是,反斜杠在哪都是特殊字符。
\\ 是 \ 的转译字符,应该是防止转译给你自自动生成的?你的 art_t 里面传了什么嘛
我在这个回答了写的双斜杠 \ 居然给我转译留下了一根
对,你真聪明,我刚才也发现了,是我没有过滤特殊字符,这里出问题的地方,就是有个“?”。 但是不明白的是, 为什么会出现‘\’这样的异常。
文件名是不能出现有些字符的
路径是正常的,生成的大部分文件都可以,只有个别文件异常。 这里的 ‘t’ 是文件夹的名字,不存在 ’/t’的问题。
你这有个 /t 是啥,先确认路径值是否正常
这个问题很困扰, “\” 这里的双斜杠是怎么出来的?