

一分钟一个 Pandas 小技巧 (一)
在逛 Kaggle 的时候发现了一篇不错的 Pandas 技巧,我将挑选一些有用的并外加一些自己的想法分享给大家。
本系列虽基础但带仍有一些奇怪操作,粗略扫一遍,您或将发现一些您需要的技巧。
原网址:https://www.kaggle.com/python10pm/pandas-100-tricks
纸上得来终觉浅,绝知此事要躬行,所谓的熟练使用 Pandas 是建立在您大致了解每个函数功能上,希望本系列能给您带来些许收获。
创建测试数据
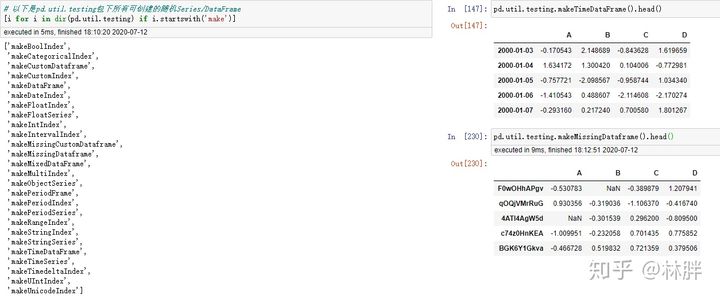
Pandas 自带的函数,避免了自己手写测试数据的痛苦。
索引设置
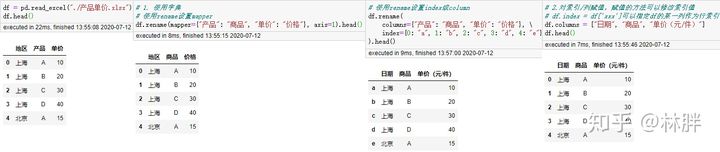
重命名索引
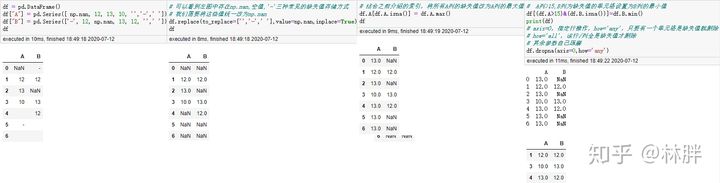
使用 rename()可以对索引 / 列进行重命名,使用赋值的方法必须写出所有的列名,所以推荐 rename()。
图中出现的 axis=1 是指列方向上进行操作,axis=0 是行。这个很好记忆,只要想着 1-> 竖的 -> 列,那另一个 0 自然就是行了。
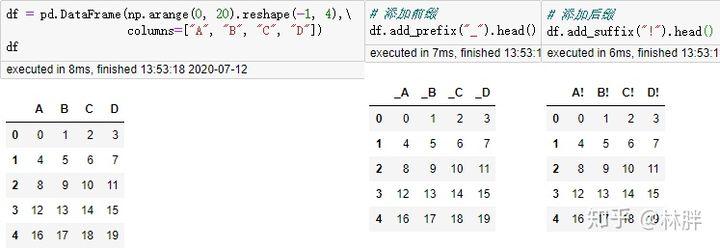
列索引添加前后缀
这个功能比较少用。
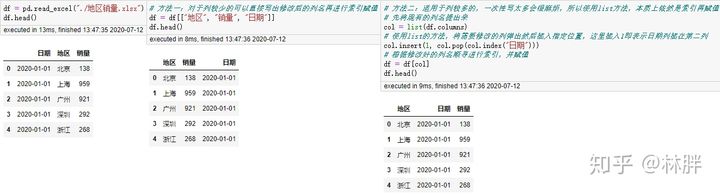
索引位置修改
修改列的位置其实就是通过列名进行索引,然后将查询返回的值赋值给原来的 df 就完成了列位置修改。
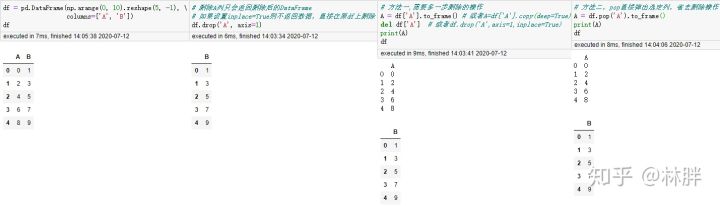
删除列
删除列,能少一行代码是一行。drop,del,pop 任你选。
巧妙使用 F-String 创建列
"".format() 也是不错的选择。
日期时间索引
日期索引可以玩出很多花式索引。
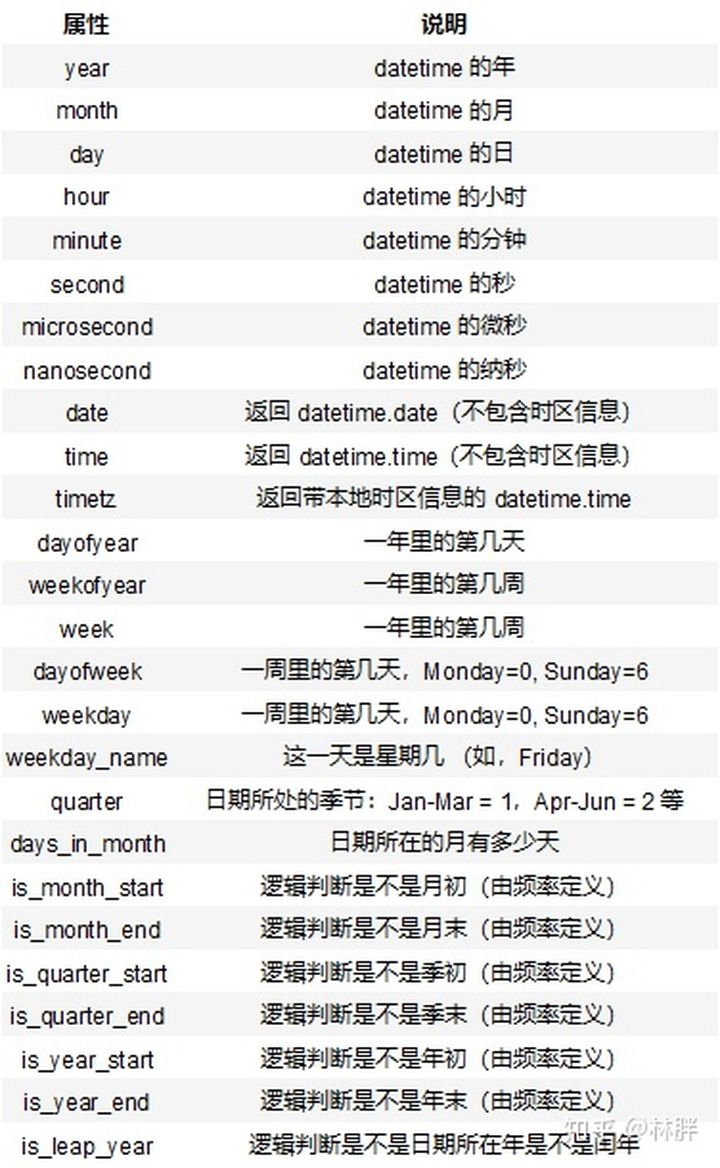
属性说明
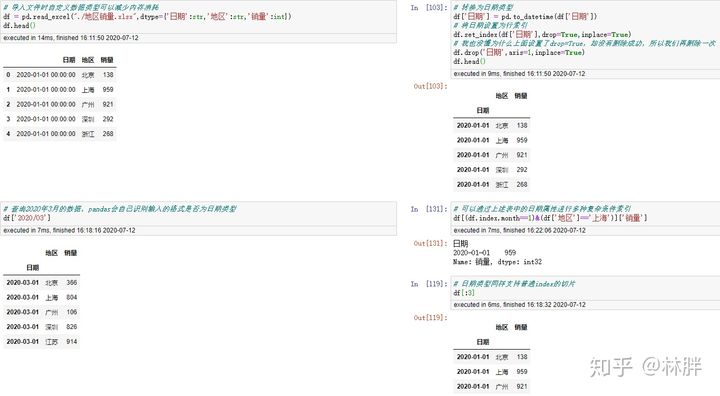
有时候,我们拿到的数据不一定是一列时间数据,而是分开的,我们就可以做如下操作,合并多列为 DatetimeIndex。
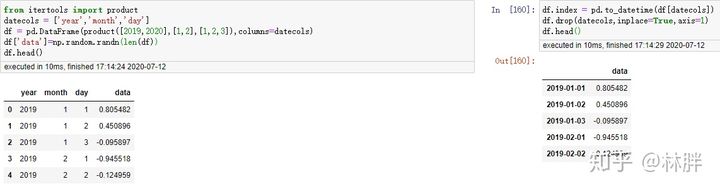
索引查询
单标签索引

切片
df.iloc[x1:x2:x3,y1:y2:y3]指的是搜索 [x1,x2) 行,间隔 x3 行(x3 默认为 1),搜索 [y1,y2) 列,间隔 y3 列(y3 默认为 1)。

loc/iloc/ix
loc,iloc,ix 都是用来索引的,只是使用方式略有不同。
loc,iloc,ix 的区别:
- loc 是根据行列标签来进行索引
- iloc 是根据位置来查询的,即行号列号
- ix 是混合查询,即可以通过行列号也可以通过行列标签索引,但是要注意,行索引必须是行标签而不能是行号,列索引可以是列标签也可以是列号
我个人更喜欢用 ix,虽然官方文档有写从 Pandas 0.20.0 起,这个方法将被弃用,但我用的版本是 0.25.3,这个方法却仍然适用,只是会报错误警告。 官方推荐使用更为严谨的索引方式,即标签索引用 loc,定位索引用 iloc

at/iat
[] 索引会消耗更多的资源来判断你需要的是什么,如果你只想查询某一个值,可以直接用 at/iat,使用方式类似于 loc/iloc。
at/iat 只能使用标签 / 位置作为参数,不能使用切片 ":"。
实际测试下来同样取单个值 at/iat 和 loc/iloc 仅仅相差 1ms(仿佛在逗我)。
所以,还是用 loc/iloc/ix 吧,记太多麻烦。
布尔索引(复杂索引)
Pandas 的判断符号:
- & 与,两者同时满足
- | 或,两者满足其一即可
- ~ 非,满足条件的相反情况
- 切记’==‘判断是否相等,’=’是赋值
使用多个条件进行过滤时,每个条件都需要用圆括号括起来
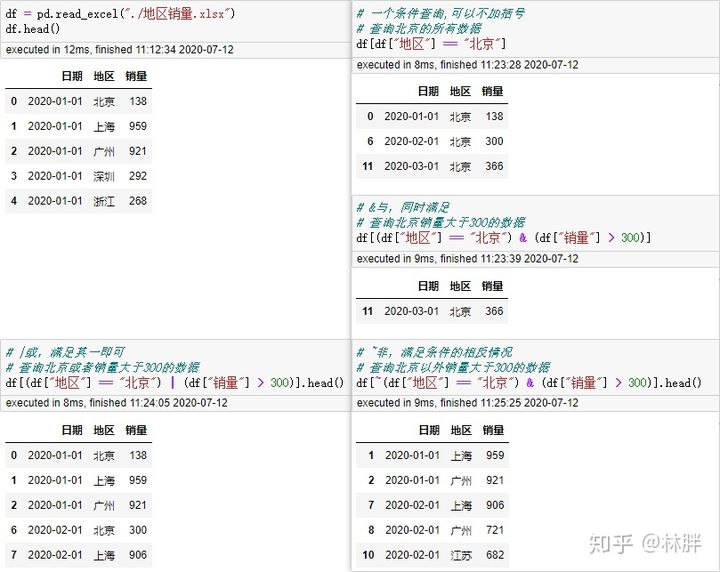
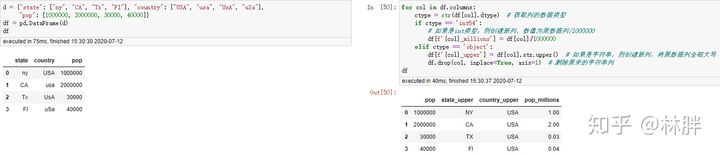
如果过滤条件过多我们可以将代码进行修改。 例如现在我要查询 2020 年 1 月份上海的销量。

上述方法适用于过滤条件很多很多的时候,不然,没啥必要。
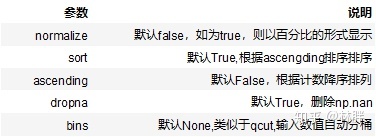
快速计算离散值百分比
value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
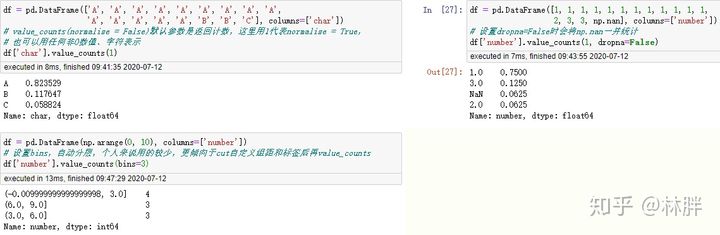
常见统计函数
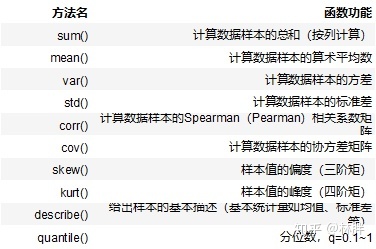
统计函数返回的是一个值,并不是列。
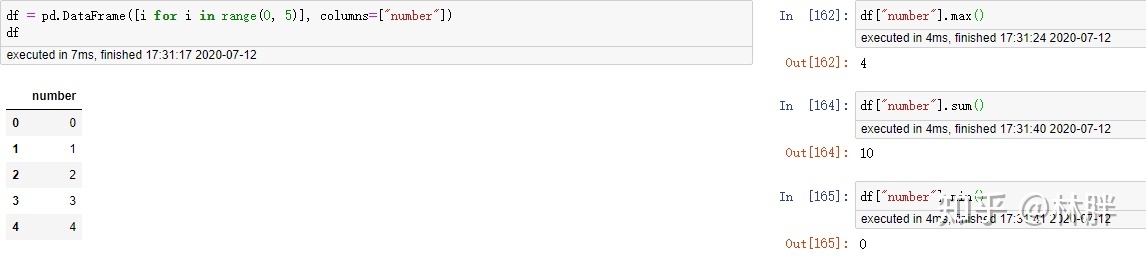
缺失值处理
处理缺失值的方法为:删除、填补、不处理。
更多的情况下我们根据缺失数值列的数据类型来判断处理方式:
- 缺失数据为连续性数据时,常采用均值填补
- 缺失数据为离散性数据时,常采用众数填补
- 机器学习,通过其他数据来拟合填补缺失值
判断空值的函数有 isin(),isna(),isnull()(isnull() 其实是 isna() 的别称)
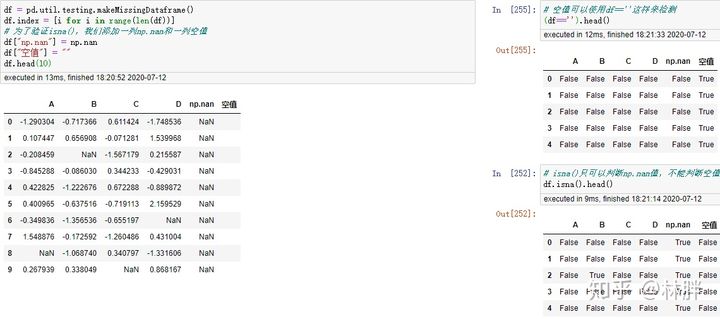
判断两列是否相等。
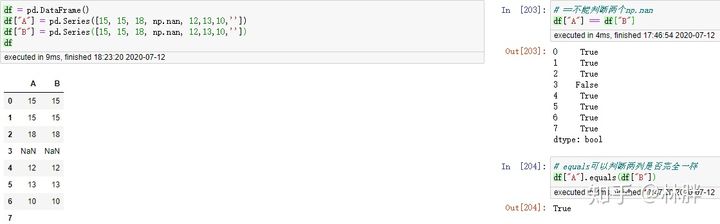
缺失值填补。
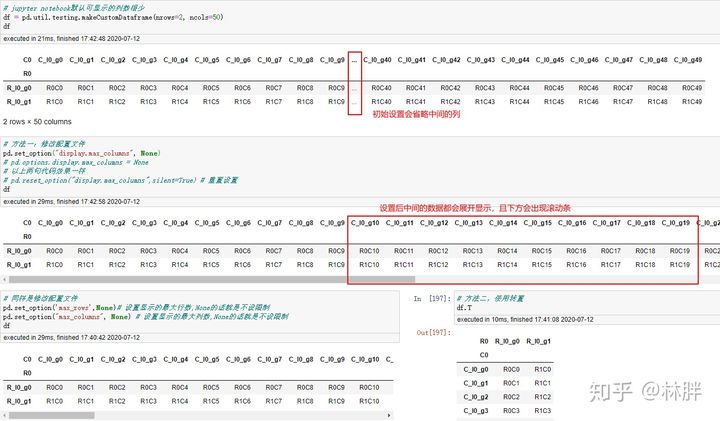
显示维度过多的数据
jupyter 默认设置显示行数列数太少,当维度太多时,常常会出现…省略,所以下面给出两种方式。
- 修改配置文件
- 使用转置

不错!好帖
不错不错,就是放大有点模糊看得不是很清楚 😉
收藏了
很棒,收藏下来慢慢学习。
好帖,收藏了 👍
给力!感谢