

高手过招第 4 期——根据文字点击链接
一、题目
根据文字点击百度首页导航栏, 例如传入“学术”,流程便点击导航栏中的学术。
网址:https://www.baidu.com/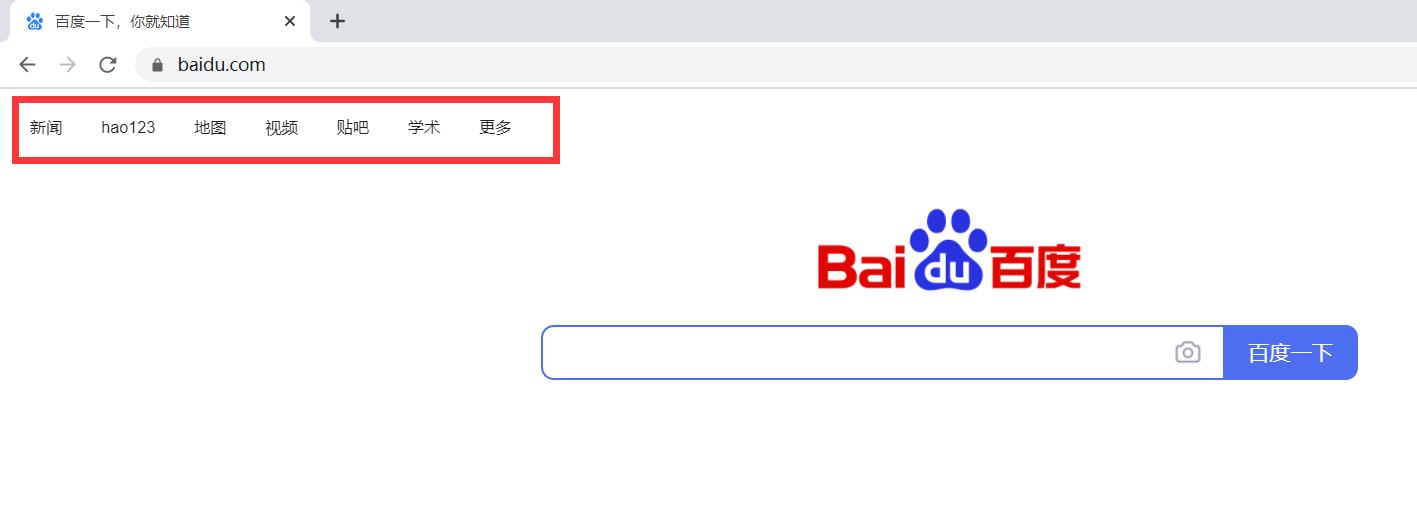
二、Chrome 拾取与 IE 拾取的区别
- IE 拾取是根据 css selector 对目标网页中的元素进行匹配
- Google 拾取是根据键值对对目标网页中的元素进行匹配
三、IE 浏览器解题
1. 找规律
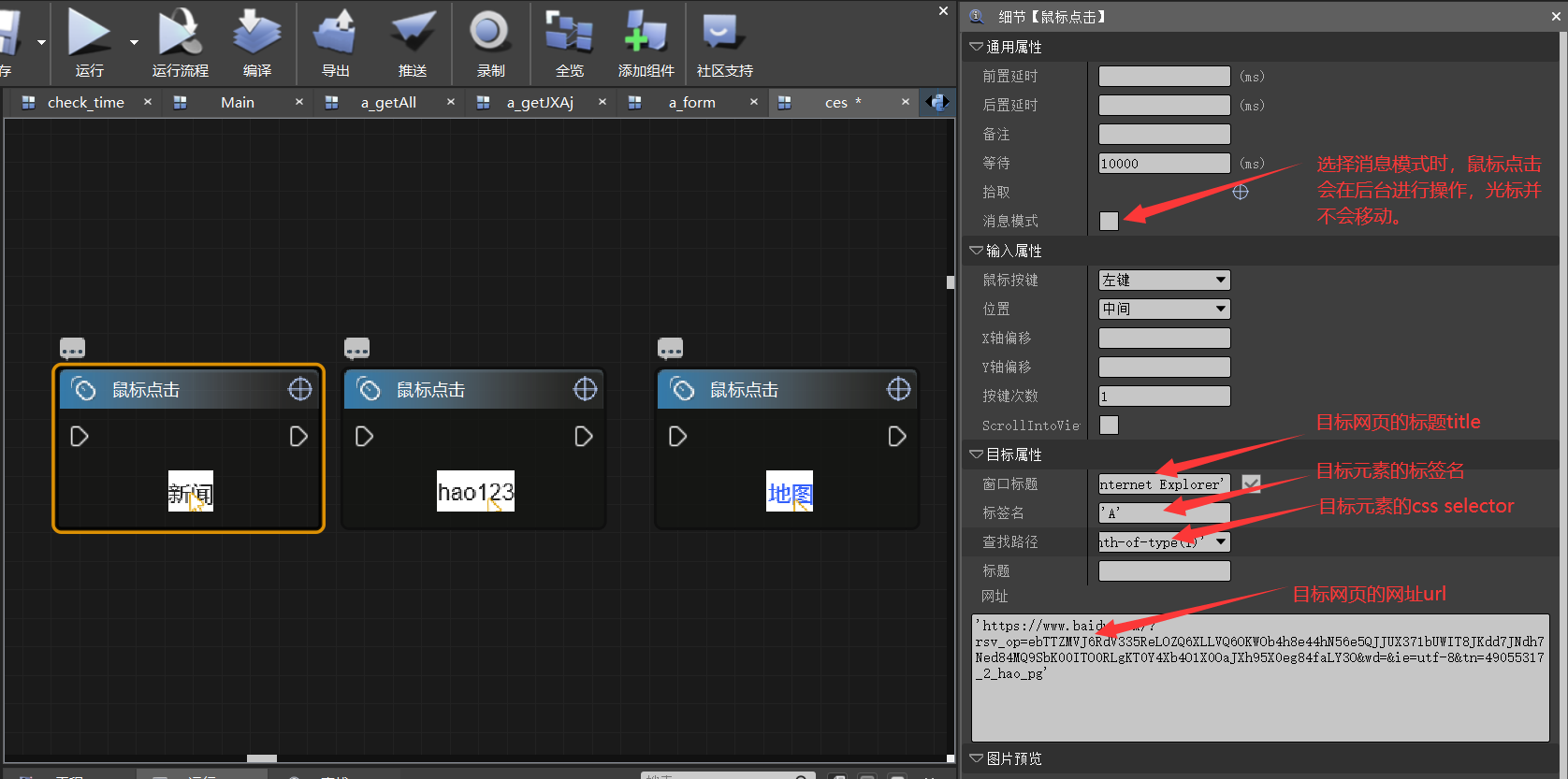
我们知道了 IE 拾取是根据查找路径 (css-selector) 对网页元素进行匹配。
先拾取导航栏前两个链接 (新闻,hao123),拾取后我们对查找路径的值进行找规律,
新闻 :‘#s-top-left > A:nth-of-type(1)’
hao123:‘#s-top-left > A:nth-of-type(2)’
由此我们得出可根据’#s-top-left > A:nth-of-type(下标)’对元素进行匹配。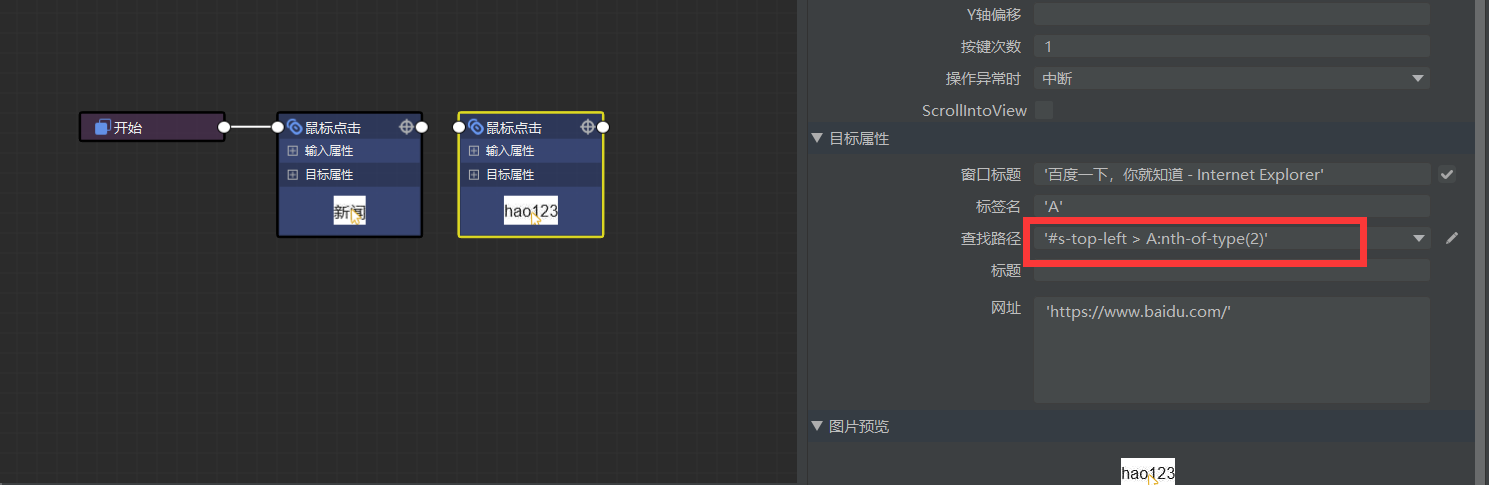
2. 设计流程
pv_text 为传入的参数。
lv_index 为下标,初始值为 0。
lv_url 均为查找路径。
While 中的条件为 True,获取文本与鼠标点击的查找路径均为 lv_url。
循环内首先执行代码块,代码块对 lv_index 自增,并对 lv_url 进行赋值。
当获取文本的值 lv_gettext==pv_text 时,进行鼠标点击操作,跳出循环,否则开始下一次循环。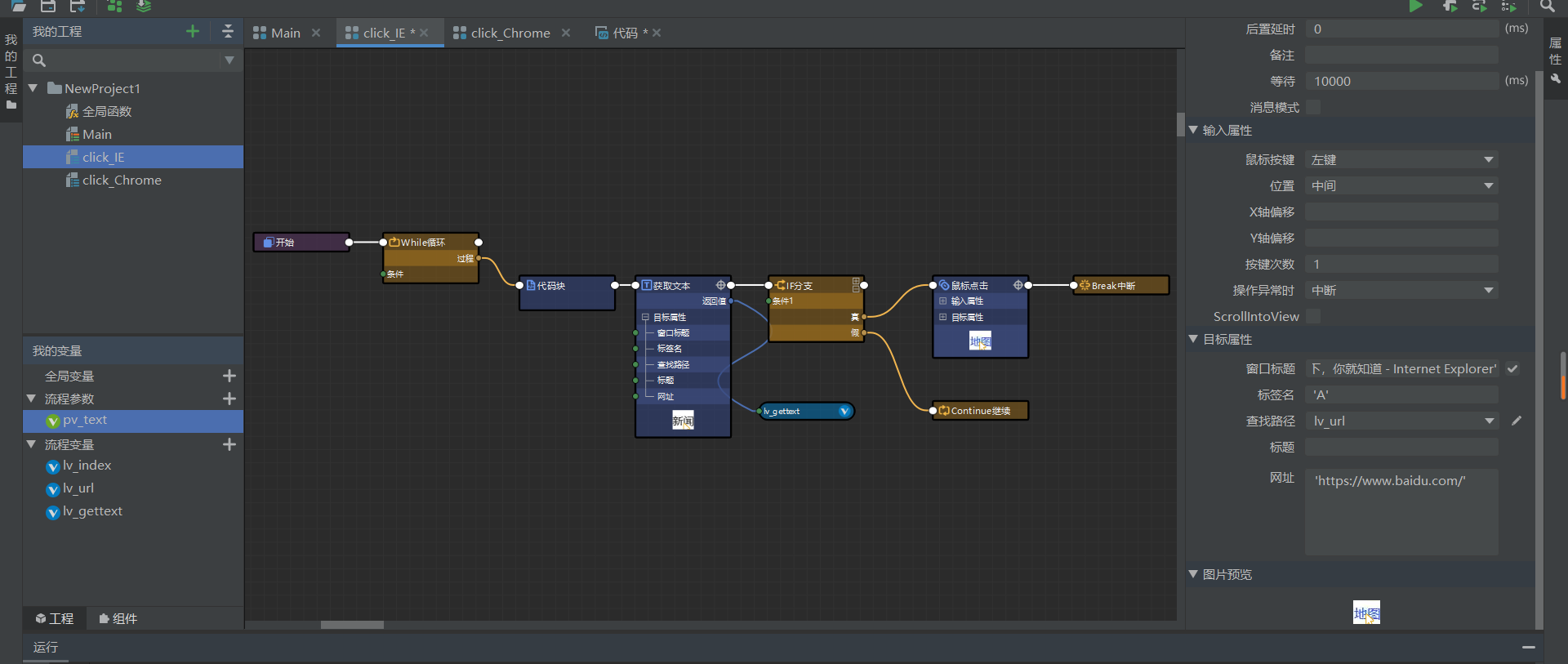
代码块中的代码如下:
'''
lv_index :下标
lv_url :元素的css-selector
'''
lv_index = lv_index + 1
#以下三种方法都可对lv_url的值进行改变
#1.字符串拼接
lv_url = '#s-top-left > A:nth-of-type('+str(lv_index)+')'
#2.格式化字符串
lv_url = '#s-top-left > A:nth-of-type({})'.format(str(lv_index))
#3.占位符
lv_url = '#s-top-left > A:nth-of-type(%s)'%str(lv_index)
四、Chrome 浏览器解题
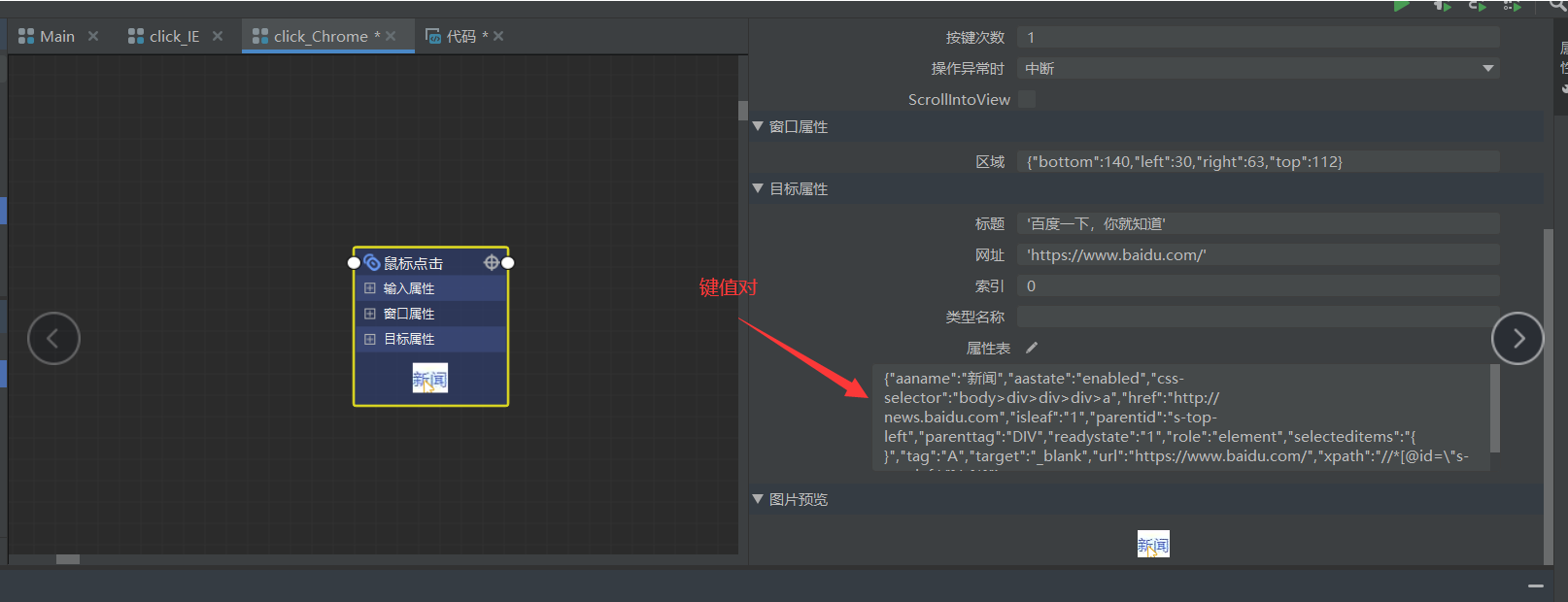
1. 了解 chrome 拾取
chrome 拾取是根据属性表中的键值对对元素进行匹配,我们可以随意的对这些键值对进行编辑,只要这些键值对能匹配到唯一的元素。
2. 巧用 aaname
我们拾取后会发现,属性表中是许多的键值对。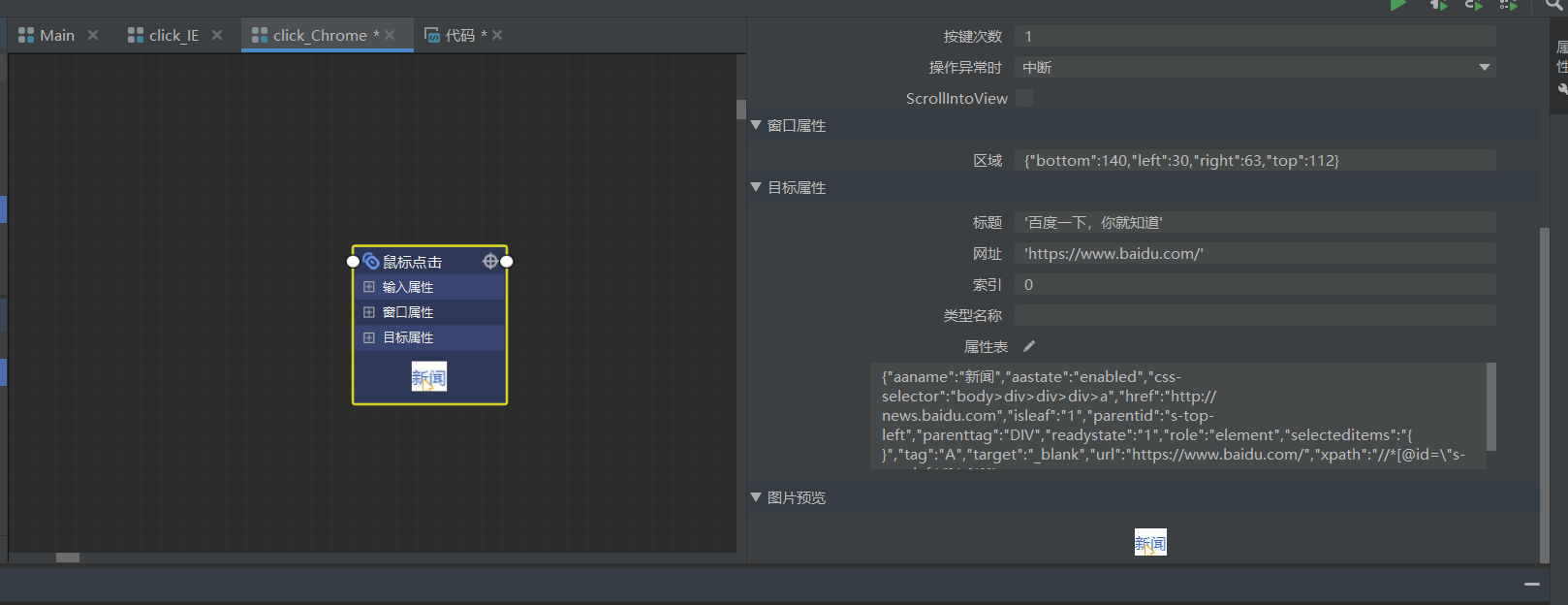
其实不需要这么多键值对,我们可以删除一些,只要我们可以匹配到网页中唯一元素就行。
那么我们把除了 aaname 以外的全部删除,只运行此组件可以成功的点击到我们想要的链接。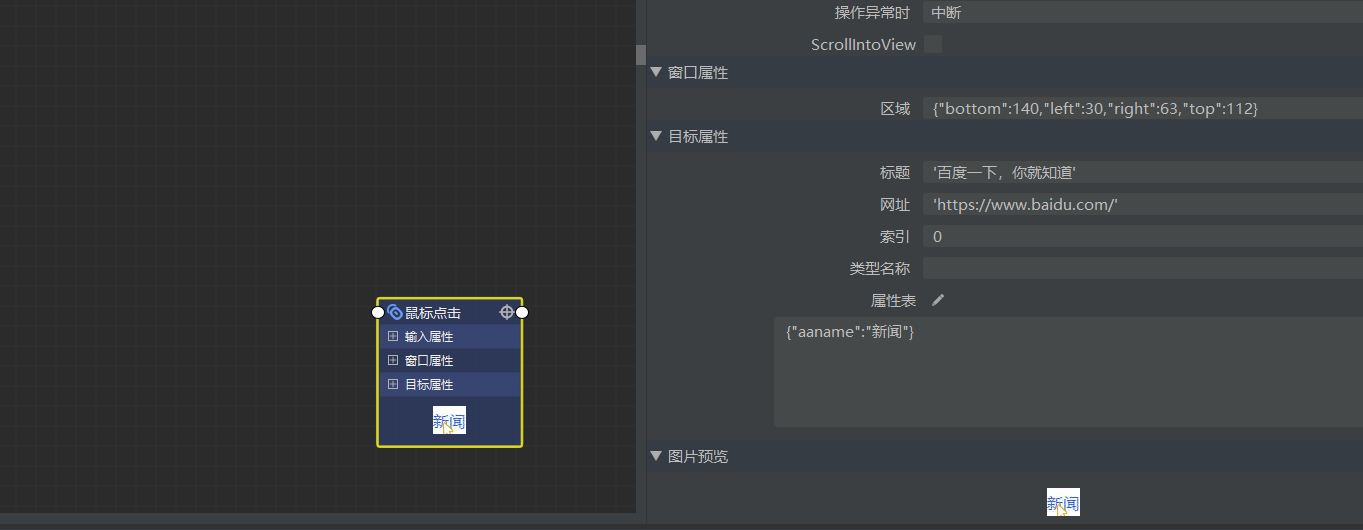
3. 设计流程
我们是根据属性表中 aaname 的 value 匹配,将其设置为流程参数 pv_text,即可根据 pv_text 的值点击我们想要的导航栏链接。
这里我筛选了一些键值对,多一个键值对我们对元素的定位就会更准确,可以根据实际情况进行选择。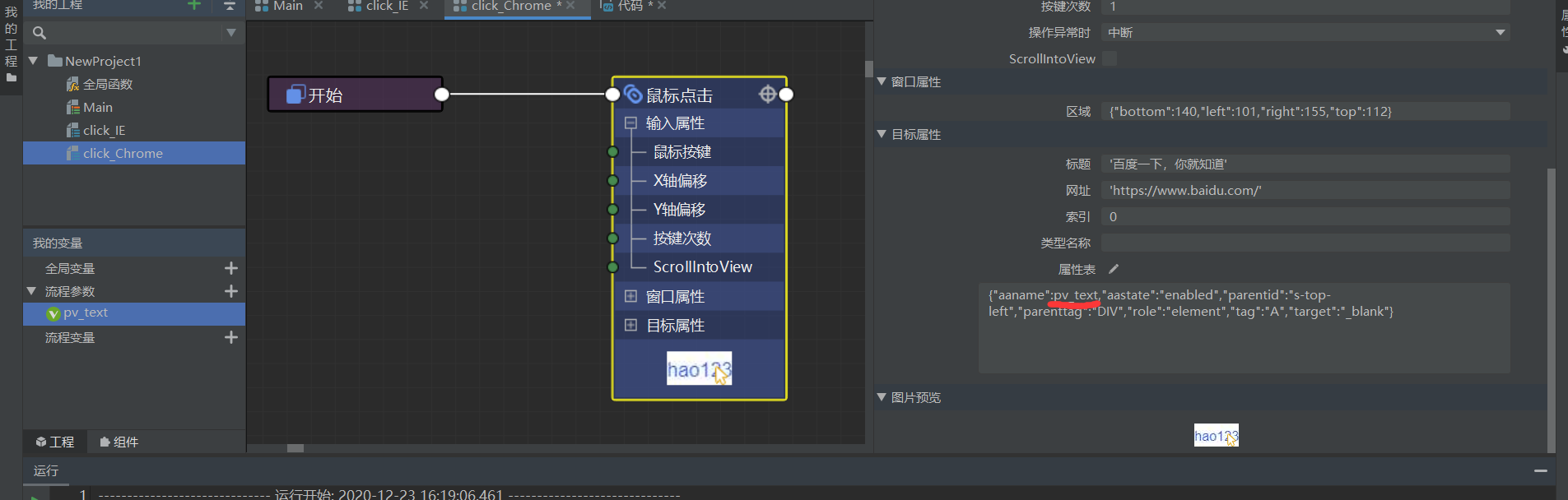
五、总结
通过以上发现,同一道题用 Google 拾取和 IE 拾取解题难度相差非常之大。
所以我们开发项目之前也要先考量用什么浏览器进行开发会更容易实现,这样可以让我们的工作变得更轻松。
活动传送门高手过招第 4 期 高手过招第 4 期:那些你所知道的关于拾取的技巧和经验

他就是
好的,弄好了,感谢您。
这种你选择消息模式运行就行。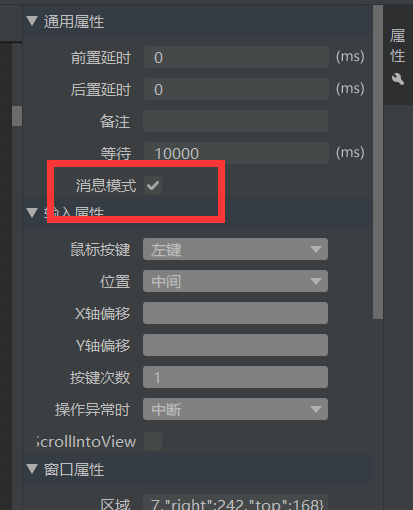
这个 "更多" 应该是设置了 hover,鼠标悬浮在上面才会显示下面的内容,所以没法直接点击。用消息模式可以在后台直接点击。
就是这种组件,鼠标点击可以拾取,但是运行没有反应。
什么意思,我不太明白
想问下 !!后边‘更多’里的组件如何用鼠标点击呢
好评!
啪啪啪啪 ~ 鼓掌!
hhh 我怀疑你是捧哏的
非常的结构化,向你学习! :salute:
研究很深入 👍