

高手过招第 4 期—拾取经验分享
拾取的优势在于,准确性更高:不会受分辨率、窗口缩放的影响,容错率更高;
开发过程前期先对流程开发的涉及软件测试拾取了一遍,发现鼠标点击能够实现,顿时信心就来了(所以希望官方一定把拾取做好呀),下面进入正题。
关于拾取的经验总结
- 设置文本:
当输入框不是 input 类型时,尝试控件输入,依旧不行可以采用模拟按键的方式:鼠标点击使光标定位在输入框,将输入框的值设置为固定值或者变量,利用 TAB 或者方向键切换至下一个输入框,例如:登录时可以用 TAB 切换至密码框输入完成后 ENTER 可以直接登录,注意事项:模拟按键可能出现输入不全的情况,适当的添加前置延迟可以解决。
** 特殊情况:** 当原本的输入框内有值需要删除后重新输入可以先点击输入框,使用模拟按键, 在键值中输入’{END}{DELETE 10}’将原本的值删除(DELETE 按键次数根据实际情况来)再使用正常的模拟按键步骤
- ** 拾取表单 (web):** 只对 table 标签起作用
非 web 表单可以查看软件是否支持导出 EXCEL 格式,如 SAP 支持右键导出表单
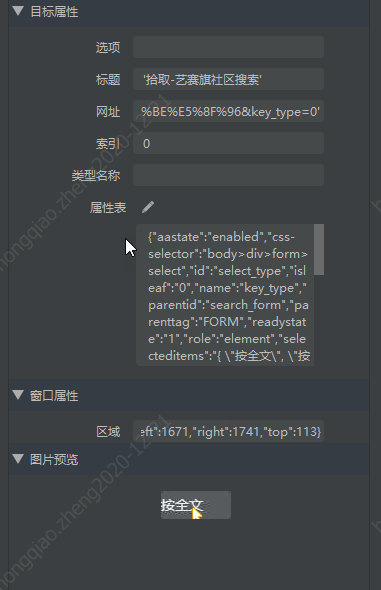
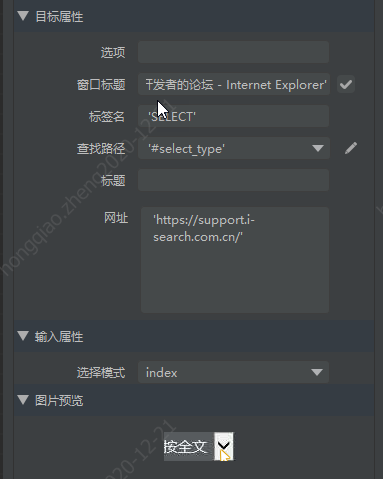
- **SELECT 组件:** 只对 select 标签起作用
对于谷歌浏览器和 IE 浏览器打开的网页,拾取后属性有差别,暂未找到解决办法,能使用 IE 则优先基于 IE 开发
如图,图一为谷歌拾取 select 标签,图二为 IE
- 鼠标点击:
1. 对于无法拾取的控件,鼠标点击就无法发挥作用了,这个时候可以使用 F5 图片识别拾取(也可尝试把所有拾取方式都使用一遍,东边不亮西边亮);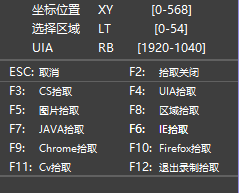
2. 如果只能拾取到周围的控件,目标控件可以采用偏移的方式点击,这样相比直接使用坐标点击准确率更高。
3. 小技巧,关注下是否有快捷键可替代点击操作:例如部分软件的二级菜单可以通过按键操作,转换为模拟按键操作效果更佳,如下图按下对应键等同于鼠标点击
经过几个流程开发,发现对基于.net 开发的软件拾取都非常友好,和网页差不多,
逐行点击目录:
如果需要逐个对当前列表进行点击,如果数量多会导致流程冗长,可以采用循环加偏移点击的方式
步骤1:通过获取控件HTML组件得到当前所需点击标题的数量(通过分析相同标签数量)
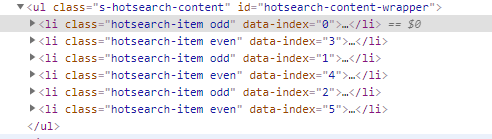
ls = soup.find_all('li',class_='hotsearch-item') #获取标题目录
self.NUMofIT30=len(ls)
如上代码,每个标题都有一个li元素,且对应的class为'hotsearch-item',因此通过如下特征找出所有对应的值存储到容器中,容器的尺寸就是所需点击的标题个数即循环次数
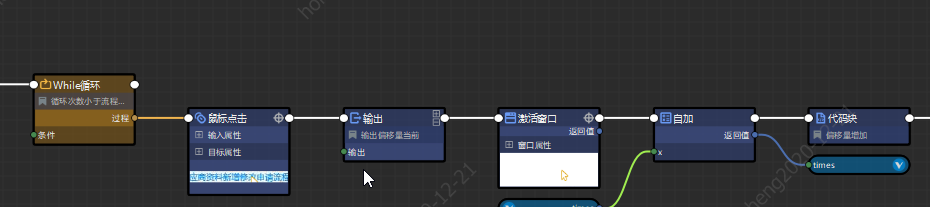
步骤2:while 当前次数n
< 需循环总次数 在循环体内进行点击操作,为鼠标点击属性设置偏移量
在点击操作组件后
设置变量当前次数n自加,
偏移量增加两个标题间的坐标差值(上下两个标题的Y轴距离)
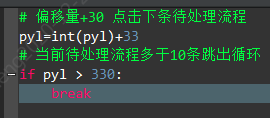
步骤3:在循环体内加入需要对跳转子网页进行的操作(如获取文本、获取HTML、获取表格等等),最后使用激活窗口回到目录页,以便进入下一次循环

希望软件方在拾取方下大功能,不好用。
回帖内容已被屏蔽。
高质量帖子,收获满满
能拾取?开心!
不能?!难受得发燥!
对对对,做流程开发的时候发现能拾取到的时候特别开心