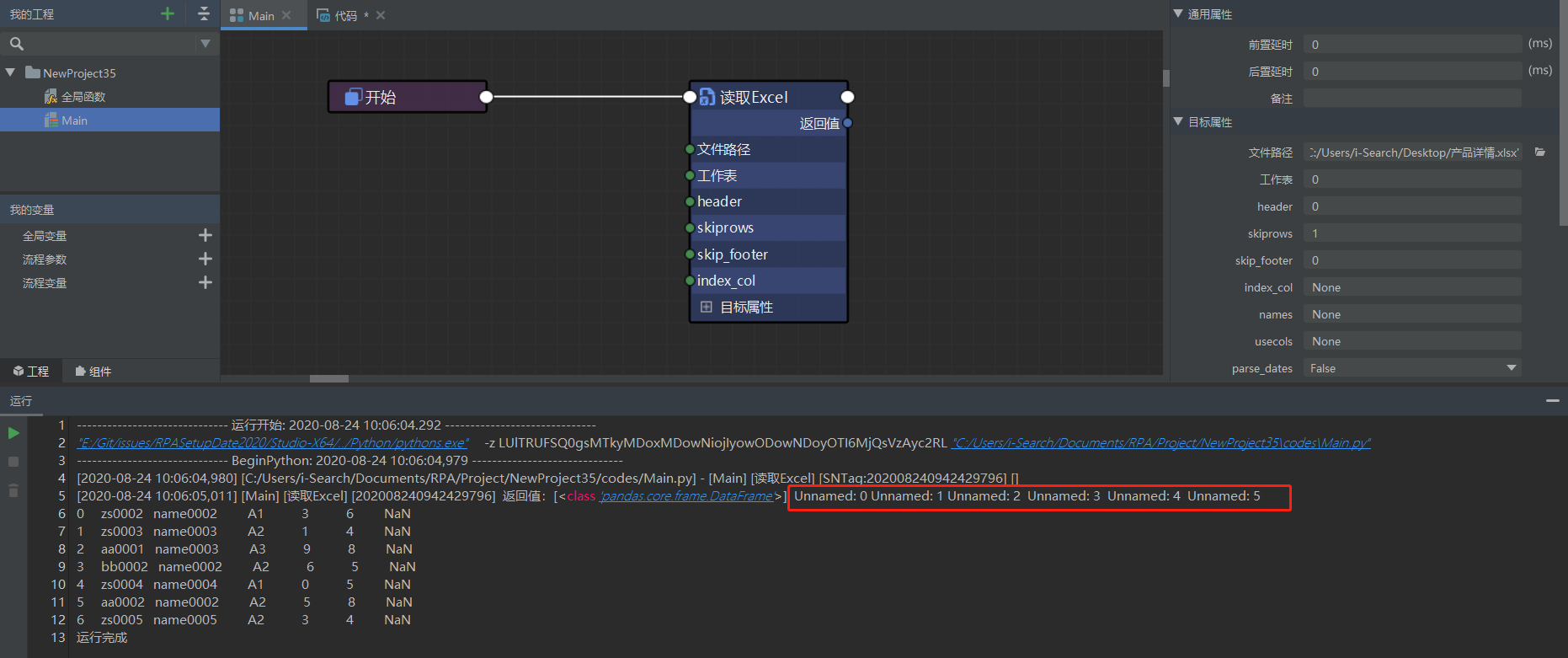
"读取 excel 文本格式: 标题占两行,合并并居中 控件:header:0 skiprows:1 这样获取 header 就会获取不到"
读取 excel文本格式: 标题占两行,合并并居中控件:header:0skiprows:1这样获取 header 就会获取不到
https://www.cnblogs.com/guxingy/p/13070489.html
可以先用 Python 代码把 excel 的合并单元格拆了,这样后续好处理。
你看我设置的和描述的是不是一致的
将合并居中的两行设置为向上对齐,应该更直观些:
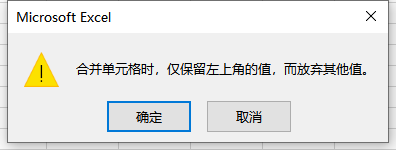
以第一行与第二行合并居中为例,两行仅保留了左上角单元格的值而放弃了其他值,也就是说只保留了 A1 的值,其他单元格的值都作单元格处理
所以这种情况下,默认参数 header=0,skiprows=None 读取到数据中表头只有第一个单元格,其他都是 Unnamed,而第二行都为 NaN:
而你设置参数的情况是 header=0,skiprows=1,所以事先会跳过一行,也就是跳过第一行,以第二行(均为 NaN 的一行)为表头:



https://www.cnblogs.com/guxingy/p/13070489.html
可以先用 Python 代码把 excel 的合并单元格拆了,这样后续好处理。
你看我设置的和描述的是不是一致的
将合并居中的两行设置为向上对齐,应该更直观些:
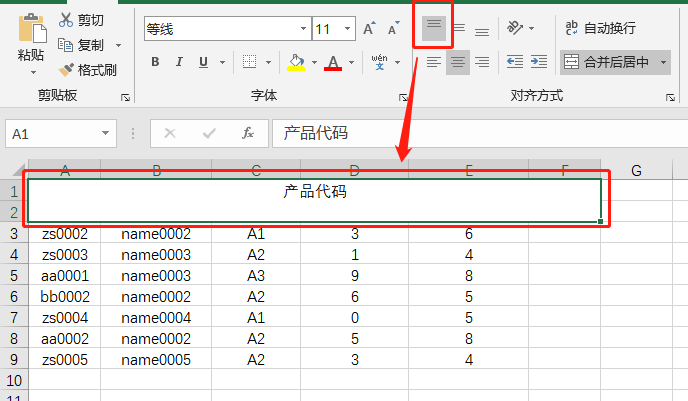
以第一行与第二行合并居中为例,两行仅保留了左上角单元格的值而放弃了其他值,也就是说只保留了 A1 的值,其他单元格的值都作单元格处理
所以这种情况下,默认参数 header=0,skiprows=None 读取到数据中表头只有第一个单元格,其他都是 Unnamed,而第二行都为 NaN:
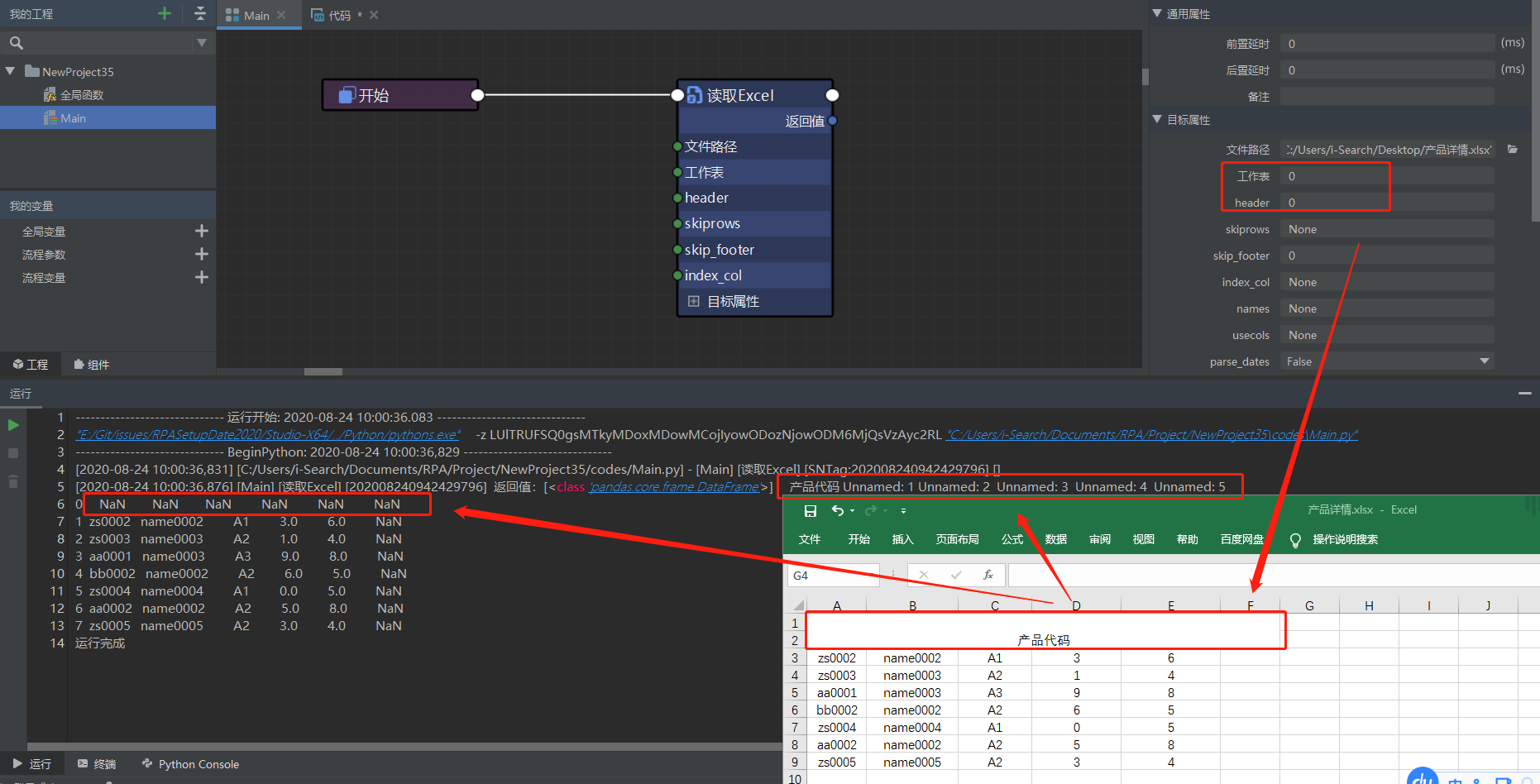
而你设置参数的情况是 header=0,skiprows=1,所以事先会跳过一行,也就是跳过第一行,以第二行(均为 NaN 的一行)为表头: