


Python 批量提取 docx 格式 Word 文档中所有批注
功能描述:
提取 docx 格式 Word 文档中所有批注。
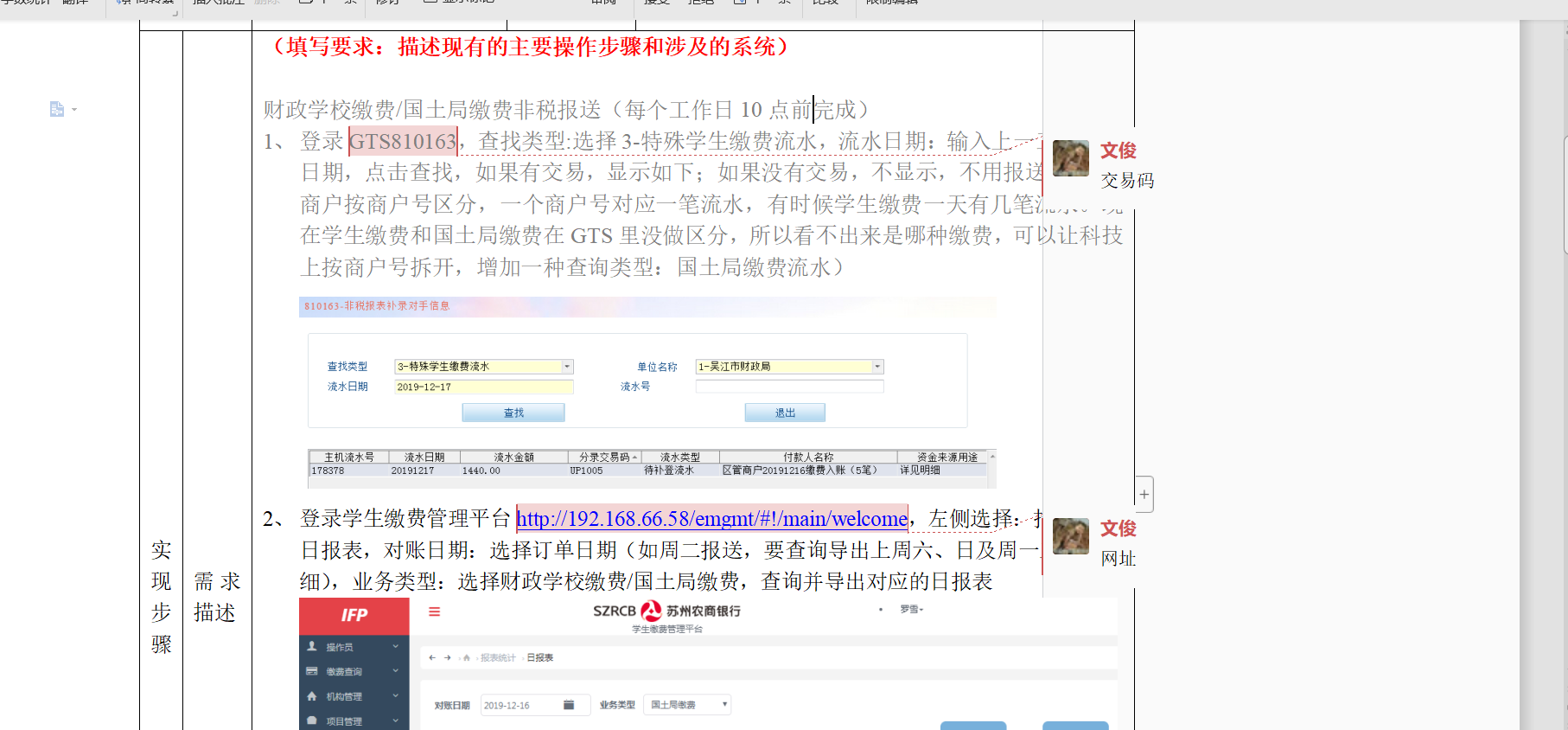
from zipfile import ZipFile
from re import findall
fn = r"带批注的测试文件.docx"
with ZipFile(fn) as fp:
try:
content = fp.read("word/comments.xml").decode("utf-8")
except:
content = ''
if not content:
print("这个文档没有批注")
else:
for comment in findall(r"<w:t>(.*?)</w:t>", content):
print(comment)
运行结果:
交易码
网址

评审的用户名及回复啥的可以么 😆