
wangwei


机器学习, 数据采集, 数据分析, web网站,IS-RPA,APP
其他经验 案例分享 Hadoop生态圈 分组聚合 • 1 回帖 • 1.2K 浏览 • 2019-11-29 11:38:16
机器学习, 数据采集, 数据分析, web网站,IS-RPA,APP
其他经验 案例分享 Hadoop生态圈 分组聚合 • 1 回帖 • 1.2K 浏览 • 2019-11-29 11:38:16
经验 | Hadoop 生态圈 - 分组聚合
原文:https://www.yuque.com/htqmz8/zxoy13/mbgau7
Hadoop 生态圈即全部组件 - 原创 wangwei(qq 邮箱:1040691703@qq.com) 转载复制请联系作者
1、本地模式运行结果:

res4: Array[(String, Int)] = Array((Hello,4), (Content,1), (1040691703@qq.com,1), (wangwei,3), (IS-RPA,1), (Hadoop,2))
2、编写代码运行:
pom 文件:
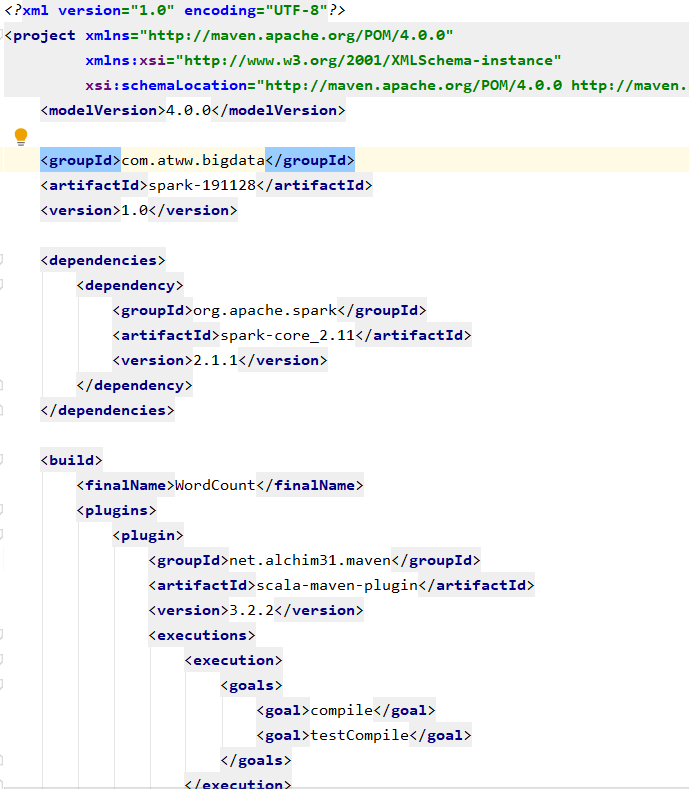

测试文件

代码运行
object WordCount {
def main(args: Array[String]): Unit = {
val config:SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建上下文对象(sc)
val sc = new SparkContext(config)
println(sc)
// 读取文件
val lines: RDD[String] = sc.textFile("input")
val words: RDD[String] = lines.flatMap(_.split(" "))
val wordToOne: RDD[(String,Int)] = words.map( (_,1) ) // (String,Int):key val对
val wordToSum: RDD[(String,Int)] = wordToOne.reduceByKey(_+_)
val result: Array[(String,Int)] = wordToSum.collect()
// println(result) // 结果:[Lscala.Tuple2;@f446158
result.foreach(println)
}
代码运行结果
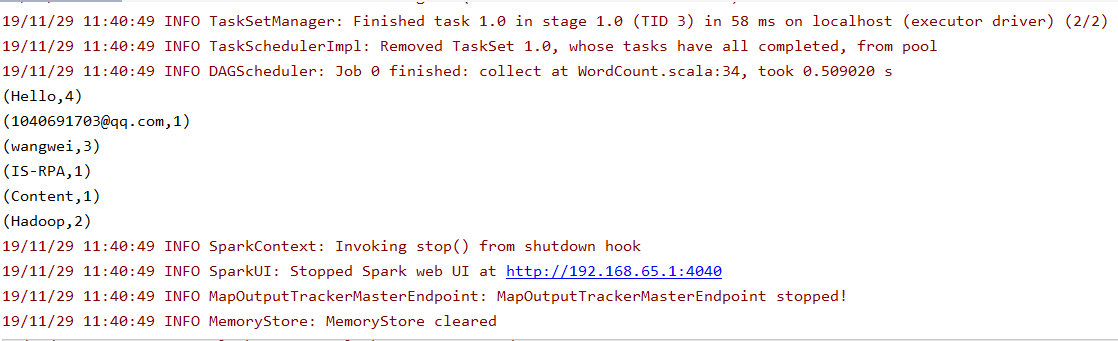
(Hello,4)
(1040691703@qq.com,1)
(wangwei,3)
(IS-RPA,1)
(Content,1)
(Hadoop,2)
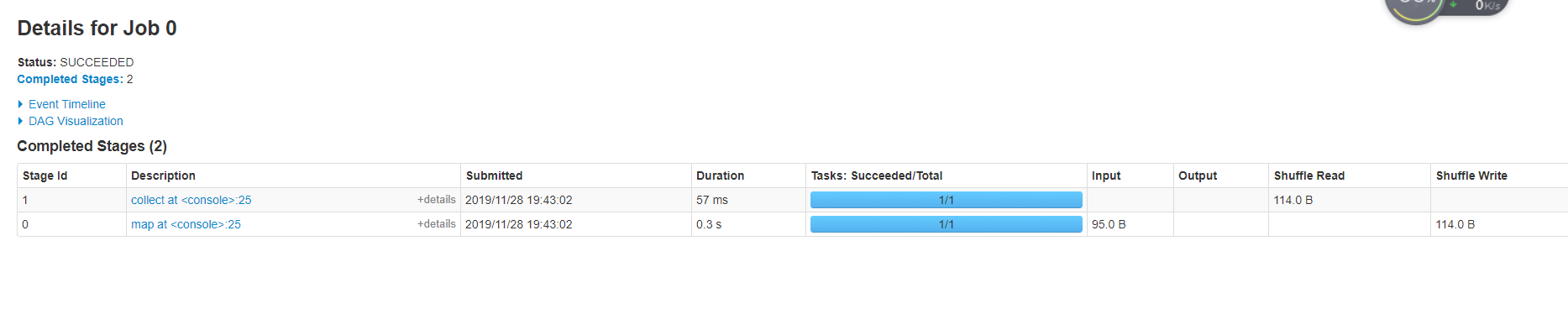
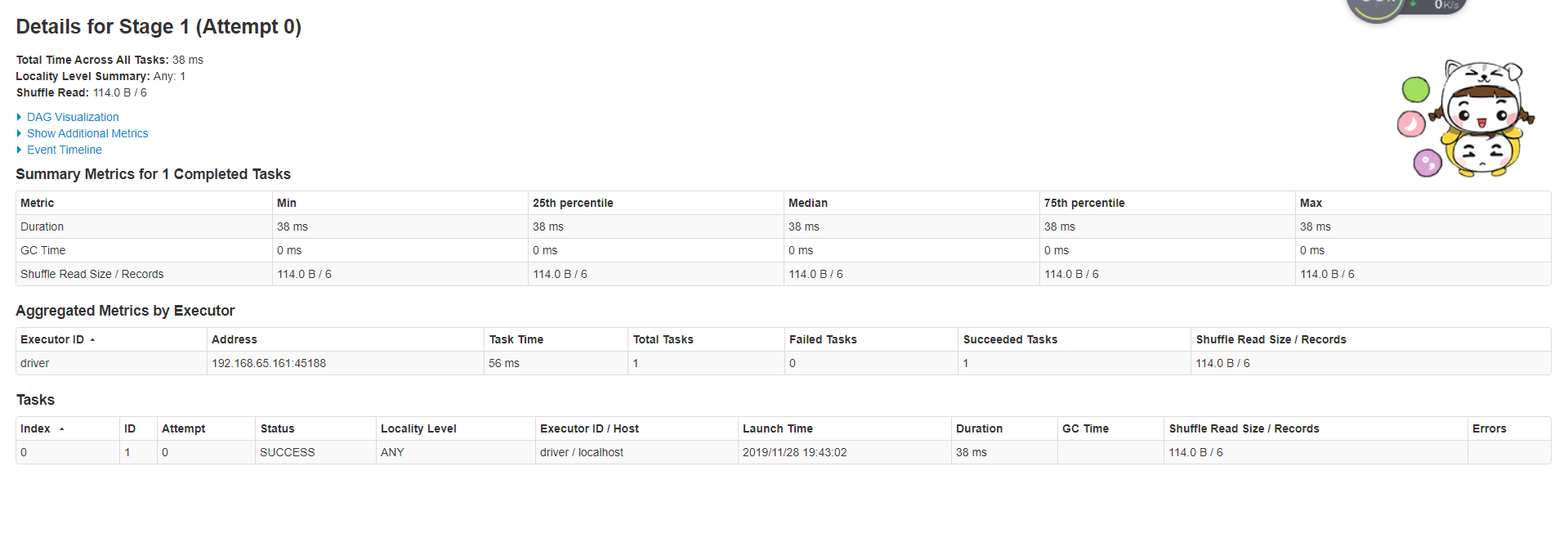
web 浏览

这个必须点赞👍