


Hadoop 生态圈 - 完全分布式
Hadoop 完全分布式 - 王伟
Hadoop 生态圈即全部组建 - 原创 wnagwei(qq:140691703@qq.com) 转载复制请联系作者,未经允许擅自操作,将追究法律责任
原文: https://www.yuque.com/htqmz8/zxoy13/mbgau7
完全分布式运行模式(开发重点)
分析:
1)准备 3 台客户机(关闭防火墙、静态 ip、主机名称)
2)安装 JDK
3)配置环境变量
4)安装 Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置 ssh
9)群起并测试集群
环境:
镜像文件:CentOS7.4
三台主机:HOSTNAME 静态 IP
master1 192.168.65.161
slave1 192.168.65.162
slave2 192.168.65.163
第一章、 虚拟机准备
1.1、虚机准备 - 详见 伪分布式。
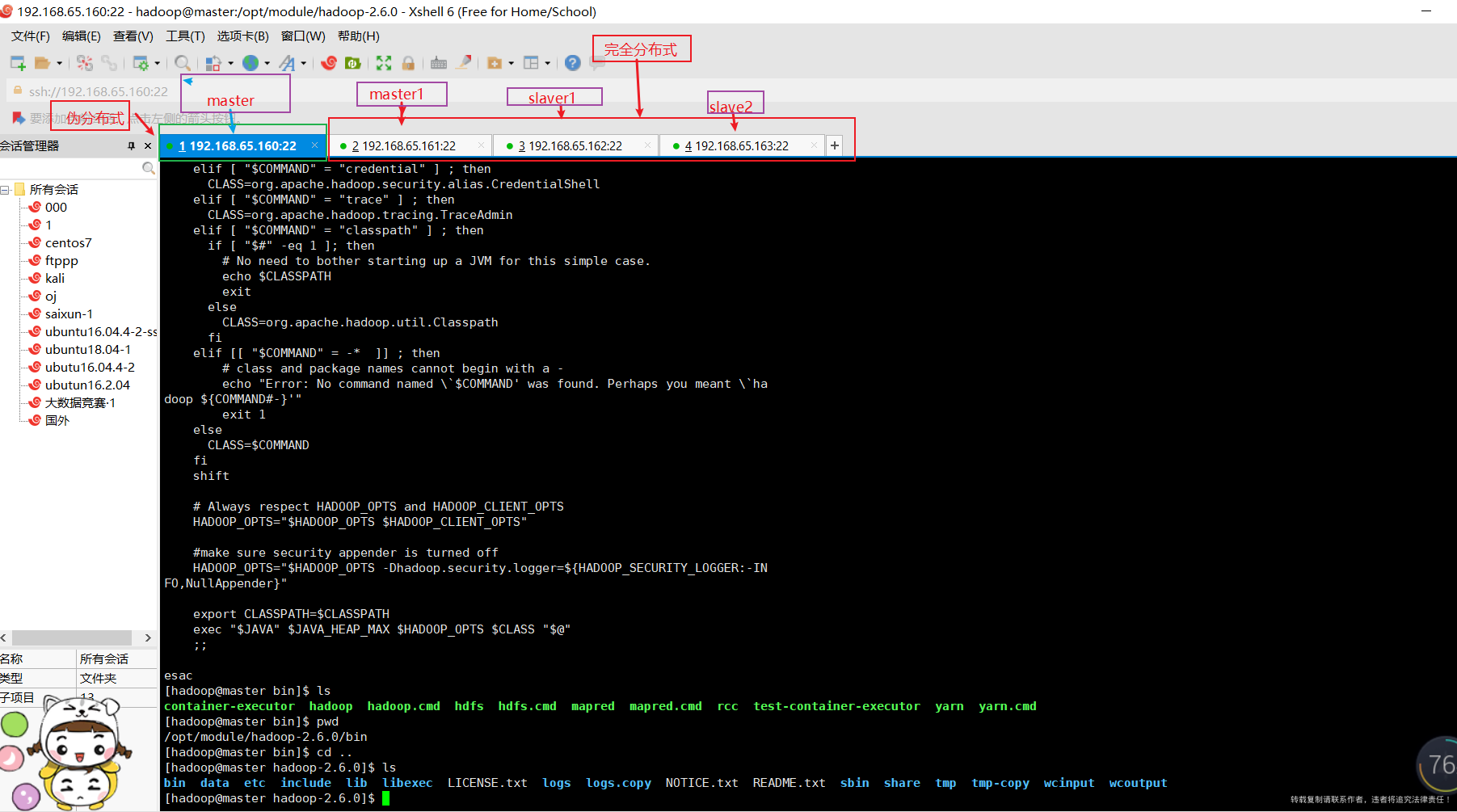
1.2、另外三台机子,也创建 hadoop 用户,
详见 伪分布式里面 创建用户,密码全是:123456
第二章、 编写集群分发脚本 xsync
2.1、 scp(secure copy)安全拷贝
(1)scp 定义:
scp 可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件路径 / 名称 目的用户 @主机: 目的路径 / 名称
(3)案例实操

- (a)在 master上,将 master 中 /opt/module目录下的软件拷贝到 master1 上。
[hadoop@master hadoop-2.6.0]$ scp -r /opt/module root@master1:/opt/module
- (b)在master上**,将master服务器上的 /opt/module 目录下的软件拷贝到 slave1 上。**
[hadoop@master hadoop-2.6.0]$ scp -r /opt/module root@slave1:/opt/module
- (c)在master上,将master服务器上中 /opt/module 目录下的软件拷贝到slave2**** 上。
hadoop@master hadoop-2.6.0]$ scp -r /opt/module root@slave2:/opt/module
- (d)将 master 中 /etc/profile文件拷贝到 master1**** 的 /etc/profile 上。
hadoop@master hadoop-2.6.0]$ sudo scp /etc/profile root@master1:/etc/profile
- (e)将master中 /etc/profile文件拷贝到 slave1**** 的 /etc/profile 上。
hadoop@master hadoop-2.6.0]$ sudo scp /etc/profile root@slave1:/etc/profile
- (f)将master中 /etc/profile文件拷贝到 slave2**** 的 /etc/profile 上。
hadoop@master hadoop-2.6.0]$ sudo scp /etc/profile root@slave2:/etc/profile
2.2、 rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更新。scp 是把所有文件都复制过去。
(1)基本语法
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径 / 名称 目的用户 @主机: 目的路径 / 名称
选项参数说明
表 2-2
|
选项
|
功能
|
|
-r
|
递归
|
|
-v
|
显示复制过程
|
|
-l
|
拷贝符号连接
|
(2)案例实操
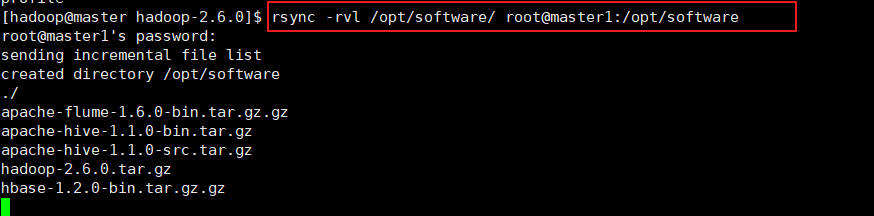
(a)把 master 机器上的 /opt/software 目录同步到 master1 服务器的 root 用户下的 /opt/ 目录
hadoop@master hadoop-2.6.0]$ rsync -rvl /opt/software/ root@master1:/opt/software
2.3、 xsync 集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
- rsync**** 命令原始拷贝:
rsync -rvl /opt/module root@slave1:/opt/
(3)脚本实现
[hadoop@master1 ~]$ pwd [hadoop@master1 ~]$ mkdir bin [hadoop@master1 ~]$ cd bin/ [hadoop@master1 bin]$ touch xsync [hadoop@master1 bin]$ vim xsync
在该文件中编写如下代码 shell 脚本代码
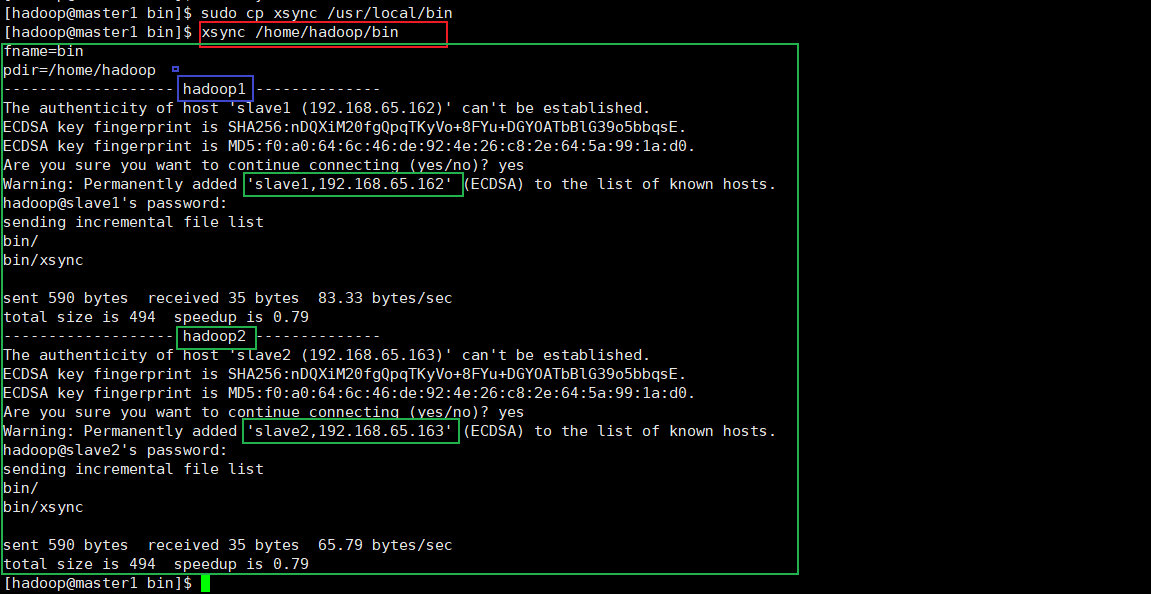
- (b)修改脚本 xsync 具有执行权限
[hadoop@master1 bin]$ chmod 777 xsync
- (c)调用脚本形式:xsync 文件名称
[hadoop@master1 bin]$ xsync /home/hadoop/bin
第三章、集群配置
3.1、集群部署规划
表 2-3
|
|
master1
|
slave1
|
slave2
|
|
HDFS
|
NameNode
DataNode
|
DataNode
|
SecondaryNameNode
DataNode
|
|
YARN
|
NodeManager
|
ResourceManager
NodeManager
|
NodeManager
|
|
IP
|
192.168.65.161
|
192.168.65.162
|
192.168.65.163
|
3.2、配置集群
所有 core-site.xml.copy-master 为伪分布式配置的(多了日志和历史服务器 web 地址)
(1)核心配置文件
- 配置 ****core-site.xml
[hadoop@master1 hadoop-2.6.0]$ cd etc/hadoop [hadoop@master1 hadoop]$ vim core-site.xml
在该文件中修改编写为如下配置:
<property> <name> fs.default.name </name> <value>hdfs://master1:9000</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.6.0/data/tmp</value> <description>指定Hadoop运行时产生文件的存储目录</description> </property>
(2)HDFS 配置文件
- 1、配置 hadoop-env.sh
[hadoop@master1 hadoop]$ vim hadoop-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_171
- 2、配置 hdfs-site.xml
[hadoop@master1 hadoop]$ vim hdfs-site.xml
在该文件中编写修改为 **** 如下配置:
<property> <name>dfs.replication</name> <value>3</value> <description></description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave1:50090</value> </property>
(3)YARN 配置文件
- 1、配置 yarn-env.sh
[hadoop@master1 hadoop]$ vim yarn-env.sh # 底端增加如下内容:(已增加则略过) export JAVA_HOME=/opt/module/jdk1.8.0_171
- 2、配置 yarn-site.xml
[hadoop@master1 hadoop]$ cp yarn-site.xml yarn-site.xml.copy-master #伪分布式写的 [hadoop@master1 hadoop]$ vim yarn-site.xml
在该文件中修改为如下配置:
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>slave1</value> <description></description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description></description> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> <description></description> </property>
(4)MapReduce 配置文件
- 1、配置 mapred-env.sh
[hadoop@master1 hadoop]$ vim mapred-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_171
- 2、配置 mapred-site.xml
[hadoop@master1 hadoop]$ cp mapred-site.xml mapred-site.xml.copy-master #伪分布式写的 [hadoop@master1 hadoop]$ vim mapred-site.xml
在该文件中增加如下配置:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
3.3、在集群上分发配置好的 Hadoop 配置文件
[hadoop@master1 hadoop]$ xsync /opt/module/hadoop-2.6.0/

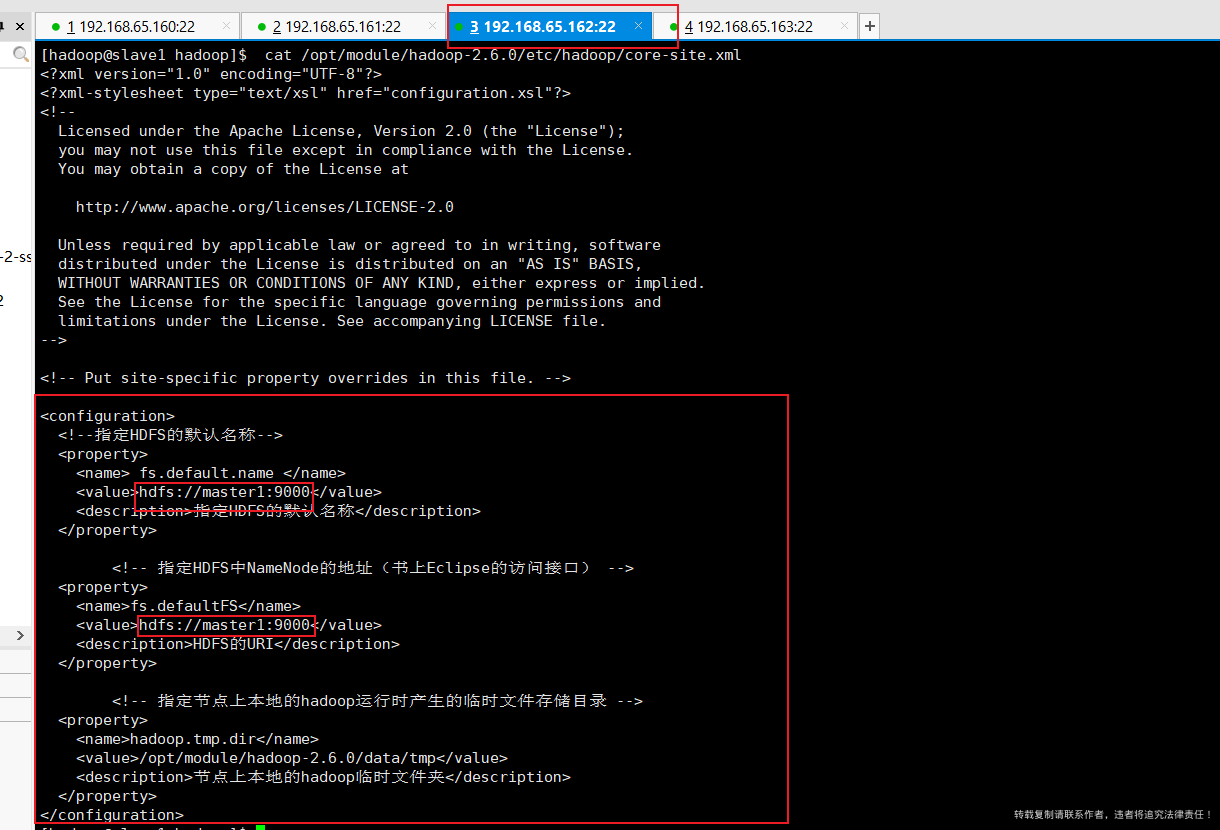
3.4、从机查看文件分发情况
[hadoop@slave1 hadoop]$ cat /opt/module/hadoop-2.6.0/etc/hadoop/core-site.xml [hadoop@slave2 hadoop]$ cat /opt/module/hadoop-2.6.0/etc/hadoop/core-site.xml
第四章、 集群单点启动
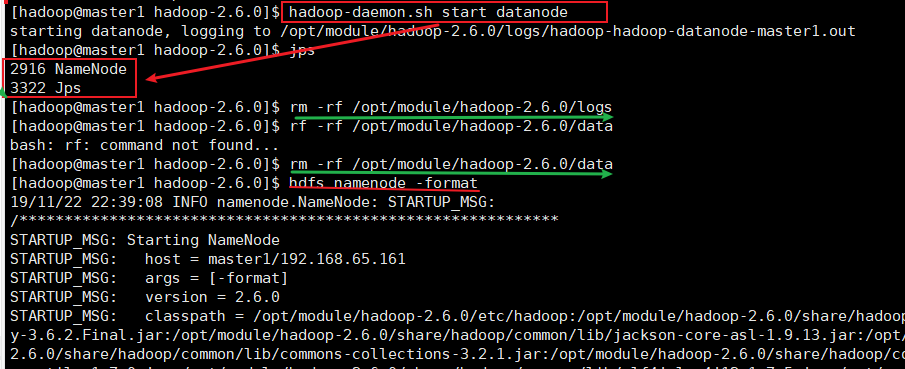
4.1、如果集群是第一次启动,需要格式化 NameNode
[hadoop@master1 hadoop-2.6.0]$ hadoop namenode -format
4.2、在 hadoop102 上启动 NameNode
[hadoop@master1 hadoop-2.6.0]$ hadoop-daemon.sh start namenode [hadoop@master1 hadoop-2.6.0]$jps 2916 NameNode 2990 jps

4.3、在 master1、slave1 以及 slave2 上分别启动 DataNode
[hadoop@master1 hadoop-2.6.0]$ hadoop-daemon.sh start datanode [hadoop@master1 hadoop-2.6.0]$ jps 3461 NameNode 3608 Jps 3561 DataNode [hadoop@slave1 hadoop-2.6.0]$ hadoop-daemon.sh start datanode [hadoop@slave1 hadoop-2.6.0]$ jps 3190 DataNode 3279 Jps [hadoop@slave2 hadoop-2.6.0]$ hadoop-daemon.sh start datanode [hadoop@slave2 hadoop-2.6.0]$ jps 3237 Jps 3163 DataNode


第五章、 SSH 无密登录配置
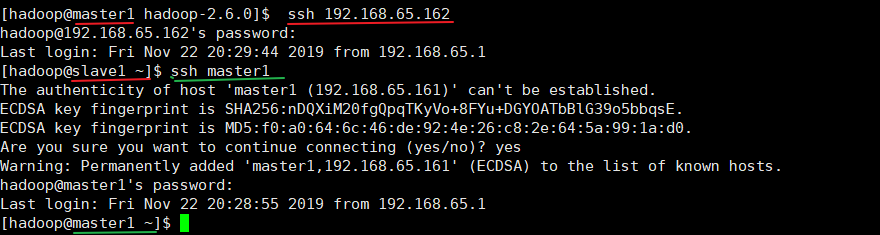
5.1、配置 ssh
(1)基本语法
ssh 另一台电脑的 ip 地址。
虚拟机直接可以 ssh ip/hostname:
ssh 192.168.65.161
ssh slave1
5.2、 无密钥配置
(1)生成公钥和私钥:
[hadoop@master1 .ssh]$ ssh-keygen -t rsa # 然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)

然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
(2)将公钥拷贝到要免密登录的目标机器上
5.2、.ssh 文件夹下(~/.ssh)的文件功能解释
|
known_hosts
|
记录 ssh 访问过计算机的公钥 (public key)
|
|
id_rsa
|
生成的私钥
|
|
id_rsa.pub
|
生成的公钥
|
|
authorized_keys
|
存放授权过得无密登录服务器公钥
|
第六章、 群起集群
6.1、 配置 slaves
slaves 文件作用:
作用:
Hadoop 集群中所有的 DataNode 节点都需要写入 slaves 文件中,因为它是用来指定存储数据的节点文件,Master 会读取 slaves 文件来回去存储信息,根据 slaves 文件来做资源平衡。
也就是说 DataNode、NodeManager 决定于:slaves 文件。谁跑 dataNode,slaves 文件写谁。当 namenode 跑的时候,会通过配置文件开始扫描 slaves 文件,slaves 文件有谁,谁启动 dataNode。当启动 yarn 时,会通过扫描配置文件开始扫描 slaves 文件,slaves 文件有谁,谁启动 NodeManager
[hadoop@master1 ~]$ cd /opt/module/hadoop-2.6.0/etc/hadoop [hadoop@master1 hadoop]$ vim slaves
** 在该文件中编写如下内容:**
master1 slave1 slave2
PS 注意**:该文件中添加的内容结尾不允许有空格 ****,文件 **** 中不允许有空行。**
同步所有 **** 节点配置文件:
[hadoop@master1 hadoop]$ xsync slaves
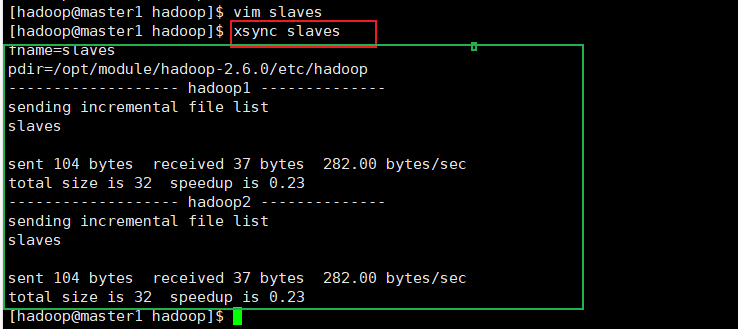
此时,密码都不需要输入,直接分发
6.2、 启动集群
(1)如果集群是第一次启动,需要格式化 NameNode
[hadoop@master1 hadoop]$ bin/hdfs namenode -format
(2)启动 HDFS
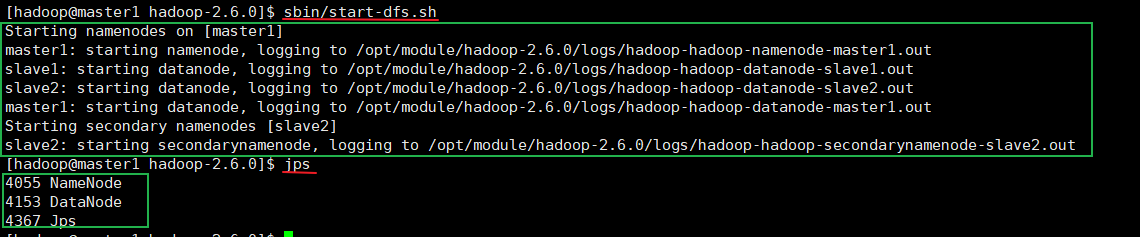
[hadoop@master1 hadoop-2.6.0]$ sbin/start-dfs.sh Starting namenodes on [master1] master1: starting namenode, logging to /opt/module/hadoop-2.6.0/logs/hadoop-hadoop-namenode-master1.out slave1: starting datanode, logging to /opt/module/hadoop-2.6.0/logs/hadoop-hadoop-datanode-slave1.out slave2: starting datanode, logging to /opt/module/hadoop-2.6.0/logs/hadoop-hadoop-datanode-slave2.out master1: starting datanode, logging to /opt/module/hadoop-2.6.0/logs/hadoop-hadoop-datanode-master1.out Starting secondary namenodes [slave2] slave2: starting secondarynamenode, logging to /opt/module/hadoop-2.6.0/logs/hadoop-hadoop-secondarynamenode-slave2.out [hadoop@master1 hadoop-2.6.0]$ jps 4055 NameNode 4153 DataNode 4367 Jps [hadoop@slave1 ~]$ jps 2672 Jps 2542 DataNode [hadoop@slave2 hadoop]$ jps 2944 Jps 2850 SecondaryNameNode 2755 DataNode
(3)启动 YARN
[hadoop@slave1 hadoop-2.6.0]$ sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/module/hadoop-2.6.0/logs/yarn-hadoop-resourcemanager-slave1.out slave2: starting nodemanager, logging to /opt/module/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-slave2.out slave1: starting nodemanager, logging to /opt/module/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-slave1.out [hadoop@slave1 hadoop-2.6.0]$ jps 2897 Jps 2860 NodeManager 2542 DataNode 2766 ResourceManager [hadoop@slave2 hadoop]$ jps 2850 SecondaryNameNode 2755 DataNode 3171 Jps 3048 NodeManager

(4)Web 端查看 SecondaryNameNode
- (a)浏览器中输入查看 SecondaryNameNode 信息,如图 2-41 所示。
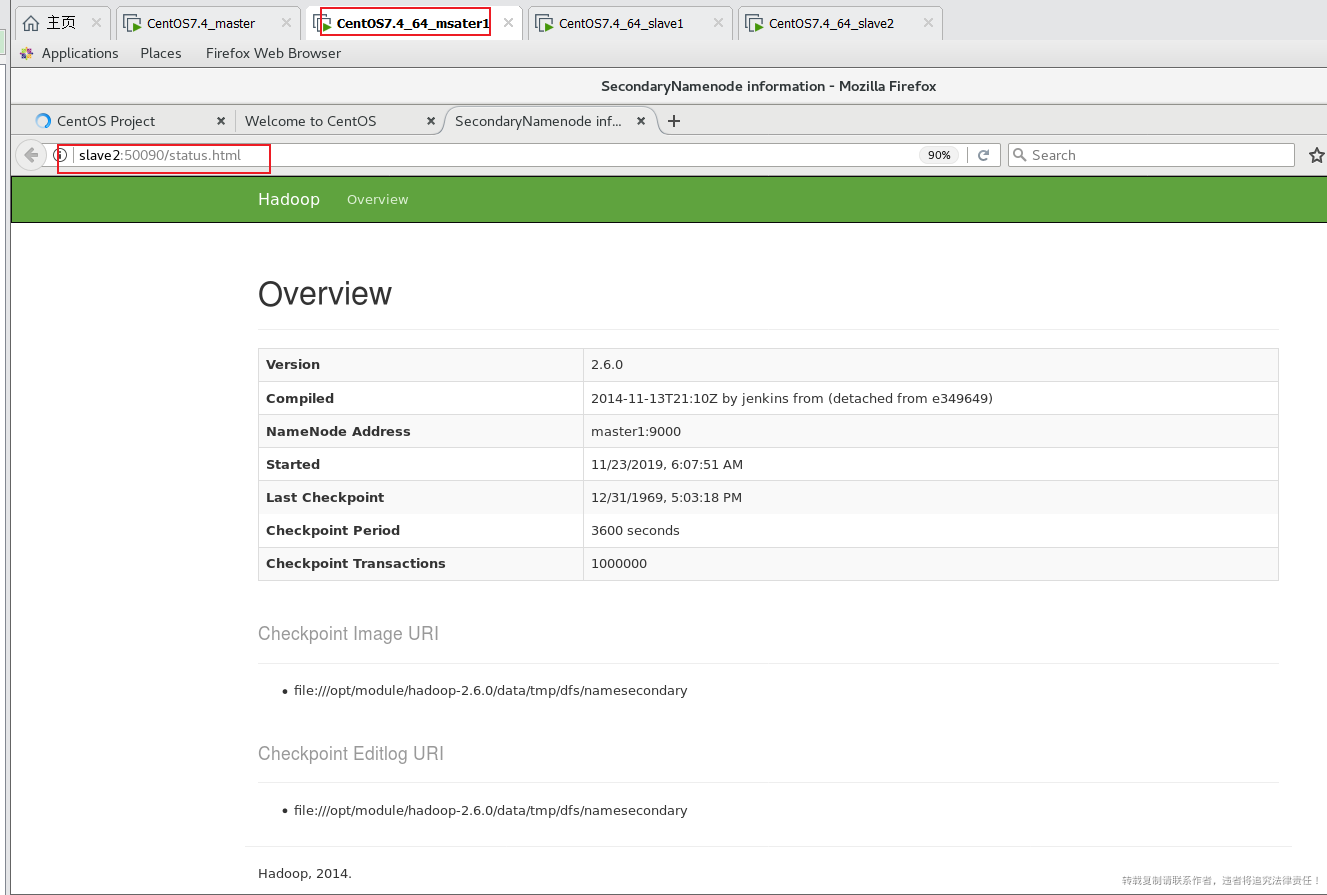
图 2-41 SecondaryNameNode 的 Web 端
6.3、 集群基本测试
(1)上传文件到集群
上传小文件:
[hadoop@master1 hadoop-2.6.0]$ hdfs dfs -mkdir -p /user/hadoop/input [hadoop@master1 hadoop-2.6.0]$ hdfs dfs -put wcinput/wc.input /user/hadoop/input
上传大文件:
[hadoop@master1 hadoop-2.6.0]$ bin/hadoop fs -put /opt/software/hadoop-2.6.0.tar.gz /user/hadoop/input

(2)上传文件后查看文件存放在什么位置
- (a)查看HDFS文件存储路径
[hadoop@master1 subdir0]$ ls blk_1073741825 blk_1073741825_1001.meta blk_1073741826 blk_1073741826_1002.meta blk_1073741827 blk_1073741827_1003.meta [hadoop@master1 subdir0]$ pwd /opt/module/hadoop-2.6.0/data/tmp/dfs/data/current/BP-982474721-192.168.65.161-1574518020089/current/finalized/subdir0/subdir0
/opt/module/hadoop-2.6.0/data/tmp/dfs/data/current/BP-982474721-192.168.65.161-1574518020089/current/finalized/subdir0/subdir0
- (b)查看HDFS在磁盘存储文件内容
[hadoop@master1 subdir0]$ cat blk_1073741825 测试
(3)拼接
[hadoop@master1 subdir0]$ ll total 192188 -rw-rw-r-- 1 hadoop hadoop 7 Nov 23 06:39 blk_1073741825 -rw-rw-r-- 1 hadoop hadoop 11 Nov 23 06:39 blk_1073741825_1001.meta -rw-rw-r-- 1 hadoop hadoop 134217728 Nov 23 06:40 blk_1073741826 -rw-rw-r-- 1 hadoop hadoop 1048583 Nov 23 06:40 blk_1073741826_1002.meta -rw-rw-r-- 1 hadoop hadoop 61039876 Nov 23 06:40 blk_1073741827 -rw-rw-r-- 1 hadoop hadoop 476883 Nov 23 06:40 blk_1073741827_1003.meta [hadoop@master1 subdir0]$ cat blk_1073741826>>tmp.file [hadoop@master1 subdir0]$ cat blk_1073741827>>tmp.file [hadoop@master1 subdir0]$ tar -zxvf tmp.file [hadoop@master1 subdir0]$ rm -rf tmp.file # 太大了,删了算了
(4)下载
[hadoop@master1 hadoop-2.6.0]$ bin/hadoop fs -get /user/hadoop/input/hadoop-2.6.0.tar.gz ./ # 从机也可以下载,很快 [hadoop@slave1 hadoop]$ bin/hadoop fs -get /user/hadoop/input/hadoop-2.6.0.tar.gz ./ [hadoop@slave2 hadoop]$ bin/hadoop fs -get /user/hadoop/input/hadoop-2.6.0.tar.gz ./




用心了老铁,👍