


读取 Excel 的另外两种处理方法
将 Excel 数据读取出来后,组成字典形式:
一、以第一行表头为键,以下内容为字典的值:
如图数据,rpa 处理方法如下: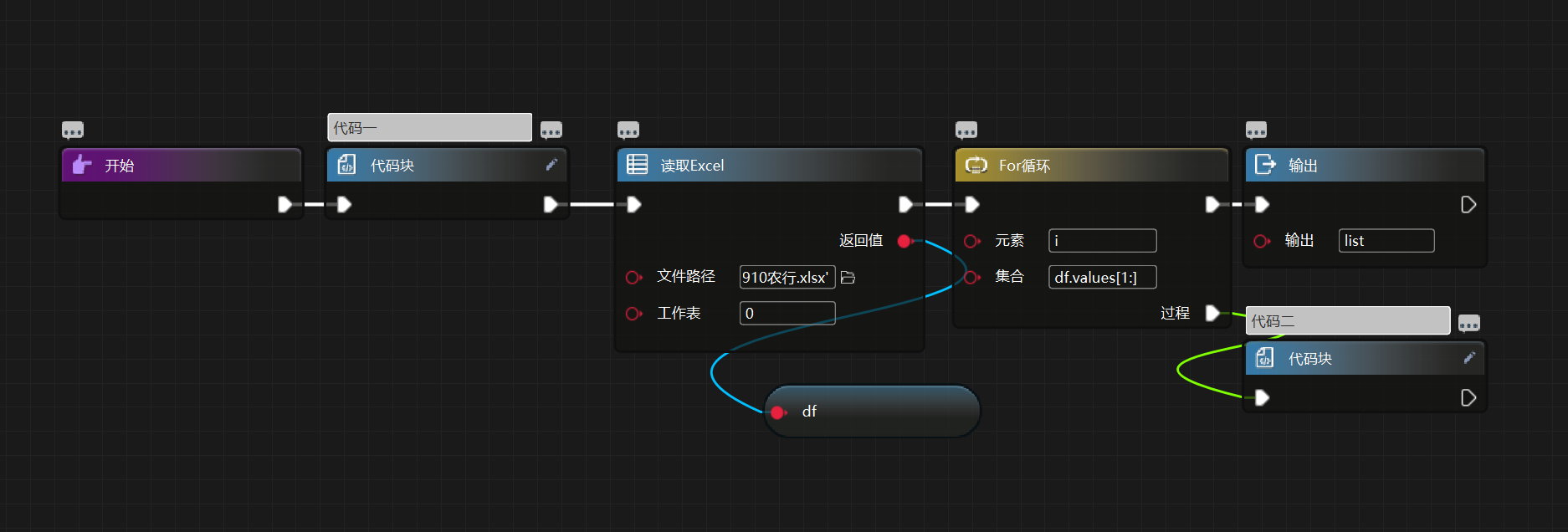
代码一代码为:
list = []
代码二代码为:
dict = {}
for b,value in enumerate(i):
dict[df.values[0][b]] = i[b]
list.append(dict)
1、注意: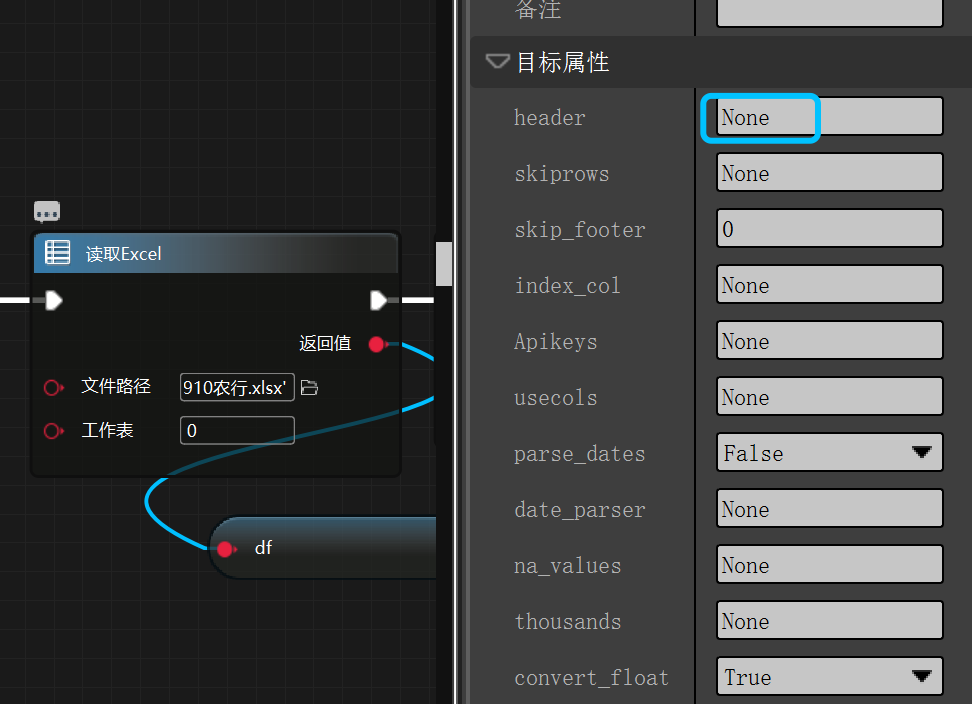
如图所示:需将 header 默认的参数改为“None”
2、好处:
上述流程将Excel的表头作为字典的键,以下内容作为字典的值。最终将字典加入列表中,我们只需循环这个列表,就可从
数据的第二行拿到对应的数据,且对应较清晰。(最后的字典加入列表是为了是数据有序,可以按照从第二行数据开始循
环往下)。
重要的一点,我们可以在原始Excel新增一列判断依据。记录的是我们是否已经处理该条数据,若流程中处理问题,无论是
人工再次点击执行流程还是加了容错处理,使流程自动执行。这里都可以通过新增的判断的这一列。使流程能自己知道上
一次执行未执行的一行数据。
二、将 Excel 中第一列,或其中的几列作为字典的键,其他列作为字典的值
(适用于报税流程中“资产负债表”部分,参照表等文件)
如上图所示数据结构:
rpa 处理方法如下: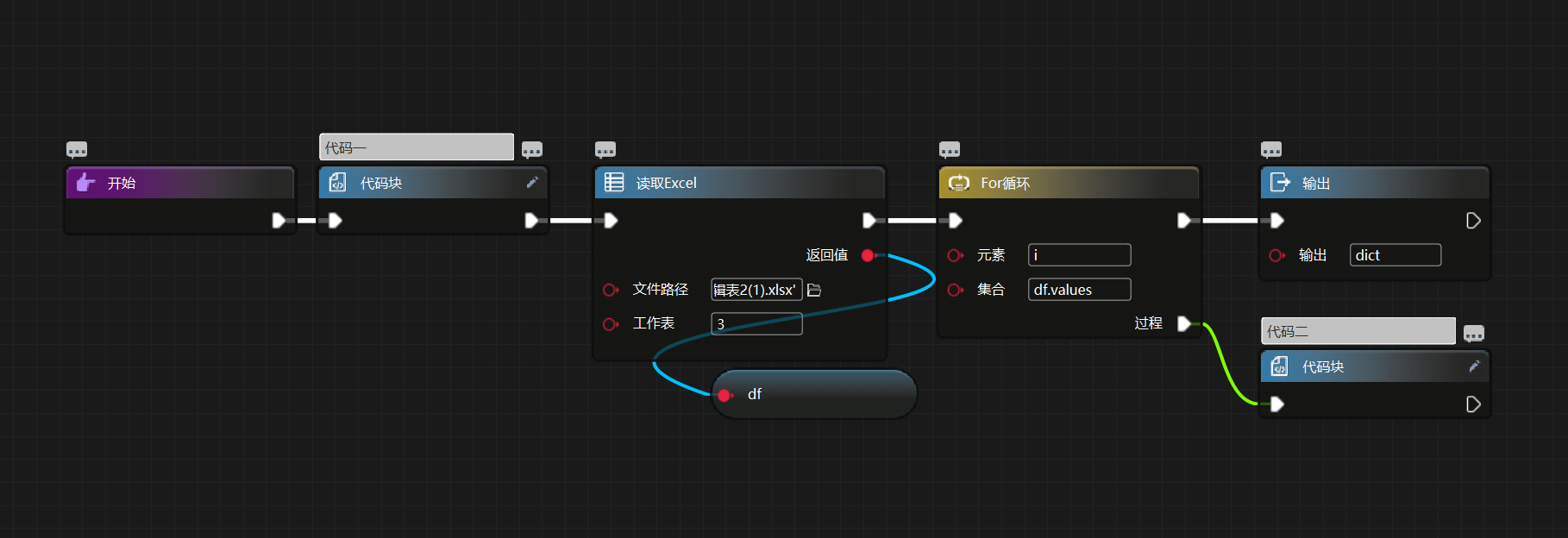
代码一代码为:
dict = {}
代码二代码为:
dict[str(i[0:2])] = i[2:]
# 将前两列作为字典的键,后续的列作为字典的值
1、好处:
例如在循环本帖中,第一个讲的数据的时候,得到商户名,需要加入本次参照表后续的数据时,以写一份新的Excel文件。
使用这样的方法,会发现很便利了。

这个必须点赞👍